基于Solr的空间搜索
如果需要对带经纬度的数据进行检索,比如查找当前所在位置附近1000米的酒店,一种简单的方法就是:获取数据库中的所有酒店数据,按经纬度计算距离,返回距离小于1000米的数据。
这种方式在数据量小的时候比较有效,但是当数据量大的时候,检索的效率是很低的,本文介绍使用Solr的Spatial Query进行空间搜索。
空间搜索原理
空间搜索,又名Spatial Search(Spatial Query),基于空间搜索技术,可以做到:
1)对Point(经纬度)和其他的几何图形建索引
2)根据距离排序
3)根据矩形,圆形或者其他的几何形状过滤搜索结果
在Solr中,空间搜索主要基于GeoHash和Cartesian Tiers 2个概念来实现:
GeoHash算法
通过GeoHash算法,可以将经纬度的二维坐标变成一个可排序、可比较的的字符串编码。
在编码中的每个字符代表一个区域,并且前面的字符是后面字符的父区域。其算法的过程如下:
根据经纬度计算GeoHash二进制编码
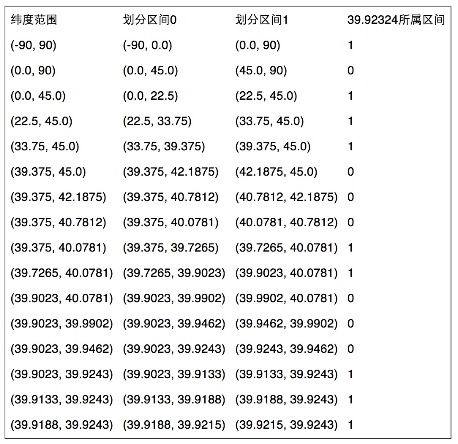
地球纬度区间是[-90,90], 如某纬度是39.92324,可以通过下面算法对39.92324进行逼近编码:
1)区间[-90,90]进行二分为[-90,0),[0,90],称为左右区间,可以确定39.92324属于右区间[0,90],给标记为1;
2)接着将区间[0,90]进行二分为 [0,45),[45,90],可以确定39.92324属于左区间 [0,45),给标记为0;
3)递归上述过程39.92324总是属于某个区间[a,b]。随着每次迭代区间[a,b]总在缩小,并越来越逼近39.928167;
4)如果给定的纬度(39.92324)属于左区间,则记录0,如果属于右区间则记录1,这样随着算法的进行会产生一个序列1011 1000 1100 0111 1001,序列的长度跟给定的区间划分次数有关。
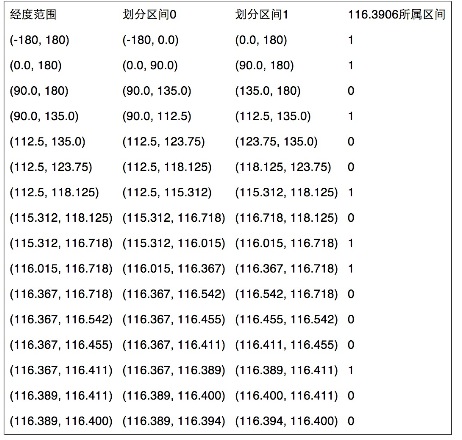
同理,地球经度区间是[-180,180],对经度116.3906进行编码的过程也类似:
组码
通过上述计算,纬度产生的编码为1011 1000 1100 0111 1001,经度产生的编码为1101 0010 1100 0100 0100。偶数位放经度,奇数位放纬度,把2串编码组合生成新串:11100 11101 00100 01111 00000 01101 01011 00001。
最后使用用0-9、b-z(去掉a, i, l, o)这32个字母进行base32编码,首先将11100 11101 00100 01111 00000 01101 01011 00001转成十进制 28,29,4,15,0,13,11,1,十进制对应的编码就是wx4g0ec1。同理,将编码转换成经纬度的解码算法与之相反,具体不再赘述。
由上可知,字符串越长,表示的范围越精确。当GeoHash base32编码长度为8时,精度在19米左右,而当编码长度为9时,精度在2米左右,编码长度需要根据数据情况进行选择。不过从GeoHash的编码算法中可以看出它的一个缺点,位于边界两侧的两点,虽然十分接近,但编码会完全不同。实际应用中,可以同时搜索该点所在区域的其他八个区域的点,即可解决这个问题。
Cartesian Tiers 笛卡尔层
笛卡尔分层模型的思想是将经纬度转换成更大粒度的分层网格,该模型创建了很多的地理层,每一层在前一层的基础上细化切分粒度,每一个网格被分配一个ID,代表一个地理位置。
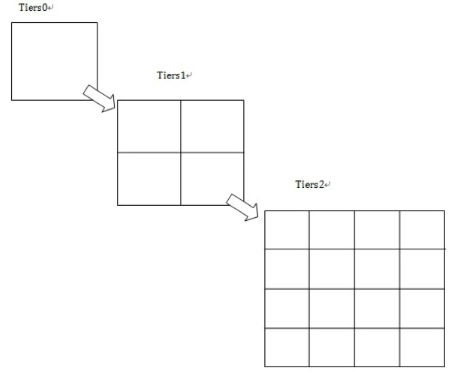
