Hadoop学习之路(十二)分布式集群中HDFS系统的各种角色
NameNode
学习目标
理解 namenode 的工作机制尤其是元数据管理机制,以增强对 HDFS 工作原理的 理解,及培养 hadoop 集群运营中“性能调优”、“namenode”故障问题的分析解决能力
问题场景
1、Namenode 服务器的磁盘故障导致 namenode 宕机,如何挽救集群及数据?
2、Namenode 是否可以有多个?namenode 内存要配置多大?namenode 跟集群数据存储能 力有关系吗?
3、文件的 blocksize 究竟调大好还是调小好?结合 mapreduce
NameNode的职责
1、负责客户端请求(读写数据 请求 )的响应
2、维护目录树结构( 元数据的管理: 查询,修改 )
3、配置和应用副本存放策略
4、管理集群数据块负载均衡问题
NameNode元数据的管理
WAL(Write ahead Log): 预写日志系统
在计算机科学中,预写式日志(Write-ahead logging,缩写 WAL)是关系数据库系统中 用于提供原子性和持久性(ACID 属性中的两个)的一系列技术。在使用 WAL 的系统中,所 有的修改在提交之前都要先写入 log 文件中。
Log 文件中通常包括 redo 和 undo 信息。这样做的目的可以通过一个例子来说明。假设 一个程序在执行某些操作的过程中机器掉电了。在重新启动时,程序可能需要知道当时执行 的操作是成功了还是部分成功或者是失败了。如果使用了 WAL,程序就可以检查 log 文件, 并对突然掉电时计划执行的操作内容跟实际上执行的操作内容进行比较。在这个比较的基础 上,程序就可以决定是撤销已做的操作还是继续完成已做的操作,或者是保持原样。
WAL 允许用 in-place 方式更新数据库。另一种用来实现原子更新的方法是 shadow paging, 它并不是 in-place 方式。用 in-place 方式做更新的主要优点是减少索引和块列表的修改。ARIES 是 WAL 系列技术常用的算法。在文件系统中,WAL 通常称为 journaling。PostgreSQL 也是用 WAL 来提供 point-in-time 恢复和数据库复制特性。
NameNode 对数据的管理采用了两种存储形式:内存和磁盘
首先是内存中存储了一份完整的元数据,包括目录树结构,以及文件和数据块和副本存储地 的映射关系;
1、内存元数据 metadata(全部存在内存中),其次是在磁盘中也存储了一份完整的元数据。
2、磁盘元数据镜像文件 fsimage_0000000000000000555
fsimage_0000000000000000555 等价于
edits_0000000000000000001-0000000000000000018
……
edits_0000000000000000444-0000000000000000555
