Elasticsearch快速入门案例
写在前面的话:读书破万卷,编码如有神
--------------------------------------------------------------------
参考内容:
《Elasticsearch顶尖高手系列-快速入门篇》,中华石杉
--------------------------------------------------------------------
主要内容包括:
- es的document数据格式和数据库的关系型数据格式的区别
- 简单的集群管理
- 电商网站商品管理案例背景介绍
- 商品的CRUD操作(document 的CRUD操作 )
--------------------------------------------------------------------
1、es的document数据格式和数据库的关系型数据格式的区别
比如有如下的json:
{
"email":"zhangsan@sina.com",
"first_name":"san",
"last_name":"zhang",
"info":{
"bio":"curious and modest",
"age":30,
"interests":["bike","climb"]
"join_date":"2017/01/01"
}
}
es的docuement可以直接用上面的json数据格式来表达。
但是在java中需要两个类来表达:
public class Employee {
private String email;
private String firstName;
private String lastName;
private EmployeeInfo info;
}
private class EmployeeInfo {
private String bio; // 性格
private Integer age;
private String[] interests; // 兴趣爱好
private Date joinDate;
}
可以看出employee对象里面包含了Employee类自己的属性,而且还有一个EmployeeInfo对象。
在数据库中的话,就需要两张表:employee表、employee_info表,将employee对象的数据重新拆开来,变成Employee数据和EmployeeInfo数据
employee表:email,first_name,last_name,join_date,4个字段
employee_info表:bio,age,interests,3个字段;此外还有一个外键字段,比如employee_id,关联着employee表。
我们就明白了es的document数据格式和数据库的关系型数据格式的区别:
- 应用系统的数据结构都是面向对象的,复杂的
- 对象数据存储到数据库中,只能拆解开来,变为扁平的多张表,每次查询的时候还得还原回对象格式,相当麻烦
- ES是面向文档的,文档中存储的数据结构,与面向对象的数据结构是一样的,基于这种文档数据结构,es可以提供复杂的索引、全文检索、分析聚合等功能
- es的document用json数据格式来表达
--------------------------------------------------------------------
2、简单的集群管理
(2.1)快速检查集群的健康状况
在Kibana中执行如下命令: GET _cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1518657893 09:24:53 huobaopaocai-es-cluster yellow 1 1 1 1 0 0 1 0 - 50.0%
如何快速的了解集群的健康状态? green、yellow、red
- green: 每个索引的primary shard和replica shard都是active状态
- yellow: 每个索引的primary shard都是active状态,但是部分replica shard不是active状态,处于不可用状态
- red: 不是所有索引的primary shard都是active状态的,部分索引有数据丢失
为什么现在我们的是处于yellow状态?