每层以2的平方递增,所以第一层为4个网格,第二层为16 个,所以整个地图的经纬度将在每层的网格中体现:
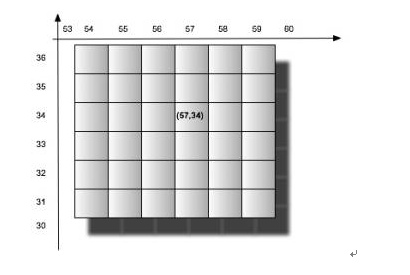
那么如何构建这样的索引结构呢,其实很简单,只需要对应笛卡尔层的层数来构建域即可,一个域或坐标对应多个tiers层次。也即是tiers0->field_0,tiers1->field_1,tiers2->field_2,……,tiers19->field_19。(一般20层即可)。每个对应笛卡尔层次的域将根据当前这条记录的经纬度通过笛卡尔算法计算出归属于当前层的网格,然后将gridId(网格唯一标示)以term的方式存入索引。这样每条记录关于笛卡尔0-19的域将都会有一个gridId对应起来。但是查询的时候一般是需要查周边的地址,那么可能周边的范围超过一个网格的范围,那么实际操作过程是根据经纬度和一个距离确定出需要涉及查询的从19-0(从高往低查)若干层对应的若干网格的数据。那么一个经纬度周边地址的查询只需要如下图圆圈内的数据:
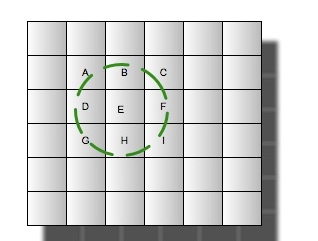
由上可知,基于Cartesian Tier的搜索步骤为:
1、根据Cartesian Tier层获得坐标点的地理位置gridId
2、与系统索引gridId匹配计算
3、计算结果集与目标坐标点的距离返回特定范围内的结果集合
使用笛卡尔层,能有效缩减少过滤范围,快速定位坐标点。
基于Solr的空间搜索实战
Solr已经提供了3种filedType来进行空间搜索:
1) LatLonType(用于平面坐标,而不是大地坐标)
2) SpatialRecursivePrefixTreeFieldType(缩写为RPT)
3) BBoxField(用于边界索引查询)
本文重点介绍使用SpatialRecursivePrefixTreeFieldType,不仅可以用点,也可以用于多边形的查询。
1、配置Solr
首先看下数据:
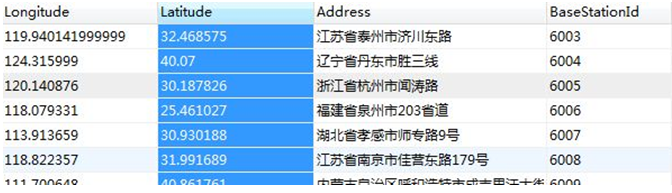
Solr的schema.xml配置:
<field name="station_id" type="long" indexed="true" stored="true" required="true" multiValued="false" />
<field name="station_address" type="text_general" indexed="true" stored="true"/>
<field name="station_position" type="location_rpt" indexed="true" stored="true"/> <uniqueKey>station_id</uniqueKey>
这里重点是station_position,它的type是location_rpt,它在Solr中的定义如下:
<!-- A specialized field for geospatial search. If indexed, this fieldType must not be multivalued. -->
<fieldType name="location" class="solr.LatLonType" subFieldSuffix="_coordinate"/> <!-- An alternative geospatial field type new to Solr 4. It supports multiValued and polygon shapes.
