高并发面试必问:分布式消息系统Kafka简介
- 降低系统组网复杂度。
- 降低编程复杂度,各个子系统不在是相互协商接口,各个子系统类似插口插在插座上,Kafka承担高速数据总线的作用。
- 同时为发布和订阅提供高吞吐量。据了解,Kafka每秒可以生产约25万消息(50 MB),每秒处理55万消息(110 MB)。
- 可进行持久化操作。将消息持久化到磁盘,因此可用于批量消费,例如ETL,以及实时应用程序。通过将数据持久化到硬盘以及replication防止数据丢失。
- 分布式系统,易于向外扩展。所有的producer、broker和consumer都会有多个,均为分布式的。无需停机即可扩展机器。
- 消息被处理的状态是在consumer端维护,而不是由server端维护。当失败时能自动平衡。
- 支持online和offline的场景。


- Topic:特指Kafka处理的消息源(feeds of messages)的不同分类。
- Partition:Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。
- Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发布一些消息。
- Producers:消息和数据生产者,向Kafka的一个topic发布消息的过程叫做producers。
- Consumers:消息和数据消费者,订阅topics并处理其发布的消息的过程叫做consumers。
- Broker:缓存代理,Kafka集群中的一台或多台服务器统称为broker。
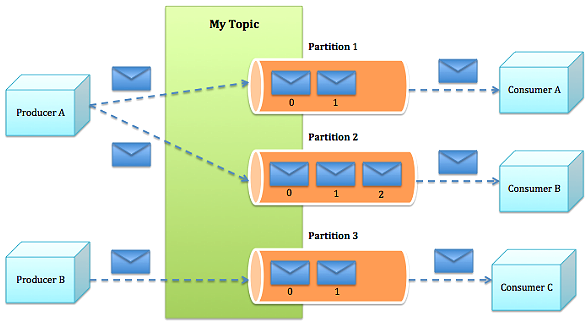

- Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里面
- kafka集群接收到Producer发过来的消息后,将其持久化到硬盘,并保留消息指定时长(可配置),而不关注消息是否被消费。
- Consumer从kafka集群pull数据,并控制获取消息的offset
- 数据磁盘持久化:消息不在内存中cache,直接写入到磁盘,充分利用磁盘的顺序读写性能
- zero-copy:减少IO操作步骤
- 数据批量发送
- 数据压缩
- Topic划分为多个partition,提高parallelism
- producer根据用户指定的算法,将消息发送到指定的partition
- 存在多个partiiton,每个partition有自己的replica,每个replica分布在不同的Broker节点上
- 多个partition需要选取出lead partition,lead partition负责读写,并由zookeeper负责fail over
- 通过zookeeper管理broker与consumer的动态加入与离开
- 简化kafka设计
- consumer根据消费能力自主控制消息拉取速度
- consumer根据自身情况自主选择消费模式,例如批量,重复消费,从尾端开始消费等
高并发面试必问:分布式消息系统Kafka简介的更多相关文章
- 分布式消息系统Kafka初步
终于可以写kafka的文章了,Mina的相关文章我已经做了索引,在我的博客中置顶了,大家可以方便的找到.从这一篇开始分布式消息系统的入门. 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到 ...
- 分布式消息系统kafka
kafka:一个分布式消息系统 1.背景 最近因为工作需要,调研了追求高吞吐的轻量级消息系统Kafka,打算替换掉线上运行的ActiveMQ,主要是因为明年的预算日流量有十亿,而ActiveMQ的分布 ...
- 分布式消息系统Kafka初步(一) (赞)
终于可以写kafka的文章了,Mina的相关文章我已经做了索引,在我的博客中置顶了,大家可以方便的找到.从这一篇开始分布式消息系统的入门. 在我们大量使用分布式数据库.分布式计算集群的时候,是否会遇到 ...
- 发布-订阅消息系统Kafka简介
转载请注明出处:http://www.cnblogs.com/BYRans/ Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的分布式 ...