我们现在就一个笔记本电脑,就启动了一个es进程,相当于就只有一个node。现在es中有一个index,就是kibana自己内置建立的index。由于默认的配置是给每个index分配5个primary shard和5个replica shard,而且primary shard和replica shard不能在同一台机器上(为了容错)。现在kibana自己建立的index是1个primary shard和1个replica shard。当前就一个node,所以只有1个primary shard被分配了和启动了,但是一个replica shard没有第二台机器去启动。
(2.2)快速查看集群中有些索引
在Kibana中执行如下命令: GET _cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open .kibana CaxZ5uJGSJy3rCzv_3RIzQ 1 1 1 0 3.1kb 3.1kb
(2.3)简单的索引操作
创建索引: PUT /test_index?pretty
{
"acknowledged": true,
"shards_acknowledged": true
}
再次查看索引:
GET _cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open .kibana CaxZ5uJGSJy3rCzv_3RIzQ 1 1 1 0 3.1kb 3.1kb
yellow open test_index i2LdlSIqRXCZQCLauVBiRw 5 1 0 0 650b 650b
删除索引: DELETE /test_index?pretty
{
"acknowledged": true
}
再次查看索引:
GET _cat/indices?v health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open .kibana CaxZ5uJGSJy3rCzv_3RIzQ 1 1 1 0 3.1kb 3.1kb
--------------------------------------------------------------------
3、电商网站商品管理案例背景介绍
有一个电商网站,需要为其基于ES构建一个后台系统,提供以下功能:
- 对商品信息进行CRUD操作
- 执行简单的结构化查询
- 可以执行简单的全文检索,以及复杂的phrase(短语)检索
- 对于全文检索的结果,可以进行高亮显示
- 对数据进行简单的聚合分析
--------------------------------------------------------------------
4、商品的CRUD操作(document 的CRUD操作 )
(4.1)新增商品:新增文档、建立索引
基本语法格式:
PUT /index/type/id
{
"json数据"
}
准备三条数据:
PUT /ecommerce/product/1
{
"name" : "gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
} PUT /ecommerce/product/2
{
"name" : "jiajieshi yagao",
"desc" : "youxiao fangzhu",
"price" : 25,
"producer" : "jiajieshi producer",
"tags": [ "fangzhu" ]
} PUT /ecommerce/product/3
{
"name" : "zhonghua yagao",
"desc" : "caoben zhiwu",
"price" : 40,
"producer" : "zhonghua producer",
"tags": [ "qingxin" ]
}
执行每条新增语句的结果:
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
(ps:es会自动建立index和type,不需要提前创建,而且es默认会对document每个field建立倒排索引,让其可以被搜索。)
用java来实现往es中添加docuemnt操作
@Autowired
private ElasticsearchConstant elasticsearchConstant; /**
