Netty源码分析第5章(ByteBuf)---->第2节: ByteBuf的分类
Netty源码分析第五章: ByteBuf
第二节: ByteBuf的分类
上一小节简单介绍了AbstractByteBuf这个抽象类, 这一小节对其子类的分类做一个简单的介绍
ByteBuf根据不同的分类方式, 会有不同的分类结果
我们首先看第一种分类方式:
1.Pooled和Unpooled:
pooled是从一块内存里去取一段连续内存封装成byteBuf
具体标志是类名以Pooled开头的ByteBuf, 通常就是Pooled类型的ByteBuf, 比如: PooledDirectByteBuf或者pooledHeapByteBuf
有关如何分配一块连续的内存, 我们之后的章节会讲到
Unpooled是分配的时候直接调用系统api进行实现, 具体标志是以Unpooled开头的ByteBuf, 比如UnpooledDirectByteBuf, UnpooledHeapByteBuf
再看第二种分类方式:
2.基于直接内存的ByteBuf和基于堆内存的ByteBuf
基于直接内存的ByteBuf, 具体标志是类名中包含单词Direct的ByteBuf, 比如UnpooledDirectByteBuf, PooledDirectByteBuf等
基于堆内存的ByteBuf, 具体标志是类名中包含单词heap的ByteBuf, 比如UnpooledHeapByteBuf, PooledHeapByteBuf
结合以上两种方式, 这里通过其创建的方式去简单对其分类做个解析
这里第一种分类的Pooled, 也就是分配一块连续内存创建byteBuf, 这一小节先不进行举例, 会在之后的小节讲到
这里主要就看Unpooled, 也就是调用系统api的方式创建byteBuf, 在直接内存和堆内存中有什么区别
这里以UnpooledDirectByteBuf和UnpooledHeapByteBuf这两种为例, 简单介绍其创建方式:
首先看UnpooledHeapByteBuf的byetBuf, 这是基于内存创建ByteBuf, 并且是直接调用系统api
我们看UnpooledHeapByteBuf的byetBuf的构造方法:
protected UnpooledHeapByteBuf(ByteBufAllocator alloc, int initialCapacity, int maxCapacity) {
this(alloc, new byte[initialCapacity], 0, 0, maxCapacity);
}
这里调用了自身的构造方法, 参数中创建了新的字节数组, 初始长度为初始化的内存大小, 读写指针初始位置都是0, 并传入了最大内存大小
从这里看出, 有关堆内存的Unpooled类型的分配, 是通过字节数组进行实现的
再往下跟:
protected UnpooledHeapByteBuf(ByteBufAllocator alloc, byte[] initialArray, int maxCapacity) {
this(alloc, initialArray, 0, initialArray.length, maxCapacity);
}
继续跟:
private UnpooledHeapByteBuf(
ByteBufAllocator alloc, byte[] initialArray, int readerIndex, int writerIndex, int maxCapacity) {
super(maxCapacity);
//忽略验证代码
this.alloc = alloc;
setArray(initialArray);
setIndex(readerIndex, writerIndex);
}
跟到setAarry方法中:
private void setArray(byte[] initialArray) {
array = initialArray;
tmpNioBuf = null;
}
将新创建的数组赋值为自身的array属性
回到构造函数中, 跟进setIndex方法:
public ByteBuf setIndex(int readerIndex, int writerIndex) {
//忽略验证代码
setIndex0(readerIndex, writerIndex);
return this;
}
这里实际上是调用了AbstractByteBuf的setIndex方法
我们跟进setIndex0方法中:
final void setIndex0(int readerIndex, int writerIndex) {
this.readerIndex = readerIndex;
this.writerIndex = writerIndex;
