攻城狮在路上(陆)-- hadoop分布式环境搭建(HA模式)
一、环境说明:
操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86_64 x86_64 x86_64 GNU/Linux
jdk版本:java version "1.7.0_79"
hadoop版本:Apache hadoop-2.5.2
zookeeper:3.4.6
本文实现hadoop分布式环境搭建,启用YARN,利用zookeeper实现HA。
二、节点说明:
zookeeper:node2\node3\node4
namenode:node1\node5
journalnode:node2\node3\node4
datanode:node2\node3\node4
ResourceManager:node1\node5
三、安装前准备:
1、实现各个节点之间的免密码登录设置。
2、在/etc/hosts文件中对各个节点进行配置。我的配置如下:
192.168.103.101 node1
192.168.103.102 node2
192.168.103.103 node3
192.168.103.104 node4
192.168.103.105 node5
四、步骤说明:
1、安装zookeeper。
2、配置hadoop相关文件。
3、启动hadoop系统,浏览器界面验证。
五、安装zookeeper:
首先在node2节点上进行以下操作。
1、首先从官网下载,本文使用的版本为3.4.6。
2、解压安装包,并复制到指定目录下。
tar zxvf zookeeper-3.4..tar.gz
mv zookeeper-3.4./ /home/install/
3、进入到zookeeper安装目录,修改配置文件zoo.cfg,若该文件不存在,将zoo_sample.cfg重命名为zoo.cfg:
cd /home/install/zookeeper-3.4./
vim conf/zoo.cfg
添加或修改以下代码:
dataDir=/opt/tem/zookeeper #修改此处为/tmp目录以外的其他目录 server.=node2::
server.=node3::
server.=node4::
上面的代码定义了3台zookeeper服务器。数量必须为奇数。
3、切换到上面定义的/opt/tem/zookeeper/目录下,提供一个叫myid的文件。
cd /opt/tem/zookeeper/
vim myid
在myid文件中输入一个2,保存退出即可。
4、上面相同的操作在node3和node4上重复进行(或者也可以将node2上的安装目录以及/opt/tem/zookeeper/拷贝到node3和node4上)
注意将node3上的myid文件的内容修改为3,将node4上的myid文件的内容修改为4。
5、将zookeeper安装目录/bin添加到~/.bash_profile中(可选操作,仅是为了命令行操作方便)
export PATH=$PATH:/home/install/zookeeper-3.4./bin
6、在node2\node3\node4上分别启动zookeeper:
zkServer.sh start
7、用以下命令测试一下是否正确启动:
zkCli.sh
效果如下图即可:
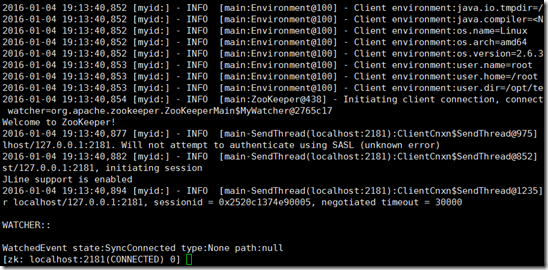
至此,zookeeper安装完毕。
六、配置hadoop相关脚本:
以下操作在node1上进行。
配置内容皆参考hadoop官方网站。本文中hadoop安装目录为/home/install/hadoop-2.5.
1、修改hadoop-env.sh文件,添加以下内容:
export JAVA_HOME=/usr/java/jdk1..0_79
export HADOOP_PREFIX=/home/install/hadoop-2.5.
2、修改core-site.xml文件:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/tep/hadoop-2.5.</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node2:,node3:,node4:</value>
</property>
</configuration>
说明:
- ha.zookeeper.quorum:指定zookeeper的3个节点访问方式。
- fs.defaultFS:hadoop2.x中的固定写法,其中mycluster是hdfs-site.xml中配置的nameservice-id。
- hadoop.tmp.dir:这里指定hadoop的临时文件夹,不能放在/tmp目录下。
3、修改hdfs-site.xml文件:
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node5:</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node5:</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node2:8485;node3:8485;node4:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/tem/journalnode</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
4、修改yarn-site.xml中的内容:
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node5</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node2:,node3:,node4:</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
5、修改mapred-site.xml文件:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
6、保证conf目录下不要有masters文件。
7、修改slaves文件:
node2
node3
node4
8、将$HADOOP_HOME/etc/hadoop/下的配置文件分别拷贝到node2\node3\node4\node5节点上。
scp etc/hadoop/* root@node2:/home/install/hadoop-2.5.1/etc/hadoop/
scp etc/hadoop/* root@node3:/home/install/hadoop-2.5.1/etc/hadoop/
scp etc/hadoop/* root@node4:/home/install/hadoop-2.5.1/etc/hadoop/
scp etc/hadoop/* root@node5:/home/install/hadoop-2.5.1/etc/hadoop/
9、执行下述命令:
hdfs zkfc -formatZK
其作用是在zookeeper中创建一个属于当前集群的目录:

10、启动zk:
hadoop-daemon.sh start zkfc
11、启动hdfs:
start-dfs.sh
9、在node1上启动yarn:
start-yarn.sh
10、在node5上执行下述命令:
yarn-daemon.sh start resourcemanager
11、浏览器中查看界面:http://node1:8088
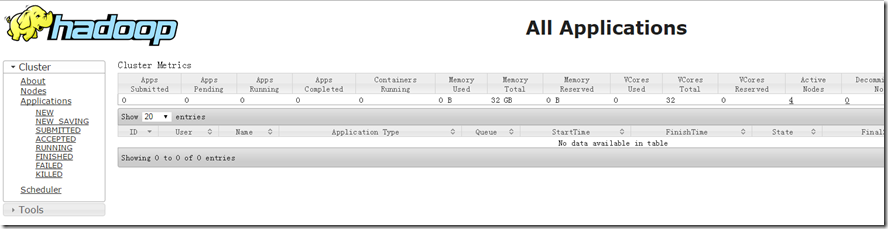
攻城狮在路上(陆)-- hadoop分布式环境搭建(HA模式)的更多相关文章
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- 攻城狮在路上(陆)-- 配置hadoop本地windows运行MapReduce程序环境
本文的目的是实现在windows环境下实现模拟运行Map/Reduce程序.最终实现效果:MapReduce程序不会被提交到实际集群,但是运算结果会写入到集群的HDFS系统中. 一.环境说明: ...