For more information about this and other Spatial fields new to Solr 4, see:
http://wiki.apache.org/solr/SolrAdaptersForLuceneSpatial4
-->
<fieldType name="location_rpt" class="solr.SpatialRecursivePrefixTreeFieldType"
geo="true" distErrPct="0.025" maxDistErr="0.000009" units="degrees" /> <!-- Spatial rectangle (bounding box) field. It supports most spatial predicates, and has
special relevancy modes: score=overlapRatio|area|area2D (local-param to the query). DocValues is required for
relevancy. -->
<fieldType name="bbox" class="solr.BBoxField"
geo="true" units="degrees" numberType="_bbox_coord" />
<fieldType name="_bbox_coord" class="solr.TrieDoubleField" precisionStep="8" docValues="true" stored="false"/>
对solr.SpatialRecursivePrefixTreeFieldType的配置说明:
SpatialRecursivePrefixTreeFieldType
用于深度遍历前缀树的FieldType,主要用于获得基于Lucene中的RecursivePrefixTreeStrategy。
geo
默认为true,值为true的情况下坐标基于球面坐标系,采用Geohash的方式;值为false的情况下坐标基于2D平面的坐标系,采用Euclidean/Cartesian的方式。
distErrPct
定义非Point图形的精度,范围在0-0.5之间。该值决定了非Point的图形索引或查询时的level(如geohash模式时就是geohash编码的长度)。当为0时取maxLevels,即精度最大,精度越大将花费更多的空间和时间去建索引。
maxDistErr/maxLevels:maxDistErr
定义了索引数据的最高层maxLevels,上述定义为0.000009,根据GeohashUtils.lookupHashLenForWidthHeight(0.000009, 0.000009)算出编码长度为11位,精度在1米左右,直接决定了Point索引的term数。maxLevels优先级高于maxDistErr,即有maxLevels的话maxDistErr失效。详见SpatialPrefixTreeFactory.init()方法。不过一般使用maxDistErr。
units
单位是degrees。
worldBounds
世界坐标值:”minX minY maxX maxY”。 geo=true即geohash模式时,该值默认为”-180 -90 180 90”。geo=false即quad时,该值为Java double类型的正负边界,此时需要指定该值,设置成”-180 -90 180 90”。
2、建立索引
这里使用Solrj来建立索引:
//Index some base station data for test
public void IndexBaseStation(){
BaseStationDb baseStationDb = new BaseStationDb();
List<BaseStation> stations = baseStationDb.getAllBaseStations();
Collection<SolrInputDocument> docList = new ArrayList<SolrInputDocument>();
for (BaseStation baseStation : stations) {
//添加基站数据到Solr索引中
SolrInputDocument doc = new SolrInputDocument();
doc.addField("station_id", baseStation.getBaseStationId());
doc.addField("station_address", baseStation.getAddress());
String posString = baseStation.getLongitude()+" "+baseStation.getLatitude() ;
doc.addField("station_position", posString);
docList.add(doc);
}
try {
server.add(docList);
server.commit();
} catch (SolrServerException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} System.out.println("Index base station data done!");
}
这里使用“经度 纬度”这样的字符串格式将经纬度索引到station_position字段中。
3、查询
查询语法示例:
q={!geofilt pt=45.15,-93.85 sfield=poi_location_p d=5 score=distance}
q={!bbox pt=45.15,-93.85 sfield=poi_location_p d=5 score=distance}