}
这里设置了读写指针, 根据之前的调用链我们知道, 这里将读写指针位置都设置为了0
介绍完UnpooledHeapByteBuf的初始化, 我们继续看UnpooledDirectByteBuf这个类的构造, 顾明思议, 是基于堆外内存, 并且同样也是调用系统api的方式进行实现的
我们看其构造方法:
protected UnpooledDirectByteBuf(ByteBufAllocator alloc, int initialCapacity, int maxCapacity) {
super(maxCapacity);
//忽略验证代码
this.alloc = alloc;
setByteBuffer(ByteBuffer.allocateDirect(initialCapacity));
}
我们关注下setByteBuffer中的参数ByteBuffer.allocateDirect(initialCapacity)
我们在这里看到, 这里通过jdk的ByteBuffer直接调用静态方法allocateDirect分配了一个基于直接内存的ByteBuffer, 并设置了初始内存
再跟到setByteBuffer方法中:
private void setByteBuffer(ByteBuffer buffer) {
ByteBuffer oldBuffer = this.buffer;
if (oldBuffer != null) {
//代码忽略
}
this.buffer = buffer;
tmpNioBuf = null;
capacity = buffer.remaining();
}
我们看到在这里将分配的ByteBuf设置到当前类的成员变量中
以上两种实例, 我们会对上面所讲到的两种分类有个初步的了解
这里要注意一下, 基于堆内存创建ByteBuf, 可以不用考虑对象回收, 因为虚拟机会进行垃圾回收, 但是堆外内存在虚拟机的垃圾回收机制的作用域之外, 所以这里要考虑手动回收对象
最后, 我们看第三种分类方式:
3.safe和unsafe
首先从名字上看, safe代表安全的, unsafe代表不安全的
这个安全与不安全的定义是什么呢
其实在我们jdk里面有unsafe对象, 可以通过unsafe对象直接拿到内存地址, 基于内存地址可以进行读写操作
如果是Usafe类型的byteBuf, 则可以直接拿到byteBuf在jvm中的具体内存, 可以通过调用jdk的Usafe对象进行读写, 所以这里代表不安全
而非Usafe不能拿到jvm的具体内存, 所以这里代表安全
具体标志是如果类名中包含unsafe这个单词的ByteBuf, 可以认为是一个unsafe类型的ByteBuf, 比如PooledUnsafeHeapByteBuf或者PooledUnsafeDirectByteBuf
以PooledUnsafeHeapByteBuf的_getByte方法为例:
protected byte _getByte(int index) {
return UnsafeByteBufUtil.getByte(memory, idx(index));
}
这里memory代表byebuffer底层分配内存的首地址, idx(index)代表当前指针index距内存memory的偏移地址, UnsafeByteBufUtil的getByte方法, 就可以直接通过这两个信息通过jdk底层的unsafe对象拿到jdk底层的值
有关AbstractByteBuf的主要实现类和继承关系, 如下图所示:
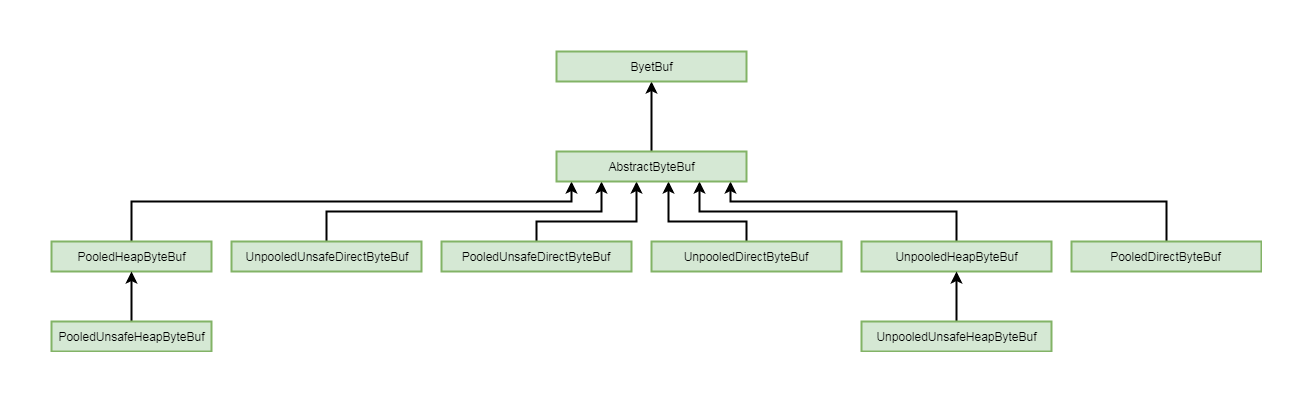
5-2-1
Netty源码分析第5章(ByteBuf)---->第2节: ByteBuf的分类的更多相关文章
- Netty源码分析第6章(解码器)---->第4节: 分隔符解码器
Netty源码分析第六章: 解码器 第四节: 分隔符解码器 基于分隔符解码器DelimiterBasedFrameDecoder, 是按照指定分隔符进行解码的解码器, 通过分隔符, 可以将二进制流拆分 ...
- Netty源码分析第4章(pipeline)---->第4节: 传播inbound事件
Netty源码分析第四章: pipeline 第四节: 传播inbound事件 有关于inbound事件, 在概述中做过简单的介绍, 就是以自己为基准, 流向自己的事件, 比如最常见的channelR ...
- Netty源码分析第4章(pipeline)---->第5节: 传播outbound事件
Netty源码分析第五章: pipeline 第五节: 传播outBound事件 了解了inbound事件的传播过程, 对于学习outbound事件传输的流程, 也不会太困难 在我们业务代码中, 有可 ...