* 新增es的docuemnt
*/
@Test
public void createDocumentTest() throws IOException {
TransportClient client = elasticsearchConstant.getClient();
IndexResponse response = client.prepareIndex(elasticsearchConstant.getEsIndex(), elasticsearchConstant.getEsType(),"1")
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("name","gaolujie yagao")
.field("desc", "gaoxiao meibai")
.field("price", 30)
.field("producer", "gaolujie producer")
.endObject())
.get();
LOG.info(String.format("新增es的docuemnt结果: %s",response.toString()));
} 执行结果:
2018-02-15 11:37:24 INFO [main] (EcommerceTest.java:56) createDocumentTest - 新增es的docuemnt结果: IndexResponse[index=ecommerce,type=product,id=1,version=1,result=created,shards={"total":2,"successful":1,"failed":0}]
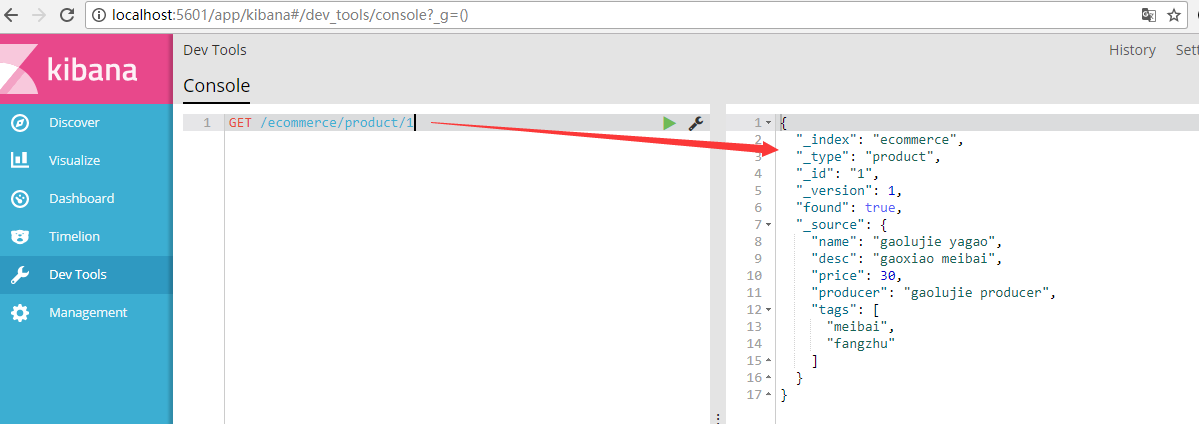
(4.2)检索索引:检索文档
基本语法格式:
GET /index/type/id
用java来实现查询es中docuemnt操作
@Autowired
private ElasticsearchConstant elasticsearchConstant; /**
* 查询es的document
*/
@Test
public void getDocumentTest() throws IOException{
TransportClient client = elasticsearchConstant.getClient();
GetResponse response = client.prepareGet(elasticsearchConstant.getEsIndex(), elasticsearchConstant.getEsType(), "1").get();
LOG.info(String.format("查询es的docuemnt结果: %s",response.toString()));
} 执行结果:
2018-02-15 11:42:19 INFO [main] (EcommerceTest.java:68) getDocumentTest - 查询es的docuemnt结果: {"_index":"ecommerce","_type":"product","_id":"1","_version":1,"found":true,"_source":{"name":"gaolujie yagao","desc":"gaoxiao meibai","price":30,"producer":"gaolujie producer"}}
(4.3)修改商品:替换文档
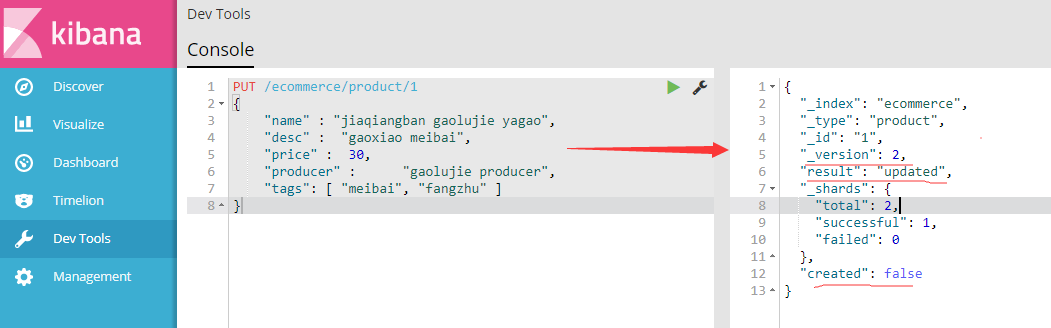
(ps:替换方式有一个不好:必须带上所有的field才能去进行信息的修改。)
(4.4)修改商品:更新文档
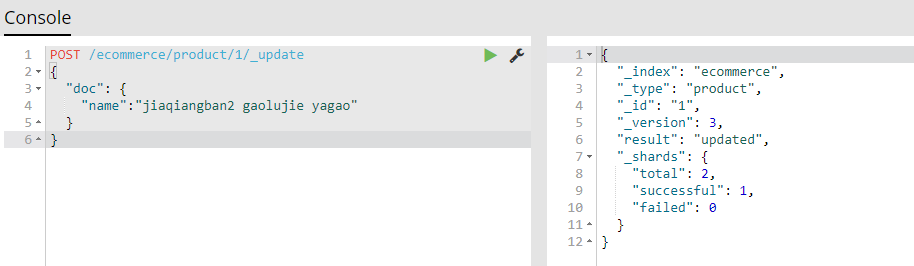
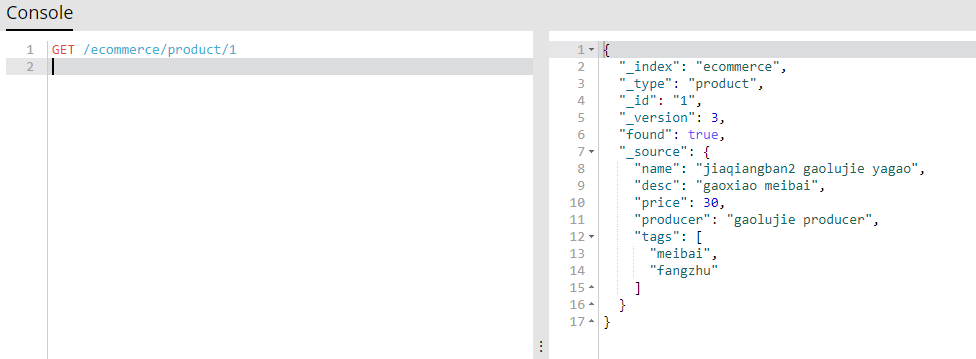
用java来实现编辑es中的docuement:
@Autowired
private ElasticsearchConstant elasticsearchConstant; /**
* 更新es的docuemnt
* @throws IOException
*/
@Test
