Netty源码分析第5章(ByteBuf)---->第2节: ByteBuf的分类
Netty源码分析第五章: ByteBuf
第二节: ByteBuf的分类
上一小节简单介绍了AbstractByteBuf这个抽象类, 这一小节对其子类的分类做一个简单的介绍
ByteBuf根据不同的分类方式, 会有不同的分类结果
我们首先看第一种分类方式:
1.Pooled和Unpooled:
pooled是从一块内存里去取一段连续内存封装成byteBuf
具体标志是类名以Pooled开头的ByteBuf, 通常就是Pooled类型的ByteBuf, 比如: PooledDirectByteBuf或者pooledHeapByteBuf
有关如何分配一块连续的内存, 我们之后的章节会讲到
Unpooled是分配的时候直接调用系统api进行实现, 具体标志是以Unpooled开头的ByteBuf, 比如UnpooledDirectByteBuf, UnpooledHeapByteBuf
再看第二种分类方式:
2.基于直接内存的ByteBuf和基于堆内存的ByteBuf
基于直接内存的ByteBuf, 具体标志是类名中包含单词Direct的ByteBuf, 比如UnpooledDirectByteBuf, PooledDirectByteBuf等
基于堆内存的ByteBuf, 具体标志是类名中包含单词heap的ByteBuf, 比如UnpooledHeapByteBuf, PooledHeapByteBuf
结合以上两种方式, 这里通过其创建的方式去简单对其分类做个解析
这里第一种分类的Pooled, 也就是分配一块连续内存创建byteBuf, 这一小节先不进行举例, 会在之后的小节讲到
这里主要就看Unpooled, 也就是调用系统api的方式创建byteBuf, 在直接内存和堆内存中有什么区别
这里以UnpooledDirectByteBuf和UnpooledHeapByteBuf这两种为例, 简单介绍其创建方式:
首先看UnpooledHeapByteBuf的byetBuf, 这是基于内存创建ByteBuf, 并且是直接调用系统api
我们看UnpooledHeapByteBuf的byetBuf的构造方法:
protected UnpooledHeapByteBuf(ByteBufAllocator alloc, int initialCapacity, int maxCapacity) {
this(alloc, new byte[initialCapacity], 0, 0, maxCapacity);
}
这里调用了自身的构造方法, 参数中创建了新的字节数组, 初始长度为初始化的内存大小, 读写指针初始位置都是0, 并传入了最大内存大小
从这里看出, 有关堆内存的Unpooled类型的分配, 是通过字节数组进行实现的
再往下跟:
protected UnpooledHeapByteBuf(ByteBufAllocator alloc, byte[] initialArray, int maxCapacity) {
this(alloc, initialArray, 0, initialArray.length, maxCapacity);
}
继续跟:
private UnpooledHeapByteBuf(
ByteBufAllocator alloc, byte[] initialArray, int readerIndex, int writerIndex, int maxCapacity) {
super(maxCapacity);
//忽略验证代码
this.alloc = alloc;
setArray(initialArray);
setIndex(readerIndex, writerIndex);
}
跟到setAarry方法中:
private void setArray(byte[] initialArray) {
array = initialArray;
tmpNioBuf = null;
}
将新创建的数组赋值为自身的array属性
回到构造函数中, 跟进setIndex方法:
public ByteBuf setIndex(int readerIndex, int writerIndex) {
//忽略验证代码
setIndex0(readerIndex, writerIndex);
return this;
}
这里实际上是调用了AbstractByteBuf的setIndex方法
我们跟进setIndex0方法中:
final void setIndex0(int readerIndex, int writerIndex) {
this.readerIndex = readerIndex;
this.writerIndex = writerIndex;
}
这里设置了读写指针, 根据之前的调用链我们知道, 这里将读写指针位置都设置为了0