- Netty源码分析第4章(pipeline)---->第6节: 传播异常事件
Netty源码分析第四章: pipeline 第6节: 传播异常事件 讲完了inbound事件和outbound事件的传输流程, 这一小节剖析异常事件的传输流程 首先我们看一个最最简单的异常处理的场景 ...
- Netty源码分析第4章(pipeline)---->第7节: 前章节内容回顾
Netty源码分析第四章: pipeline 第七节: 前章节内容回顾 我们在第一章和第三章中, 遗留了很多有关事件传输的相关逻辑, 这里带大家一一回顾 首先看两个问题: 1.在客户端接入的时候, N ...
- Netty源码分析第6章(解码器)---->第1节: ByteToMessageDecoder
Netty源码分析第六章: 解码器 概述: 在我们上一个章节遗留过一个问题, 就是如果Server在读取客户端的数据的时候, 如果一次读取不完整, 就触发channelRead事件, 那么Netty是 ...
- Netty源码分析第6章(解码器)---->第2节: 固定长度解码器
Netty源码分析第六章: 解码器 第二节: 固定长度解码器 上一小节我们了解到, 解码器需要继承ByteToMessageDecoder, 并重写decode方法, 将解析出来的对象放入集合中集合, ...
- Netty源码分析第6章(解码器)---->第3节: 行解码器
Netty源码分析第六章: 解码器 第三节: 行解码器 这一小节了解下行解码器LineBasedFrameDecoder, 行解码器的功能是一个字节流, 以\r\n或者直接以\n结尾进行解码, 也就是 ...
- Netty源码分析第4章(pipeline)---->第1节: pipeline的创建
Netty源码分析第四章: pipeline 概述: pipeline, 顾名思义, 就是管道的意思, 在netty中, 事件在pipeline中传输, 用户可以中断事件, 添加自己的事件处理逻辑, ...
- Netty源码分析第4章(pipeline)---->第2节: handler的添加
Netty源码分析第四章: pipeline 第二节: Handler的添加 添加handler, 我们以用户代码为例进行剖析: .childHandler(new ChannelInitialize ...
随机推荐
- 学习python第四天——Oracle分组
1.分组的概念: 关键字:group by子句 结论:在select列表中如果出现了聚合函数,不是聚合函数的列,必须都要定义到group by子句的后面 需求: 查询公司各个部门的平均工资? sele ...
- 关于前端惰性加载(jquery_lazyload)的使用和原理分析
1.前言 有时我们会有这样的需求,当网页有很多张图片的时候,我们不希望一次性就把图片加载完,而是希望当浏览器滑动到指定位置的时候再加载,这样可以节省带宽,它也能帮助减轻服务器负载.那么这种需求就需要利 ...
- golang xorm应用
github.com/go-xorm/xorm xorm库 http://www.xorm.io/docs/ 手册 xorm是一个简单而强大的Go语言ORM库. 通过它可以使数据库操作非常简便.xo ...
- virtualbox迁移已建虚机存储磁盘方法
1. 先关闭虚拟机 2. 将虚拟机的磁盘拷贝或移动到想要存储的位置,virtualbox一般为.vdi文件(虚拟磁盘文件) 3. vboxmanage internalcommands sethduu ...
- PHP常用功能块_错误和异常处理 — php(32)
一.错误和异常处理 1.1 错误类型和基本的调试方法PHP程序的错误发生一般归属于下列三个领域: 语法错误:语法错误最常见,并且也容易修复.如:代码中遗漏一个分号.这类错误会阻止脚本的执行. 运行时错 ...
- 关于SpringApplication包无法导入报错问题
问题描述:一直再报红线,包始终无法导入,参考过好几个博友分享的解决方案,依然没有效果,对了补充一点SprinBoot版本为2.0.3. 问题解决:目前通过更换版本得到解决1.5.6或者1.5.8都可以 ...
- TensorFlow Activation Function 1
部分转自:https://blog.csdn.net/caicaiatnbu/article/details/72745156 激活函数(Activation Function)运行时激活神经网络中某 ...
- CAN网要不要共地?
重要:CAN网要不要共地? 因为CAN传输采用差分传输的方式,即使不共地,部分情况下仍然能传输数据,但是本人以实际的经验告诉你们,一定要共地! 1. 不共地会引入共模干扰,轻则影响正常 ...
- Linux Shell常用技巧(五)
十一. awk编程: 1. 变量: 在awk中变量无须定义即可使用,变量在赋值时即已经完成了定义.变量的类型可以是数字.字符串.根据使用的不同,未初始化变量的值为0或空白字符串&quo ...
- 【LeetCode415】Add Strings
题目描述: 解决思路: 此题较简单,和前面[LeetCode67]方法一样. Java代码: public class LeetCode415 { public static void main(St ...