RabbitMQ上手记录–part 4-节点集群(单机多节点)
现在互联网应用动不动就说要HA,好像不搞个HA都不好意思说自己的应用能承载高并发,大用户量访问。RabbitMQ这个经典的消息组件,也必然逃不掉单点失效的尴尬局面。当然在RabbitMQ在被广泛应用于互联网之后,就对这个HA的需求做了实现,提供了集群供。这是RabbitMQ的内置功能,就跟普通集群的作用一样,就是在某个节点发生异常时,让生产者和消费者能保持通讯状态,同时通过提供更多的节点来增加系统的吞吐量。
RabbitMQ集群简介
RabbitMQ的集群实现是基于OTP分布式通讯框架实现的,该框架由Erlang语言实现。当一个节点失效的时候,客户端会自动连接到集群里的另一个节点,整个过程调用方不受影响,就好像没有断开一样。同时当集群承受加大的访问量的时候,可以通过添加更多的节点,线性的增加吞吐量和提高性能。但是RabbitMQ集群不能保证消息不丢失(这是另外一个话题了)。
RabbitMQ的集群仅仅是增加节点,但是节点之间的队列数据是不会同步的,也就是各个节点有自己独立的队列数据。这是RabbitMQ的默认设置。所以并不是说实现了集群,就可以保证数据的一致,这点需要明确。
RabbitMQ的集群架构简介
1.元数据(metadata)
元数据是RabbitMQ跟踪节点、提供链接信息的基本数据信息。
这里的元数据包含以下内容
队列元数据:队列名称和属性(比如是否持久队列或者是否自动删除队列)
Exchange元数据:Exchange名称,类型以及属性
绑定元数据(Binding):可以理解为一个路由表,就是如何通过Exchange找到消息队列,将消息投到队列。
Vhost元数据:命令空间、队列、Exchange的权限信息以及vhost内部的绑定信息。
有了这些metadata,RabbitMQ就能跟踪节点的所在服务器、节点之间的关系以及其他跟踪信息。metadata可以保存在内存或者磁盘中。保存在磁盘的话,那么在重启RabbitMQ节点之后就能重建队列和exchange。
集群节点中的队列
在上面介绍集群的时候,提到了一个关键的点,就是队列数据只存在于本地节点,不会同步到各个节点。在一个集群里面,创建一个队列时,只会在本地节点创建队列信息。这样只有本地节点知道队列的所有信息,所以一旦这个节点失效了,这个队列和对应的绑定信息也会消失。对于消费者来说,就失去了订阅信息,新生成的消息也无法投递,由于投递到了黑洞。
理论上看起来可以通过metadata去恢复队列信息,但是如果在其他非失效节点恢复队列信息,那么会出现404错误。这样做的目的是确保消息只存在于失效的队列中。我们唯一能做的就是恢复失效的节点。(以上问题只存在于支持持久的队列,如果队列不是持久的,可以直接恢复,反正没有数据需要处理)。
那么RabbitMQ为什么不把队列数据同步到各个节点呢?有以下2个原因:
1.存储空间问题
如果每个节点都包含了队列信息,会导致多出N倍的数据存储空间。
2 性能问题
对应支持持久的消息队列,保存到每个节点中需要很多IO写入和带宽,从而影响整个集群的性能。
集群中的Exchange
整个正好跟消息队列相反,Exchange的信息是分布式的,也就是各个节点都具有一份完整的Exchange信息。实际上Exchange就是一个路由表,所以很容易将路由信息复制到各个节点。
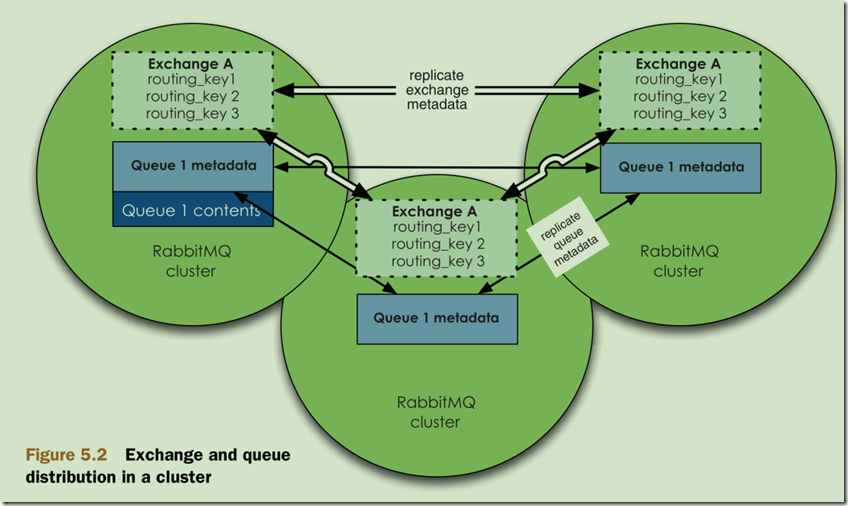 (集群中的queue和Exchange结构图,来自《RabbitMQ In Action》
(集群中的queue和Exchange结构图,来自《RabbitMQ In Action》
集群节点类型
最后一部分理论,讲完就进入啪啪的敲代码实际操作。
RabbitMQ的集群根据存储类型可以分成两种类型:内存节点和磁盘节点。这里存储的是metadata,内存节点保存在内存中,磁盘节点保存在磁盘中。
如果只有一个节点(或者说是单节点),只能是磁盘节点,否则RabbitMQ重启之后就啥也找不回了。
如果至少有一个磁盘节点,那么其他节点可以定义成内存节点。存储在内存节点的好处当然是为了提高访问速度。而磁盘节固然重要,也不是越多越好。因为每次变更metadata数据的时候,都需要将数据写入到磁盘节点,那么这个写入会拖慢集群的访问效率。
所以至少保持一个磁盘节点,那么一旦重启或者恢复,其他节点也能正常恢复metadata数据。
好了理论讲了半天,自己都觉得啰嗦,详细的内容还是看文档吧。
练习在本机搭建集群节点
这个集群不一定是要在多个服务器跑多个节点,一个服务器上也可以运行多个节点,可以理解为多个进程监听不同的端口号,并且节点的名称不同。我这里演示的是在一个服务器上运行多个节点。