public void updateDocument() throws IOException {
TransportClient client = elasticsearchConstant.getClient();
UpdateResponse updateResponse = client.prepareUpdate(elasticsearchConstant.getEsIndex(), elasticsearchConstant.getEsType(), "1")
.setDoc(jsonBuilder()
.startObject()
.field("name", "jiaqiang gaolujie yagao")
.endObject())
.get();
LOG.info(String.format("更新es的docuemnt结果: %s",updateResponse.toString()));
} 运行结果:
2018-02-15 15:55:13 INFO [main] (EcommerceTest.java:73) updateDocument - 更新es的docuemnt结果: UpdateResponse[index=ecommerce,type=product,id=1,version=2,result=updated,shards=ShardInfo{total=2, successful=1, failures=[]}]
(4.5)删除商品:删除文档
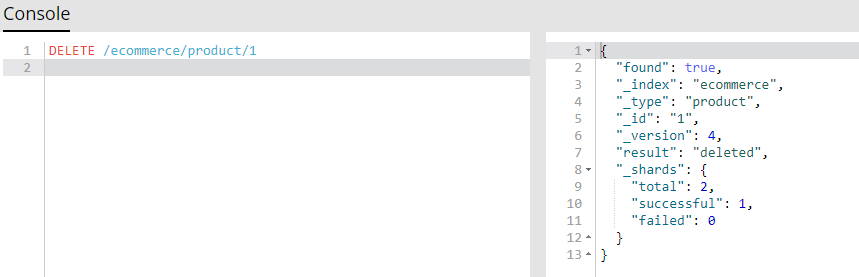
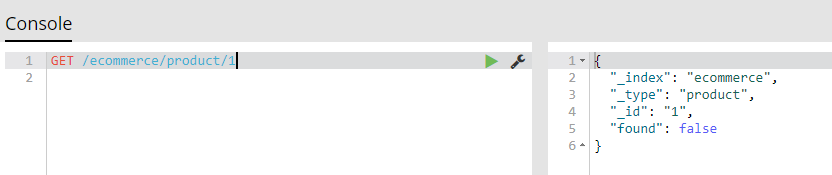
用java来实现删除es中的docuement:
@Autowired
private ElasticsearchConstant elasticsearchConstant; /**
* 删除es中的document
*/
@Test
public void deleteDocument(){
TransportClient client = elasticsearchConstant.getClient();
DeleteResponse response = client.prepareDelete(elasticsearchConstant.getEsIndex(), elasticsearchConstant.getEsType(), "1").get();
LOG.info(String.format("删除es的docuemnt结果: %s",response.toString()));
} 运行结果:
2018-02-15 16:00:04 INFO [main] (EcommerceTest.java:84) deleteDocument - 删除es的docuemnt结果: DeleteResponse[index=ecommerce,type=product,id=1,version=3,result=deleted,shards=ShardInfo{total=2, successful=1, failures=[]}]
Elasticsearch快速入门案例的更多相关文章
- Part1-HttpClient快速入门案例
前言 最近这段时间在学习爬虫方面的知识,接触了几个优秀的爬虫框架,也爬取了一些自己喜欢网站的信息.通过官网学习HttpClient的过程中,希望通过写此博客来巩固自己的学习,也为有需要的人提供学习帮助 ...
- Elasticsearch快速入门和环境搭建
内容概述 什么是Elasticsearch,为什么要使用它? 基础概念简介 节点(node) 索引(index) 类型映射(mapping) 文档(doc) 本地环境搭建,创建第一个index 常用R ...
- Elasticsearch学习之快速入门案例
1. document数据格式 面向文档的搜索分析引擎 (1)应用系统的数据结构都是面向对象的,复杂的(2)对象数据存储到数据库中,只能拆解开来,变为扁平的多张表,每次查询的时候还得还原回对象格式,相 ...
- ElasticSearch快速入门
知识储备 学习ElasticSearch之前可以先了解一下lucene,这里是我整理的一篇关于lucene的笔记(传送门),对搜索框架有兴趣的还可以了解一下另一款企业级搜索应用服务器---solr(传 ...