合并之和
3、数据历史操作日志文件 edits:edits_0000000000000000001-0000000000000000018 (可通过日志运算出元数据,全部存在磁盘中)
4、数据预写操作日志文件 edits_inprogress_0000000000000000556 (存储在磁盘中)
metadata = 最新 fsimage_0000000000000000555 + edits_inprogress_0000000000000000556
metadata = 所有的 edits 之和(edits_001_002 + …… + edits_444_555 + edits_inprogress_556)
VERSION(存放 hdfs 集群的版本信息)文件解析:
#Sun Jan :: CST ## 集群启动时间
namespaceID= ## 文件系统唯一标识符
clusterID=CID-5b7b7321-e43f-456e-bf41-18e77c5e5a40 ## 集群唯一标识符
cTime= ## fsimage 创建的时间,初始为 ,随 layoutVersion 更新
storageType=NAME_NODE ##节点类型
blockpoolID=BP--192.168.123.202- ## 数据块池 ID,可以有多个
layoutVersion=- ## hdfs 持久化数据结构的版本号
查看 edits 文件信息:
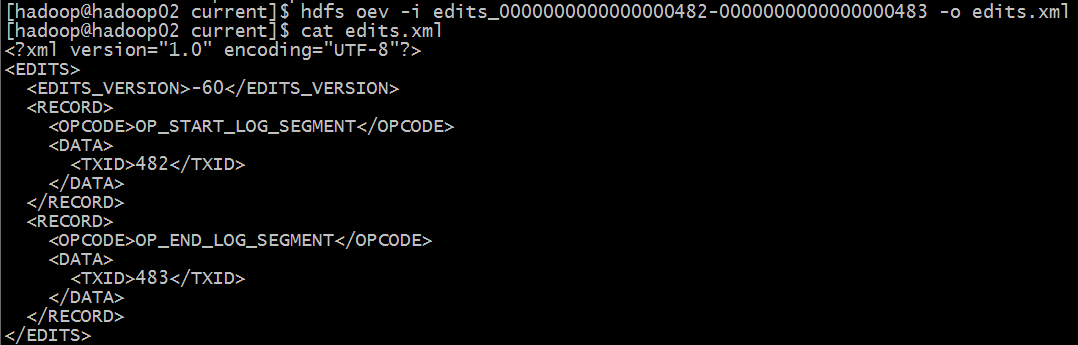
hdfs oev -i edits_0000000000000000482- -o edits.xml
cat edits.xml
查看 fsimage 镜像文件信息:
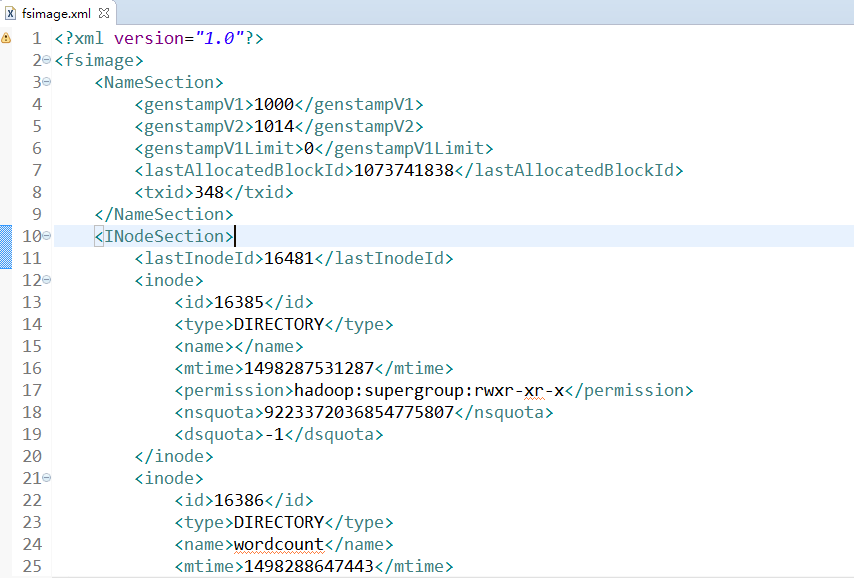
hdfs oiv -i fsimage_0000000000000000348 -p XML -o fsimage.xml
cat fsimage.xml
NameNode 元数据存储机制
A、内存中有一份完整的元数据(内存 metadata)
B、磁盘有一个“准完整”的元数据镜像(fsimage)文件(在 namenode 的工作目录中)
C、用于衔接内存 metadata 和持久化元数据镜像 fsimage 之间的操作日志(edits 文件)
(PS:当客户端对 hdfs 中的文件进行新增或者修改操作,操作记录首先被记入 edits 日志 文件中,当客户端操作成功后,相应的元数据会更新到内存 metadata 中)
DataNode
问题场景
1、集群容量不够,怎么扩容?
2、如果有一些 datanode 宕机,该怎么办?
3、datanode 明明已启动,但是集群中的可用 datanode 列表中就是没有,怎么办?