介绍完UnpooledHeapByteBuf的初始化, 我们继续看UnpooledDirectByteBuf这个类的构造, 顾明思议, 是基于堆外内存, 并且同样也是调用系统api的方式进行实现的
我们看其构造方法:
protected UnpooledDirectByteBuf(ByteBufAllocator alloc, int initialCapacity, int maxCapacity) {
super(maxCapacity);
//忽略验证代码
this.alloc = alloc;
setByteBuffer(ByteBuffer.allocateDirect(initialCapacity));
}
我们关注下setByteBuffer中的参数ByteBuffer.allocateDirect(initialCapacity)
我们在这里看到, 这里通过jdk的ByteBuffer直接调用静态方法allocateDirect分配了一个基于直接内存的ByteBuffer, 并设置了初始内存
再跟到setByteBuffer方法中:
private void setByteBuffer(ByteBuffer buffer) {
ByteBuffer oldBuffer = this.buffer;
if (oldBuffer != null) {
//代码忽略
}
this.buffer = buffer;
tmpNioBuf = null;
capacity = buffer.remaining();
}
我们看到在这里将分配的ByteBuf设置到当前类的成员变量中
以上两种实例, 我们会对上面所讲到的两种分类有个初步的了解
这里要注意一下, 基于堆内存创建ByteBuf, 可以不用考虑对象回收, 因为虚拟机会进行垃圾回收, 但是堆外内存在虚拟机的垃圾回收机制的作用域之外, 所以这里要考虑手动回收对象
最后, 我们看第三种分类方式:
3.safe和unsafe
首先从名字上看, safe代表安全的, unsafe代表不安全的
这个安全与不安全的定义是什么呢
其实在我们jdk里面有unsafe对象, 可以通过unsafe对象直接拿到内存地址, 基于内存地址可以进行读写操作
如果是Usafe类型的byteBuf, 则可以直接拿到byteBuf在jvm中的具体内存, 可以通过调用jdk的Usafe对象进行读写, 所以这里代表不安全
而非Usafe不能拿到jvm的具体内存, 所以这里代表安全
具体标志是如果类名中包含unsafe这个单词的ByteBuf, 可以认为是一个unsafe类型的ByteBuf, 比如PooledUnsafeHeapByteBuf或者PooledUnsafeDirectByteBuf
以PooledUnsafeHeapByteBuf的_getByte方法为例:
protected byte _getByte(int index) {
return UnsafeByteBufUtil.getByte(memory, idx(index));
}
这里memory代表byebuffer底层分配内存的首地址, idx(index)代表当前指针index距内存memory的偏移地址, UnsafeByteBufUtil的getByte方法, 就可以直接通过这两个信息通过jdk底层的unsafe对象拿到jdk底层的值
有关AbstractByteBuf的主要实现类和继承关系, 如下图所示:
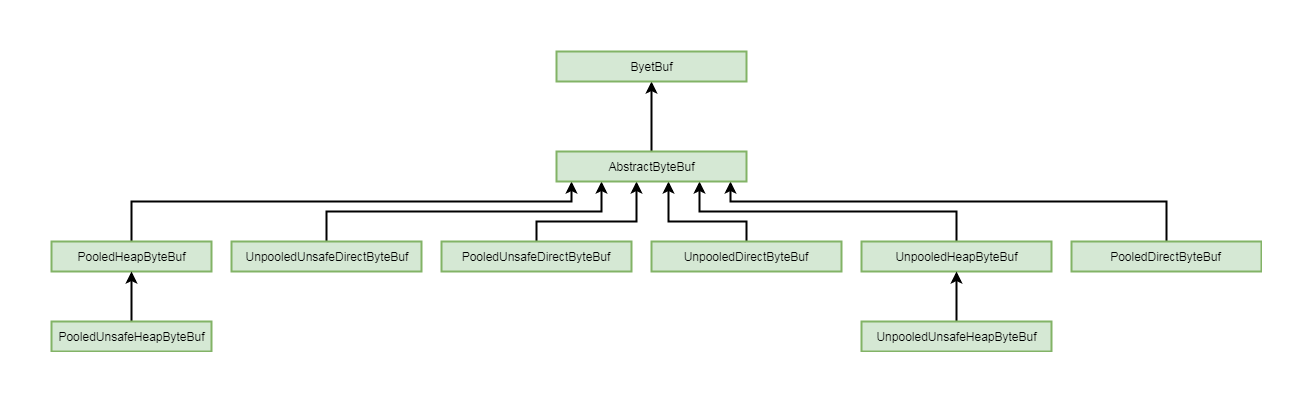
5-2-1
Netty源码分析第5章(ByteBuf)---->第2节: ByteBuf的分类的更多相关文章
- Netty源码分析第6章(解码器)---->第4节: 分隔符解码器
Netty源码分析第六章: 解码器 第四节: 分隔符解码器 基于分隔符解码器DelimiterBasedFrameDecoder, 是按照指定分隔符进行解码的解码器, 通过分隔符, 可以将二进制流拆分 ...
- Netty源码分析第4章(pipeline)---->第4节: 传播inbound事件
Netty源码分析第四章: pipeline 第四节: 传播inbound事件 有关于inbound事件, 在概述中做过简单的介绍, 就是以自己为基准, 流向自己的事件, 比如最常见的channelR ...
- Netty源码分析第4章(pipeline)---->第5节: 传播outbound事件
Netty源码分析第五章: pipeline 第五节: 传播outBound事件 了解了inbound事件的传播过程, 对于学习outbound事件传输的流程, 也不会太困难 在我们业务代码中, 有可 ...
- Netty源码分析第4章(pipeline)---->第6节: 传播异常事件
Netty源码分析第四章: pipeline 第6节: 传播异常事件 讲完了inbound事件和outbound事件的传输流程, 这一小节剖析异常事件的传输流程 首先我们看一个最最简单的异常处理的场景 ...