q=poi_location_p:"Intersects(-74.093 41.042 -69.347 44.558)" //a bounding box (not in WKT)
q=poi_location_p:"Intersects(POLYGON((-10 30, -40 40, -10 -20, 40 20, 0 0, -10 30)))" //a WKT example
涉及到的字段说明:
|
字段 |
含义 |
|
q |
查询条件,如 q=poi_id:134567 |
|
fq |
过滤条件,如 fq=store_name:农业 |
|
fl |
返回字段,如fl=poi_id,store_name |
|
pt |
坐标点,如pt=54.729696,-98.525391 |
|
d |
搜索半径,如 d=10表示10km范围内 |
|
sfield |
指定坐标索引字段,如sfield=geo |
|
defType |
指定查询类型可以取 dismax和edismax,edismax支持boost函数相乘作用,dismax是通过累加方式计算最后的score. |
|
qf |
指定权重字段:qf=store_name^10+poi_location_p^5 |
|
score |
排序字段根据qf定义的字段defType定义的方式计算得到score排序输出 |
其中有几种常见的Solr支持的几何操作:
WITHIN:在内部
CONTAINS:包含关系
DISJOINT:不相交
Intersects:相交(存在交集)
1)点查询
测试代码:查询距离某个点pt距离为d的集合
SolrQuery params = new SolrQuery();
params.set("q", "*:*");
params.set("fq", "{!geofilt}"); //距离过滤函数
params.set("pt", "118.227985 39.410722"); //当前经纬度
params.set("sfield", "station_position"); //经纬度的字段
params.set("d", "50"); //就近 d km的所有数据
//params.set("score", "kilometers");
params.set("sort", "geodist() asc"); //根据距离排序:由近到远
params.set("start", "0"); //记录开始位置
params.set("rows", "100"); //查询的行数
params.set("fl", "*,_dist_:geodist(),score");//查询的结果中添加距离和score
返回结果集:
SolrDocument{station_id=12003, station_address=江苏南京1, station_position=118.227996 39.410733, _version_=1499776366043725838, _dist_=0.001559071, score=1.0}
SolrDocument{station_id=12004, station_address=江苏南京2, station_position=118.228996 39.411733, _version_=1499776366044774400, _dist_=0.14214091, score=1.0}
SolrDocument{station_id=12005, station_address=江苏南京3, station_position=118.238996 39.421733, _version_=1499776366044774401, _dist_=1.5471642, score=1.0}
SolrDocument{station_id=7583, station_address=河北省唐山市于唐线, station_position=118.399614 39.269098, _version_=1499776365690355717, _dist_=21.583544, score=1.0}
从这部分结果集中可以看出,前3条数据是离目标点"118.227985 39.410722"最近的(这3条数据是我伪造的,仅仅用于测试)。
2)多边形查询:
修改schema.xml配置文件:
<field name="station_position" type="location_jts" indexed="true" stored="true"/> <fieldType name="location_jts" class="solr.SpatialRecursivePrefixTreeFieldType"
spatialContextFactory="com.spatial4j.core.context.jts.JtsSpatialContextFactory" distErrPct="0.025" maxDistErr="0.000009" units="degrees"/>
JtsSpatialContextFactory
当有Polygon多边形时会使用jts(需要把jts.jar放到solr webapp服务的lib下)。基本形状使用SpatialContext (spatial4j的类)。
Jts下载:http://sourceforge.net/projects/jts-topo-suite/
测试代码:
SolrQuery params = new SolrQuery();
//q=geo:"Intersects(POLYGON((-10 30, -40 40, -10 -20, 40 20, 0 0, -10 30)))"
params.set("q", "station_position:\"Intersects(POLYGON((118 40, 118.5 40, 118.5 38, 118.3 35, 118 38,118 40)))\"");
params.set("start", "0"); //记录开始位置