- Elasticsearch - 快速入门
Elasticsearch是基于Apache 2.0开源的实时.分布式.分析搜索引擎,相比Lucene,Elasticsearch的上手比较容易,这篇文章主要纪录Elasticsearch的基本概念和 ...
- Elasticsearch 快速入门教程
面向文档 应用中的对象很少只是简单的键值列表,更多时候它拥有复杂的数据结构,比如包含日期.地理位置.另一个对象或者数组. 总有一天你会想到把这些对象存储到数据库中.将这些数据保存到由行和列组成的关系数 ...
- javaWeb el表达式和jstl快速入门案例
<%@page import="de.bvb.domain.Person"%> <%@page import="de.bvb.domain.Addres ...
- 3.1_springboot2.x检索之elasticsearch安装&快速入门
1.elasticsearch简介&安装 1.1.1.elasticsearch介绍 我们的应用经常需要添加检索功能,开源的 ElasticSearch 是目前全文搜索引擎的首选.他可以快 ...
- SpringBoot整合ActiveMQ快速入门
Spring Boot 具有如下特性: 为基于 Spring 的开发提供更快的入门体验 开箱即用,没有代码生成,也无需 XML 配置.同时也可以修改默认值来满足特定的需求. 提供了一些大型项目中常见的 ...
随机推荐
- XSS练习小游戏和答案参考
源码:https://files.cnblogs.com/files/Eleven-Liu/xss%E7%BB%83%E4%B9%A0%E5%B0%8F%E6%B8%B8%E6%88%8F.zip 感 ...
- Oracle Certified Java Programmer 经典题目分析(二)
...接上篇 what is reserved(保留) words in java? A. run B. default C. implement D. import Java 关键字列表 (依字母排 ...
- /dev/mem可没那么简单【转】
转自:http://blog.csdn.net/skyflying2012/article/details/47611399 这几天研究了下/dev/mem,发现功能很神奇,通过mmap可以将物理地址 ...
- mysql5.7半自动同步设置【转】
mysql的主从复制主要有3种模式: a..主从同步复制:数据完整性好,但是性能消耗高 b.主从异步复制:性能消耗低,但是容易出现主从数据唯一性问题 c.主从半自动复制:介于上面两种之间.既能很好的保 ...
- Intel大坑之一:丢失的SSE2 128bit/64bit 位移指令,马航MH370??
缘由 最近在写一些字符串函数的优化,兴趣使然,可是写的过程中,想要实现 128bit 的按 bit 逻辑位移,遇到了一个大坑,且听我娓娓道来. 如果要追究标题,更确切的是丢失的SSE2 128 bit ...
- Nginx - 压缩模块
1. 前言 在 Nginx 中与网页压缩相关的模块有两个:一个是 HttpGzipModule,另一个是 HttpGzipStaticModule.前者用于启用在文件传输过程中使用 gzip 压缩,而 ...
- 读书笔记--C陷阱与缺陷(六)
第六章 1.预处理器:预处理器先对代码进行必要的转换处理,简化编程者的工作. 它的重要原因有以下两点: a. 假如要将程序中出现的所有实例都加以修改,但希望只改动程序一处数值,重新编译实现. 预处理器 ...
- Oracle学习笔记:11g服务介绍及哪些服务必须开启?
由于工作环境中oracle版本为10g,不支持行转列函数pivot,特在自己电脑上安装了oracle 11g,但因为不经常使用,便把服务自动启动给关闭了,只在需要使用时手动启动,因此记录一下需要启动的 ...
- MySQL学习笔记:coalesce
函数:coalesce 作用:返回传入的参数中第一个非NULL的值 ); # ); # 如果传入的参数所有都是NULL,则返回NULL,比如: SELECT COALESCE(NULL, NULL, ...
- MAC下安装MAMP后,mysql server无法启动
用MAC下载安装了MAMP,之前使用是很好没问题的,但是突然无法启动mysql server,检查日志,提示InnDB出错,然后删掉了/Application/MAMP/db/mysql56目录下的i ...