【Coursera-ML-Notes】线性回归(上)
什么是机器学习
关于机器学习,有以下两种不同的定义。
机器学习是研究如何使电脑具备学习能力,而不用显式编程告诉它该怎么做。
the field of study that gives computers the ability to learn without being explicitly programmed.
机器学习能够使电脑程序从以往的经验(E)中学习并改善自己,从而在处理新的任务(T)时提升它的性能(P)。
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.
这里针对第二种定义举个例子:下围棋
E:程序模拟人类下很多盘棋所积累的经验
T:下围棋这个任务
P:程序赢得下次比赛的几率
模型表示
假定我们现有一大批数据,包含房屋的面积和对应面积的房价信息,如果我们能得到房屋面积与房屋价格间的关系,那么,给定一个房屋时,我们只要知道其面积,就能大致推测出其价格了。
以这个问题为例,可以建立一个回归模型,首先明确几个常用的数学符号:
输入变量:\(x^{(i)}\),也叫做输入特征,如这个例子中的面积
输出变量:\(y^{(i)}\),也叫做目标变量,如例子中的我们需要预测的房价
训练样本:\((x^{(i)},y^{(i)})\)是输入变量和输出变量称为一组训练样本
训练集(Training set):\(i=1,...,m\),这么多组训练样本构成训练集
假设(hypothesis):也称预测函数,比如例子中可以建立这样一个线性函数:
\[
h_θ(x)=θ_0+θ_1x_1
\]
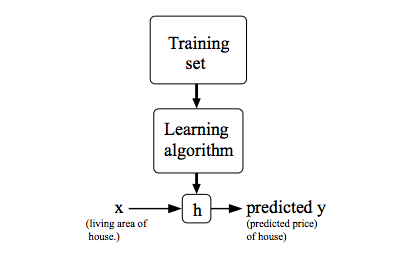
我们的目标是找到满足这样一个线性函数来拟合训练集中的数据,那么,给定一个房屋时,我们只要知道其面积,就能大致推测出其价格了。这个过程可以用下图来表示:

代价函数
有了模型,我们还需要评估模型的准确性。于是代价函数就被引进,它也叫做平方误差函数。
\[
J(\theta_0,\theta_1)=\frac{1}{2m}\sum_{i=1}^m(h_\theta(x^{(i)})-y^{(i)})^2
\]
可以看出,代价函数是采取预测值和真实值差值的平方和取均值的方式来评估数据的拟合程度的,代价函数的值越小,表示模型对于数据的拟合程度越高。
梯度下降
有了模型和评价模型的方式,现在我们要确定模型中的参数\(\theta_0\)和\(\theta_1\),以找到最好的模型。
以\(\theta_0\)为\(x\)轴,\(\theta_1\)为\(y\)轴,代价函数\(J(\theta)\)为\(z\)轴,建立三维坐标系,可以得到如下图所示的图像:
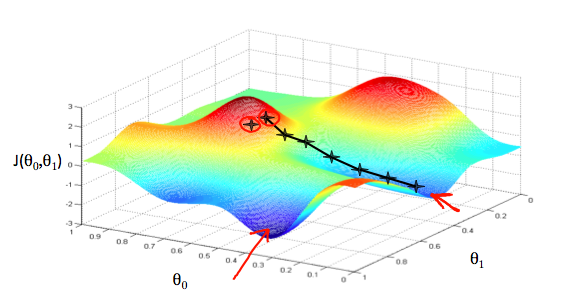
如果把这个图像看作是一座山的话,我们有一个起点\((\theta_0,\theta_1,J(\theta_0,\theta_1))\),现在要从这个点找到一条最快的路径到达山脚下,数学上来说,梯度是最陡峭的方向,所以我们要始终沿着梯度的方向走。
学习率
方向已经确定,但是往这个方向前进的距离是多少呢?这个距离由学习率\(\alpha\)来确定。有了方向和步距,那么\(\theta_0、\theta_1\)的变化规律如下:

那么怎么样确定学习率\(\alpha\)(步距)呢?