params.set("rows", "100"); //查询的行数
params.set("fl", "*");
返回在这个POLYGON内的所有结果集。
3) 地址分词搜索
在“点查询”的基础上加上一些地址信息,就可以做一些地理位置+地址信息的LBS应用。
Solr分词配置
这里使用了mmseg4j分词器:https://github.com/chenlb/mmseg4j-solr
Schema.xml配置:
<field name="station_address" type="textComplex" indexed="true" stored="true" multiValued="true"/> <fieldtype name="textComplex" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="complex" dicPath="dic"/>
</analyzer>
</fieldtype>
<fieldtype name="textMaxWord" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="max-word" />
</analyzer>
</fieldtype>
<fieldtype name="textSimple" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" dicPath="D:/my_dic" />
</analyzer>
</fieldtype>
这里对“station_address”这个字段进行中文分词。
下载mmseg4j-core-1.10.0.jar和mmseg4j-solr-2.2.0.jar放到solr webapp服务的lib下。
测试代码:
public static SolrQuery getPointAddressQuery(String address){
SolrQuery params = new SolrQuery();
String q_params = "station_address:"+address;
params.set("q", q_params);
params.set("fq", "{!geofilt}"); //距离过滤函数
//params.set("fq","{!bbox}"); //距离过滤函数:圆的外接矩形
params.set("pt", "118.227985 39.410722"); //当前经纬度
params.set("sfield", "station_position"); //经纬度的字段
params.set("d", "50"); //就近 d km的所有数据
//params.set("score", "distance");
params.set("sort", "geodist() asc"); //根据距离排序:由近到远
params.set("start", "0"); //记录开始位置
params.set("rows", "100"); //查询的行数
params.set("fl", "*,_dist_:geodist(),score");
return params;
}
public static void main(String[] args) {
BaseStationSearch baseStationSearch = new BaseStationSearch();
baseStationSearch.IndexBaseStation(); //执行一次索引
//SolrQuery params = getPointQuery();
//SolrQuery params = getPolygonQuery();
SolrQuery params = getPointAddressQuery("鼓楼");
baseStationSearch.getAndPrintResult(params);
}
Search Results Count: 2
SolrDocument{station_id=12003, station_address=[江苏南京鼓楼东南大学], station_position=[118.227996 39.410733], _version_=1500226229258682377, _dist_=0.001559071, score=4.0452886}
SolrDocument{station_id=12004, station_address=[江苏南京鼓楼南京大学], station_position=[118.228996 39.411733], _version_=1500226229258682378, _dist_=0.14214091, score=4.0452886}
上面是测试的结果。
代码托管在GitHub上:https://github.com/luxiaoxun/Code4Java
参考:
http://wiki.apache.org/solr/SpatialSearch
https://cwiki.apache.org/confluence/display/solr/Spatial+Search
http://tech.meituan.com/solr-spatial-search.html
基于Solr的空间搜索的更多相关文章
- solr特点八:Spatial(空间搜索)
前言 在美团CRM系统中,搜索商家的效率与公司的销售额息息相关,为了让BD们更便捷又直观地去搜索商家,美团CRM技术团队基于Solr提供了空间搜索功能,其中移动端周边商家搜索和PC端的地图模式搜索功能 ...
- Apache Solr采用Java开发、基于Lucene的全文搜索服务器
http://docs.spring.io/spring-data/solr/ 首先介绍一下solr: Apache Solr (读音: SOLer) 是一个开源.高性能.采用Java开发.基于Luc ...