Datanode 工作职责
1、存储管理用户的文件块数据
2、定期向 namenode 汇报自身所持有的 block 信息(通过心跳信息上报)
(PS:这点很重要,因为,当集群中发生某些 block 副本失效时,集群如何恢复 block 初始 副本数量的问题)
<property>
<!—HDFS 集群数据冗余块的自动删除时长,单位 ms,默认一个小时 -->
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
Datanode 掉线判断时限参数
datanode 进程死亡或者网络故障造成 datanode 无法与 namenode 通信,namenode 不会立即 把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS 默认的超时时长 为 10 分钟+30 秒。如果定义超时时间为 timeout,则超时时长的计算公式为: t
imeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval
而默认的 heartbeat.recheck.interval 大小为 5 分钟,dfs.heartbeat.interval 默认为 3 秒。 需要注意的是 hdfs-site.xml 配置文件中的 heartbeat.recheck.interval 的单位为毫秒, dfs.heartbeat.interval 的单位为秒。 所以,举个例子,如果 heartbeat.recheck.interval 设置为 5000(毫秒),dfs.heartbeat.interval 设置为 3(秒,默认),则总的超时时间为 40 秒。
<property>
<name>heartbeat.recheck.interval</name>
<value>5000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
SecondaryNameNode
SecondaryNamenode 工作机制
SecondaryNamenode 的作用就是分担 namenode 的合并元数据的压力。所以在配置 SecondaryNamenode 的工作节点时,一定切记,不要和 namenode 处于同一节点。但事实上, 只有在普通的伪分布式集群和分布式集群中才有会 SecondaryNamenode 这个角色,在 HA 或 者联邦集群中都不再出现该角色。在 HA 和联邦集群中,都是有 standby namenode 承担。
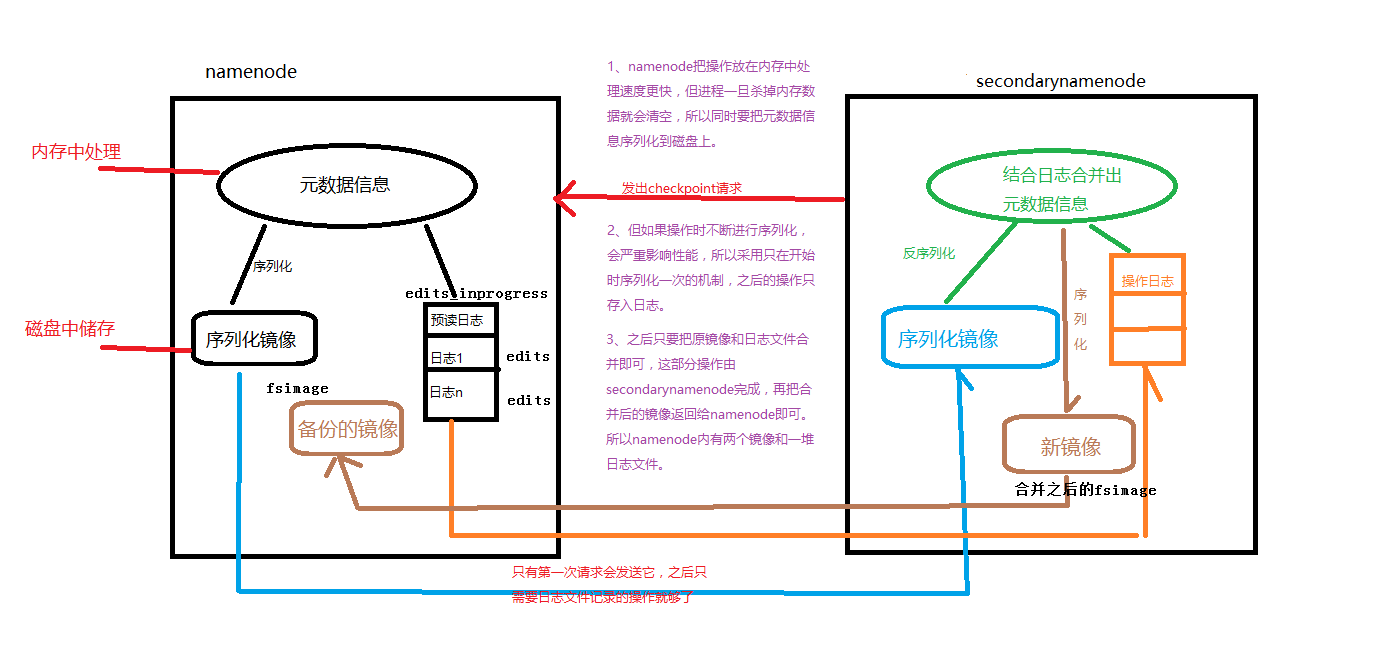
元数据的 CheckPoint
每隔一段时间,会由 secondary namenode 将 namenode 上积累的所有 edits 和一个最新的 fsimage 下载到本地,并加载到内存进行 merge(这个过程称为 checkpoint) CheckPoint 详细过程图解:
CheckPoint 触发配置
dfs.namenode.checkpoint.check.period=60 ##检查触发条件是否满足的频率,60 秒
dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary
##以上两个参数做 checkpoint 操作时,secondary namenode 的本地工作目录
dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir}
dfs.namenode.checkpoint.max-retries=3 ##最大重试次数
dfs.namenode.checkpoint.period=3600 ##两次 checkpoint 之间的时间间隔 3600 秒