如果步距过大,可能接近收敛的时候会越过收敛点,甚至最终无法收敛。
如果步距过小,收敛所花的时间会很久。
所以我们要调节\(\alpha\)的大小,使收敛时间在一个合理的范围里。
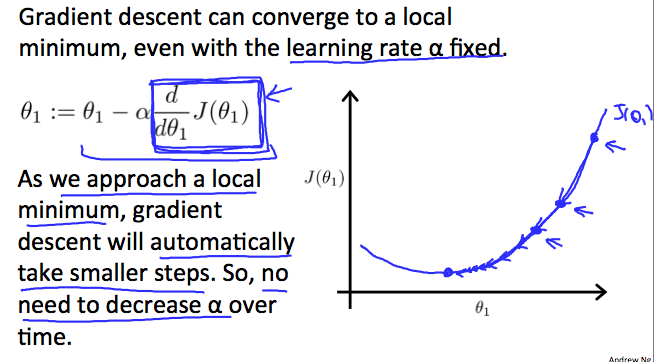
在每一次迭代过程中,需要改变\(\alpha\)的大小吗?如果不需要的话,接近收敛时,会不会因为步距偏大而越过收敛点?
在迭代过程中不需要改变\(\alpha\)的大小,因为接近收敛点时,梯度(斜率)会变小,等价于步距在自动变小,所以没有必要减小\(\alpha\)。
最后,为什么代价函数的表达式中为什么取均值的除数是\(2m\)而不是\(m\)?
我们来看一看参数每一次的迭代过程都发生了什么?
\[
\begin{equation}
θ_0:=θ_0-a\frac{∂}{∂θ_0}J(θ_0,θ_1)
\end{equation}
\]
对上式化简,
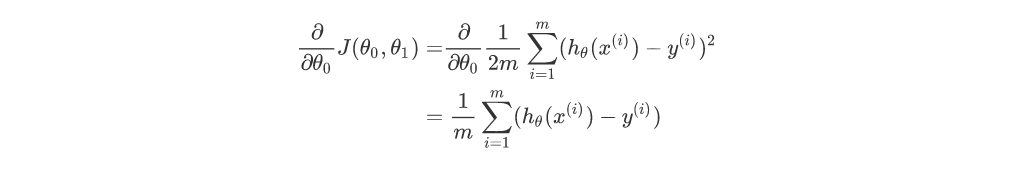
因此,
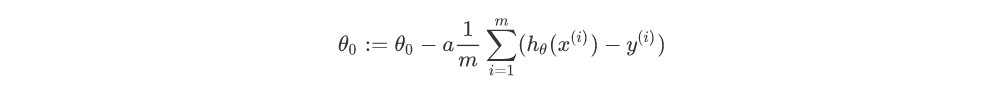
所以取2m的原因其实是为了求导数时化简方便,可以和平方项的2约掉。
【Coursera-ML-Notes】线性回归(上)的更多相关文章
- Coursera ML笔记 - 神经网络(Representation)
前言 机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,涵盖线性回归.逻辑回归.Softmax回归.神经网络和SVM等等,主要学习资料来自Standford Andrew N ...
- (转载)[机器学习] Coursera ML笔记 - 监督学习(Supervised Learning) - Representation
[机器学习] Coursera ML笔记 - 监督学习(Supervised Learning) - Representation http://blog.csdn.net/walilk/articl ...
- [机器学习] Coursera ML笔记 - 逻辑回归(Logistic Regression)
引言 机器学习栏目记录我在学习Machine Learning过程的一些心得笔记,涵盖线性回归.逻辑回归.Softmax回归.神经网络和SVM等等.主要学习资料来自Standford Andrew N ...
- 如何应用ML的建议-上
本博资料来自andrew ng的13年的ML视频中10_X._Advice_for_Applying_Machine_Learning. 遇到问题-部分(一) 错误统计-部分(二) 正确的选取数据集- ...