- 基于Solr和Zookeeper的分布式搜索方案的配置
1.1 什么是SolrCloud SolrCloud(solr 云)是Solr提供的分布式搜索方案,当你需要大规模,容错,分布式索引和检索能力时使用 SolrCloud.当一个系统的索引数据量少的时候 ...
- Solr 空间搜索配置、按经纬度计算距离排序
Solr 空间搜索配置 1. 在solr目录下的找到conf文件夹下的schema.xml. <fields> <!-- 在fields元素中添加如下代码 --> <fi ...
- solr服务(搜索服务)
1 Solr实现全文搜索 1.1 Solr是什么? Solr 是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器.Solr提供了比Lucene更为丰富的 ...
- 利用SOLR搭建企业搜索平台 之——MultiCore
Solr Multicore 是 solr 1.3 的新特性.其目是一个solr实例,可以有多个搜索应用. 下面着手来将solr给出的一个example跑出来.这篇文章是基于<利用SOLR搭建企 ...
- SOLR搭建企业搜索平台
一. SOLR搭建企业搜索平台 运行环境: 运行容器:Tomcat6.0.20 Solr版本:apache-solr-1.4.0 分词器:mmseg4j-1.6.2 词库:sogou-dic ...
- OpenCV 学习笔记 06 图像检索以及基于图像描述符的搜索
OpenCV 可以检测图像的主要特征,然后提取这些特征,使其成为图像描述符,这些图像特征可作为图像搜索的数据库:此外可以利用关键点将图像拼接 stitch 起来,组成一个更大的图像.如将各照片组成一个 ...
- hbase基于solr配置二级索引
一.概述 Hbase适用于大表的存储,通过单一的RowKey查询虽然能快速查询,但是对于复杂查询,尤其分页.查询总数等,实现方案浪费计算资源,所以可以针对hbase数据创建二级索引(Hbase Sec ...
随机推荐
- iBatis.net 循环iterate,没有foreach
3.9.4. Iterate Element This tag will iterate over a collection and repeat the body content for each ...
- ThinkPHP框架下的表单验证
之前的表单验证都是用js写的,这里也可以使用tp框架的验证.但是两者比较而言还是js验证比较好,因为tp框架验证会运行后台代码,这样运行速度和效率就会下降. 自动验证是ThinkPHP模型层提供的一种 ...
- 服务器端之间采用http接口调数据时的Cookie传值问题
public static string UrlGet(string url) { string responseContent = ""; string cookieValue ...
- 利用vim查看日志,快速定位问题
起因 在一般的情况下,如果开发过程中测试报告了一个问题,我一般会这么做: 1.在自己的开发环境下重试一下测试的操作,看看能不能重现问题.不行转2 2.数据库连接池改成测试库的地址,在自己的开发环境下重 ...
- shell if 浮点数比较
转shell中的浮点数比较http://nigelzeng.iteye.com/blog/1604640 博客分类: Bash Shell shell比较浮点数 由于程序需要,我要判断一个浮点数是否 ...
- MySQL的简单使用
MySQL 参数 参数 描述 备注 -D,--database=.name 打开指定数据库 mysql –uroot –procky –Dhisdb 或者mysql –uroot –prock ...
- .NET使用NPOI2.0导入导出Excel
NPOI开源地址:http://npoi.codeplex.com/ NPOI教程: http://tonyqus.sinaapp.com/ 具体的不在这里写了,感兴趣的可以去官网. 先来说导出的例子 ...
- C++ 之namespace常见用法
一.背景 需要使用Visual studio的C++,此篇对namespace的常用用法做个记录. 二.正文 namespace通常用来给类或者函数做个区间定义,以使编译器能准确定位到适合的类或者函数 ...
- struts2使用annotation注意事项
struts2使用annotation注意事项 1.包名只能以.action .actions .struts .struts2结尾.如:com.cnbolgs.web.actions 2.类名只 ...
- jqueryUI弹出框问题
jqueryui dialog中 select选不中或比较慢 dialog = function(Window,dialogDivId,title,buttons,css) { css = css|| ...