仅仅是搭建集群节点命令很简单
1.首先确认安装好了RabbitMQ,然后停止默认启动的那个节点
sudo rabbitmqctl stop_app
sudo rabbitmqctl stop
2.然后依次执行以下三个命令,实际上是创建了三个节点,不同的端口号和节点名称
sudo RABBITMQ_NODENAME=rabbit RABBITMQ_NODE_PORT=5672 rabbitmq-server -detached
sudo RABBITMQ_NODENAME=rabbit_1 RABBITMQ_NODE_PORT=5673 rabbitmq-server -detached
sudo RABBITMQ_NODENAME=rabbit_2 RABBITMQ_NODE_PORT=5674 rabbitmq-server –detached
这里使用了两个环境变量,分别是RABBITMQ_NODENAME和RABBITMQ_NODE_PORT,也就是定义了节点名称和节点的监听端口号。
运行成功之后,就应该有三个节点在运行,可依次执行以下命令验证
sudo rabbitmqctl -n rabbit@bogon status
sudo rabbitmqctl -n rabbit_1@bogon status
sudo rabbitmqctl -n rabbit_2@bogon status
这里运行rabbitmqctl时指定了节点的名称-n,格式为:节点名@主机名, bogon是我的主机名,要根据实际情况修改。
3.形成集群
目前为止有三个节点,但是这三个节点是独立运行的,没有任何关联,下面来建立集群关系。
我们以第一个节点为metadata的提供节点,其他2个节点作为集群节点加入,也就是第2和第3个节点要得到第一个节点的metadata信息。
首先停止节点2
sudo rabbitmqctl -n rabbit_1@bogon stop_app
重置节点2的metadata
sudo rabbitmqctl -n rabbit_1@bogon reset
将节点2加入到节点1中
sudo rabbitmqctl -n rabbit_1@bogon join_cluster rabbit@bogon
(这里加入节点后,节点2将作为磁盘节点)
启动节点2
sudo rabbitmqctl -n rabbit_1@bogon start_app
查看节点2的集群状态
sudo rabbitmqctl -n rabbit_1@bogon cluster_status
输出如下信息
[{nodes,[{disc,[rabbit@bogon,rabbit_1@bogon]}]},
{running_nodes,[rabbit@bogon,rabbit_1@bogon]},
可以看到目前有两个节点,都是磁盘类型的节点,并且都在运行
继续加入节点3,前两部停止和重置一样,只是改个节点名称
sudo rabbitmqctl -n rabbit_2@bogon stop_app
sudo rabbitmqctl -n rabbit_2@bogon reset
将节点3加入到节点1,但是设置节点3位内存节点,注意最后的--ram参数
sudo rabbitmqctl -n rabbit_2@bogon join_cluster rabbit@bogon –ram
启动节点3并查看集群状态
sudo rabbitmqctl -n rabbit_2@bogon start_app
sudo rabbitmqctl -n rabbit_2@bogon cluster_status
输出信息如下
[{nodes,[{disc,[rabbit_1@bogon,rabbit@bogon]},{ram,[rabbit_2@bogon]}]},
{running_nodes,[rabbit@bogon,rabbit_1@bogon,rabbit_2@bogon]},
可以看到目前有三个节点,第三个节点是内存节点。
好了,到目前为此单机多节点就搭建完了,那有什么用呢?上述显示的running_nodes都是可以被连接的,最起码增加了连接数,也有个最起码的概念,接下来会整理如何将节点分布运行在不同的服务器。
RabbitMQ上手记录–part 4-节点集群(单机多节点)的更多相关文章
- 峰Redis学习(10)Redis 集群(单机多节点集群和多机多节点集群)
单机多节点集群:参考博客:http://blog.java1234.com/blog/articles/326.html 多机多节点集群:参考博客:http://blog.java1234.com/b ...