- linux驱动工程面试必问知识点
linux内核原理面试必问(由易到难) 简单型 1:linux中内核空间及用户空间的区别?用户空间与内核通信方式有哪些? 2:linux中内存划分及如何使用?虚拟地址及物理地址的概念及彼此之间的转化, ...
- 互联网公司面试必问的Redis题目
Redis是一个非常火的非关系型数据库,火到什么程度呢?只要是一个互联网公司都会使用到.Redis相关的问题可以说是面试必问的,下面我从个人当面试官的经验,总结几个必须要掌握的知识点. 介绍:Redi ...
- 互联网公司面试必问的mysql题目(下)
这是mysql系列的下篇,上篇文章地址我附在文末. 什么是数据库索引?索引有哪几种类型?什么是最左前缀原则?索引算法有哪些?有什么区别? 索引是对数据库表中一列或多列的值进行排序的一种结构.一个非常恰 ...
- 互联网公司面试必问的mysql题目(上)
又到了招聘的旺季,被要求准备些社招.校招的题库.(如果你是应届生,尤其是东北的某大学,绝对福利哦) 介绍:MySQL是一个关系型数据库管理系统,目前属于 Oracle 旗下产品.虽然单机性能比不上or ...
- 分布式发布订阅消息系统 Kafka 架构设计[转]
分布式发布订阅消息系统 Kafka 架构设计 转自:http://www.oschina.net/translate/kafka-design 我们为什么要搭建该系统 Kafka是一个消息系统,原本开 ...
随机推荐
- node(2)
//app.js var express = require("express"); //以后的时后处理POST DELETE PATCH CHECKOUT 这些请求都可以用for ...
- jquery刷新页面的实现代码(局部及全页面刷新)
局部刷新: 这个方法就多了去了,常见的有以下几种: $.get方法,$.post方法,$.getJson方法,$.ajax方法如下 前两种使用方法基本上一样 下面介绍全页面刷新方法:有时候可能会用到 ...
- MYSQL 5.7 sqlmode 行为
最近碰到了sql_mode 的一些问题,故进行了研究,根据实际情况研究其行为. sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ER ...
- windows 下安装nodejs 要怎么设置环境变量
windows 下安装nodejs 了,也安装了npm, 但是有时候切不能直接用request(‘ws’)这一类的东西.我觉得是确实环境变量或其他设置有问题,能否给个完整的设置方案: 要设置两个东西, ...
- 全网数据定时备份方案[cron + rsync]
1.1.1. Rsync(远程同步)介绍 [Rsync等价scp cp rm共3个命令的和] 1.什么是Rsync: Linux下面开源的,很快,功能很多,可以实现全量及增量的本地或者远程数据同步 ...
- Test checkout of feature 'Compiler' failed 解决方法(转载)
Test checkout of feature 'Compiler' failed. 2014a的解决办法 适用于已安装compiler但破解不完全的, ht—tp://pan.baidu.co ...
- SQL server数据库的部署
一.实验目标 1.安装一台SQL SERVER(第一台),然后克隆再一台(第二台),一共两台,修改两台的主机和IP地址. 2.使用注册的方式,用第二台远程连接第一台 二.实验步骤 1)先打开一台Wi ...
- memcache分布式 存取
Memcached分布式 Memcached虽然称为“分布式“缓存服务器,但服务器端并没有“分布式”的功能.Memcached的分布式完全是由客户端实现的.memcached是怎么实现分布式缓存的呢? ...
- UE4中的AI行为树简单介绍
UE4引擎中可以实现简单AI的方式有很多,行为树是其中比较常用也很实用的AI控制方式,在官网的学习文档中也有最简单的目标跟踪AI操作教程,笔者在这里只作简单介绍. AIController->和 ...
- Spring 读取配置文件的俩种方式
读取配置可通过 org.springframework.core.env.Environment 类来获取, 也可以通过@Value的方式来获取 注解形式: @PropertySource({&quo ...