- Netty源码分析第4章(pipeline)---->第7节: 前章节内容回顾
Netty源码分析第四章: pipeline 第七节: 前章节内容回顾 我们在第一章和第三章中, 遗留了很多有关事件传输的相关逻辑, 这里带大家一一回顾 首先看两个问题: 1.在客户端接入的时候, N ...
- Netty源码分析第6章(解码器)---->第1节: ByteToMessageDecoder
Netty源码分析第六章: 解码器 概述: 在我们上一个章节遗留过一个问题, 就是如果Server在读取客户端的数据的时候, 如果一次读取不完整, 就触发channelRead事件, 那么Netty是 ...
- Netty源码分析第6章(解码器)---->第2节: 固定长度解码器
Netty源码分析第六章: 解码器 第二节: 固定长度解码器 上一小节我们了解到, 解码器需要继承ByteToMessageDecoder, 并重写decode方法, 将解析出来的对象放入集合中集合, ...
- Netty源码分析第6章(解码器)---->第3节: 行解码器
Netty源码分析第六章: 解码器 第三节: 行解码器 这一小节了解下行解码器LineBasedFrameDecoder, 行解码器的功能是一个字节流, 以\r\n或者直接以\n结尾进行解码, 也就是 ...
- Netty源码分析第4章(pipeline)---->第1节: pipeline的创建
Netty源码分析第四章: pipeline 概述: pipeline, 顾名思义, 就是管道的意思, 在netty中, 事件在pipeline中传输, 用户可以中断事件, 添加自己的事件处理逻辑, ...
- Netty源码分析第4章(pipeline)---->第2节: handler的添加
Netty源码分析第四章: pipeline 第二节: Handler的添加 添加handler, 我们以用户代码为例进行剖析: .childHandler(new ChannelInitialize ...
随机推荐
- 【转】[置顶] 在Android中显示GIF动画
gif图动画在Android中还是比较常用的,比如像新浪微博中,有很多gif图片,而且展示非常好,所以我也想弄一个.经过我多方的搜索资料和整理,终于弄出来了,其实github上有很多开源的gif的展示 ...
- C. Serval and Parenthesis Sequence 【括号匹配】 Codeforces Round #551 (Div. 2)
冲鸭,去刷题:http://codeforces.com/contest/1153/problem/C C. Serval and Parenthesis Sequence time limit pe ...
- Fluent Terminal
特性: PowerShell,CMD,WSL或自定义shell的终端 支持选项卡和多个窗口 主题和外观配置 导入/导出主题 导入iTerm主题 全屏模式 可编辑的键绑定 搜索功能 配置shell配置文 ...
- 论文笔记 M. Saquib Sarfraz_Pose-Sensitive Embedding_re-ranking_2018_CVPR
1. 摘要 作者使用一个pose-sensitive-embddding,把姿态的粗糙.精细信息结合在一起应用到模型中. 用一个新的re-ranking方法,不需要重新计算新的ranking列表,是一 ...
- nagios-4.0.8 安装部署
1.Nagios工作原理 Nagios周期性调用插件检测服务器状态,并维持一个队列,所有插件返回状态信息都进入队列,Nagios每次从队首开始读取信息,并把状态通过web显示. 安装完成后,在nagi ...
- ios宏定义学习
宏简介: 宏是一种批量处理的称谓.一般说来,宏是一种规则或模式,或称语法替换 ,用于说明某一特定输入(通常是字符串)如何根据预定义的规则转换成对应的输出(通常也是字符串).这种替换在预编译时进行,称作 ...
- C 和 Object-C中的 #ifdef #ifndef
很多宏是为了进行条件编译.一般情况下,源程序中所有的行都参加编译.但是有时希望对其中一部分内容只在满足一定条件才进行编译,也就是对一部分内容指定编译的条件,这就是“条件编译”.有时,希望当满足某条件时 ...
- Xamarin 编写混合APP趟坑记录(二)
前言 公司要开发一个App,为了便于维护和更新,而不用每次去苹果审核,采用的是混合开发方式:用WebVie+WebApp的方式. 因为本人不会Java和ObjectC,公司又不想花钱招这两个岗位的人, ...
- 腾讯云Mac图床插件
背景 随着博客越写越多,难免会遇到需要插入图片来说明的情况. 图床选择 首先调研了市面上的图床服务,本着稳定长期的目标,过滤掉了打一枪换一个地方的野鸡小网站,剩余比较靠谱的优缺点如下. 图床 优点 缺 ...
- 一、Delphi中Cxgrid表格滚动条粗细设置
1.Delphi VCL新版本的Cxgrid滚动条默认是触屏模式(如下图),很细的滚动条,在电脑版显示非常不方便. 2.如果需要改成传统的滚动条模式,需要设置一下LookAndFeel里面的Scrol ...