- [大数据学习研究] 3. hadoop分布式环境搭建
1. Java安装与环境配置 Hadoop是基于Java的,所以首先需要安装配置好java环境.从官网下载JDK,我用的是1.8版本. 在Mac下可以在终端下使用scp命令远程拷贝到虚拟机linux中 ...
- 攻城狮在路上(陆)-- hadoop单机环境搭建(一)
一.环境说明: 操作系统:Centos6.5 Linux node1 2.6.32-431.el6.x86_64 #1 SMP Fri Nov 22 03:15:09 UTC 2013 x86 ...
- 攻城狮在路上(陆)-- 提交运行MapReduce程序到hadoop集群运行
此种方式不能直接在eclipse中调试代码. 首先需要在src下放置服务器上的hadoop配置文件:core-site.xml\yarn-site.xml\hdfs-site.xml\mapred-s ...
- 攻城狮在路上(壹) Hibernate(十六)--- Hibernate声明数据库事务
一.数据库事务的概念: 数据库的ACID特征:Atomic.Consistency.Isolation.Durability.原子性.一致性.隔离性.持久性.不同的隔离级别引发的不同问题. 事务的AC ...
- 攻城狮在路上(伍)How tomcat works(四)Tomcat的默认连接器
在第4章中将通过剖析Tomcat4的默认连接器的代码,讨论需要什么来创建一个真实的Tomcat连接器. 注意:本章中提及的“默认连接器”是指Tomcat4的默认连接器.即使默认的连机器已经被 ...
- 攻城狮在路上(肆)How tomcat works(三) 连接器:Connector
在介绍中提到,Catalina中有两个主要的模块:连接器和容器.本章中你将会写一个可以创建更好的请求和响应对象的连接器,用来改进第2章中的程序.一个符合Servlet 2.3和2.4规范的连接器必须 ...
- 攻城狮在路上(肆)How tomcat works(二) 一个简单的servlet容器
该节在上一节的基础上增加了所谓对静态资源和动态资源访问的不同控制流程.示例里面采用的是对路径“/servlet/”进行了特殊处理. 一. 主要还是从HttpServer1中的main方法开始,先解析出 ...
随机推荐
- Python Day14
HTML HTML是英文Hyper Text Mark-up Language(超文本标记语言)的缩写,他是一种制作万维网页面标准语言(标记).相当于定义统一的一套规则,大家都来遵守他,这样就可以让浏 ...
- Linux学习笔记<五>
管道命令(pipe) 1.把一个命令的输出作为另一个命令的输入 ls -al /etc | less 2.选取命令:cut和grep cut命令可以将一段消息的某段切出来. -d接分隔符,-f是取出第 ...
- CMake
使用CMake编译跨平台静态库 http://www.tuicool.com/articles/3uu2Yj cmake命令 安装.用法简介 https://fukun.org/archives/04 ...
- diff生成补丁与patch打补丁
1.使用diff生成补丁: diff是Linux下的文件比较命令,参数这里就不说了,直接man一下就行了,不仅可以比较文件,也可以比较两个目录,并且可以将不同之处生成补丁文件,其实就是一种打补丁的命令 ...
- getElementsByClassName简单实现
function getElementsByClassName(node, className) { var aClassReg = className.split(' ').map(function ...
- spring事务传播性与隔离级别
事务的7种传播级别: 1)PROPAGATION_REQUIRED:支持当前事务,没有事务就新建一个. 2)PROPAGATION_SUPPORTS:支持当前事务,如果没有事务,以非事务方式处理 3) ...
- 利用AOP与ToStringBuilder简化日志记录
刚学spring的时候书上就强调spring的核心就是ioc和aop blablabla...... IOC到处都能看到...AOP么刚开始接触的时候使用在声明式事务上面..当时书上还提到一个用到ao ...
- 【12-26】go.js
var $ = go.GraphObject.make; // for conciseness in defining templates function buildAlarm(row,column ...
- [老文章搬家] [翻译] 深入解析win32 crt 调试堆
09 年翻译的东西. 原文见: http://www.nobugs.org/developer/win32/debug_crt_heap.html 在DeviceStudio的Debug编译模式下, ...
- jquery_DOM笔记4
jQuery遍历函数: add()添加,可以是样式,字符串,元素,文本,js对象 andself() 指向匹配元素本身 chilidren() 匹配元素的所有子元素的匹配元素 closest() 从本 ...