- 批量下载Coursera及其他场景上的文件
以下方法同样适用于其他场景的批量下载. 最近在学习Coursera退出的深度学习课程,我希望把课程提供的作业下载下来以备以后复习,但是课程有很多文件,比如说脸部识别一课中的参数就多达226个csv文件 ...
- ml的线性回归应用(python语言)
线性回归的模型是:y=theta0*x+theta1 其中theta0,theta1是我们希望得到的系数和截距. 下面是代码实例: 1. 用自定义数据来看看格式: # -*- coding:utf ...
- ML:多变量线性回归(Linear Regression with Multiple Variables)
引入额外标记 xj(i) 第i个训练样本的第j个特征 x(i) 第i个训练样本对应的列向量(column vector) m 训练样本的数量 n 样本特征的数量 假设函数(hypothesis fun ...
- Coursera连接不上(视频无法播放),修改hosts文件
视频问题 如果Coursera网站连接不上,或者视频加载不出来.可以通过如下方式进行配置: 一.找到hosts文件 Windows 系统, hosts文件位于: [C:\Windows\Syste ...
- 贝叶斯线性回归(Bayesian Linear Regression)
贝叶斯线性回归(Bayesian Linear Regression) 2016年06月21日 09:50:40 Duanxx 阅读数 54254更多 分类专栏: 监督学习 版权声明:本文为博主原 ...
- 机器学习之单变量线性回归(Linear Regression with One Variable)
1. 模型表达(Model Representation) 我们的第一个学习算法是线性回归算法,让我们通过一个例子来开始.这个例子用来预测住房价格,我们使用一个数据集,该数据集包含俄勒冈州波特兰市的住 ...
随机推荐
- weblogic之CVE-2018-3191漏洞分析
weblogic之CVE-2018-3191漏洞分析 理解这个漏洞首先需要看这篇文章:https://www.cnblogs.com/afanti/p/10193169.html 引用廖新喜说的,说白 ...
- 最新版的Chrome 69.0 设置始终开启flash而不是先询问
## 69.0 之前的版本 ## 1.打开 chrome://settings/content/flash 2.禁止网站运行Flash -> 改为“Ask (Default)” 3. ...
- openstack排除查找错误的两种方法
1.openstack日志一般放在什么什么位置?2.如何调试openstack命令执行过程? 我们会经常错误,但是我们碰到错误该怎么做,该如何找到原因.对于openstack有两种办法:在上一篇文章h ...
- 关于C#的静态类和静态构造函数
静态构造函数是C#的一个新特性,其实好像很少用到.不过当我们想初始化一些静态变量的时候就需要用到它了.这个构造函数是属于类的,而不是属于哪里实例的,就是说这个构造函数只会被执行一次.也就是在创建第一个 ...
- 【nodeJs】nodejs
node.js
- java课设数据库打包报错
最近在交java课设时把东西打包给老师遇到许多奇葩问题, 首先是数据库复制时提示: 这是数据库与SQL server服务没有分离(我用的是SQLserver暂时,对于其他的,我以后会继续尝试)可以进行 ...
- DBlink的创建与删除
创建方式一: create [public] database link link名称 connect to 对方数据库用户identified by 对方数据库用户密码 using '对方数据库i ...
- 与数论的爱恨情仇--01:判断大素数的Miller-Rabin
在我们需要判断一个数是否是素数的时候,最容易想到的就是那个熟悉的O(√n)的算法.那个算法非常的简单易懂,但如果我们仔细想想,当n这个数字很大的时候,这个算法其实是不够用的,时间复杂度会相对比较高. ...
- vue中刷新页面时去闪烁,提升体验方法
首先在最外层div添加v-if="isReloadAlive",并创建变量isReloadAlive = true 随后添加provide()以及reload方法,如下: expo ...
- helpera64开发板下制作ubuntu rootfs镜像
下一篇路径:https://www.cnblogs.com/jizizh/p/10499448.html 环境: HelperA64开发板 Linux3.10内核 时间:2019.02.14 目标:定 ...