- RabbitMQ上手记录–part 5-节点集群高可用(多服务器)
上一part<RabbitMQ上手记录–part 4-节点集群(单机多节点)>中介绍了RabbitMQ集群的一些概念以及实现了在单机上运行多个节点,并且将多个节点组成一个集群. 通常情况下 ...
- 现有rabbitmq集群添加新节点,移除旧节点(可以作为rabbitmq集群迁移使用)
原有集群安装步骤:https://www.cnblogs.com/sanduzxcvbnm/p/15797788.html 1.拉取镜像 集群中新节点需要执行 docker pull rabbitmq ...
- RabbitMQ上手记录–part 6-Shovel
上一part<RabbitMQ上手记录–part 5-节点集群高可用(多服务器)>讲到了通过多个服务器来搭建RabbitMQ的节点集群,示例当中提到的服务器都是在同一个局域网中的(实际上是 ...
- RabbitMQ上手记录–part 2 - 安装RabbitMQ
上一篇<<RabbitMQ 上手记录-part 1>>介绍了一些基础知识,整理了一些基础概念.接下来整理一些安装步骤和遇到的问题. 我在CentOS7和Ubuntu16.4上都 ...
- RabbitMQ可靠性投递及高可用集群
可靠性投递: 首先需要明确,效率与可靠性是无法兼得的,如果要保证每一个环节都成功,势必会对消息的收发效率造成影响.如果是一些业务实时一致性要求不是特别高的场合,可以牺牲一些可靠性来换取效率. 要保证消 ...
- RabbitMQ上手记录–part 3-发送消息
接上一part<<RabbitMQ上手记录–part 2 - 安装RabbitMQ>>,这里我们来看看如何通过代码实现对RabbitMQ的调用. RabbitMQ通常是安装在服 ...
- RabbitMQ-rabbitmqctl多机多节点和单机多节点集群搭建(五)
准备 1.准备3台物理机 我这里通过本地机和2台虚拟模拟我是mac通过(Parallel Desktop 实现) 2.按照签名的liux安装步骤在3台机器都安装rabiitMq 3.将任意一节点的co ...
- 懒人记录 Hadoop2.7.1 集群搭建过程
懒人记录 Hadoop2.7.1 集群搭建过程 2016-07-02 13:15:45 总结 除了配置hosts ,和免密码互连之外,先在一台机器上装好所有东西 配置好之后,拷贝虚拟机,配置hosts ...
- 学习Hadoop+Spark大数据巨量分析与机器学习整合开发-windows利用虚拟机实现模拟多节点集群构建
记录学习<Hadoop+Spark大数据巨量分析与机器学习整合开发>这本书. 第五章 Hadoop Multi Node Cluster windows利用虚拟机实现模拟多节点集群构建 5 ...
随机推荐
- Linq to Object 的简单使用示例
语言集成查询 (LINQ) 是 Visual Studio 2008 中引入的一组功能,可为 C# 和 Visual Basic 语言语法提供强大的查询功能. LINQ 引入了标准易学的数据查询和更新 ...
- SQL触发器操作
Deleted表用于存储DELETE和UPDATE语句所影响的行的复本.在执行DELETE或UPDATE语句时,行从触发器表中删除,并传输到deleted表中.Deleted表和触发器表通常没有相同的 ...
- navigationController背景图,文字,事件定义
//设置背景图片 [self.navigationController.navigationBar setBackgroundImage:imag forBarMetrics:UIBarMetrics ...
- js获取select下拉框的value值和text文本值
介绍一种取下拉框值以及绑定下拉框数据的方法 这里用到的jquery-ui-multiselect插件 1.前台html代码 <span class="ModuleFormFiel ...
- Microsoft.Web.Infrastructure, Version=1.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad
Microsoft.Web.Infrastructure, Version=1.0.0.0, Culture=neutral, PublicKeyToken=31bf3856ad 方法一:安装单独组件 ...
- CentOS 安装 linux kernel 源码
原文链接:https://blog.csdn.net/qaz1qaz1qaz2/article/details/52825389 1.下载系统包yum install rpm-buildyum ins ...
- Spark MLlib中的OneHot哑变量实践
在机器学习中,线性回归和逻辑回归算是最基础入门的算法,很多书籍都把他们作为第一个入门算法进行介绍.除了本身的公式之外,逻辑回归和线性回归还有一些必须要了解的内容.一个很常用的知识点就是虚拟变量(也叫做 ...
- jvm高级特性(6)(线程的种类,调度,状态,安全程度,实现安全的方法,同步种类,锁优化,锁种类)
JVM高级特性与实践(十三):线程实现 与 Java线程调度 JVM高级特性与实践(十四):线程安全 与 锁优化 一. 线程的实现 线程其实是比进程更轻量级的调度执行单位. 线程的引入,可以把一个检查 ...
- python pip安装模块提示错误failed to create process
python pip安装模块提示错误failed to create process 原因: 报这个错误的原因,是因为python的目录名称或位置发生改动. 解决办法: 1.找到修改python所在的 ...
- Swinject 源码框架(三):Object Scopes
Object Scopes 指定了生成的实例在系统中是如何被共享的. 如何指定 scope container.register(Animal.self) { _ in Cat() } .inObje ...