dfs.namenode.checkpoint.txns=1000000 ##两次 checkpoint 之间最大的操作记录
CheckPoint 附带作用
Namenode 和 SecondaryNamenode 的工作目录存储结构完全相同,所以,当 Namenode 故障 退出需要重新恢复时,可以从SecondaryNamenode的工作目录中将fsimage拷贝到Namenode 的工作目录,以恢复 namenode 的元数据
Hadoop学习之路(十二)分布式集群中HDFS系统的各种角色的更多相关文章
- Hadoop(五)分布式集群中HDFS系统的各种角色
NameNode 学习目标 理解 namenode 的工作机制尤其是元数据管理机制,以增强对 HDFS 工作原理的 理解,及培养 hadoop 集群运营中“性能调优”.“namenode”故障问题的分 ...
- Hadoop 学习之路(二)—— 集群资源管理器 YARN
一.hadoop yarn 简介 Apache YARN (Yet Another Resource Negotiator) 是hadoop 2.0 引入的集群资源管理系统.用户可以将各种服务框架部署 ...
- Zookeeper学习之路 (二)集群搭建
ZooKeeper 软件安装须知 鉴于 ZooKeeper 本身的特点,服务器集群的节点数推荐设置为奇数台.我这里我规划为三台, 为别为 hadoop1,hadoop2,hadoop3 ZooKeep ...
- Hadoop学习之路(二十三)MapReduce中的shuffle详解
概述 1.MapReduce 中,mapper 阶段处理的数据如何传递给 reducer 阶段,是 MapReduce 框架中 最关键的一个流程,这个流程就叫 Shuffle 2.Shuffle: 数 ...
- Hadoop学习笔记—13.分布式集群中节点的动态添加与下架
开篇:在本笔记系列的第一篇中,我们介绍了如何搭建伪分布与分布模式的Hadoop集群.现在,我们来了解一下在一个Hadoop分布式集群中,如何动态(不关机且正在运行的情况下)地添加一个Hadoop节点与 ...
- Hadoop学习之路(二)Hadoop发展背景
Hadoop产生的背景 1. HADOOP最早起源于Nutch.Nutch的设计目标是构建一个大型的全网搜索引擎,包括网页抓取.索引.查询等功能,但随着抓取网页数量的增加,遇到了严重的可扩展性问题—— ...
- Hadoop学习之路(二)HDFS基础
1.HDFS前言 HDFS:Hadoop Distributed File System,Hadoop分布式文件系统,主要用来解决海量数据的存储问题. 设计思想 分散均匀存储 dfs.blocksiz ...
- Hadoop上路-01_Hadoop2.3.0的分布式集群搭建
一.配置虚拟机软件 下载地址:https://www.virtualbox.org/wiki/downloads 1.虚拟机软件设定 1)进入全集设定 2)常规设定 2.Linux安装配置 1)名称类 ...
- zookeeper学习与实战(二)集群部署
上一篇介绍了单机版zookeeper安装,这种情况一般用于开发测试.如果是生产环境建议用分布式集群部署,防止单点故障,增加zookeeper服务的高可用. [环境介绍] 三台机器:192. ...
随机推荐
- java利器------反射机制
java反射的概念:java的反射机制是指在运行状态下,对于一个类来说,可以得到这个类的所有方法和属性.对于一个对象来说,可以调用这个对象的人和方法和属性. 反射机制首先会拿到该类的字节码文件(Cla ...
- 个人遗漏知识的回顾-HTML
常用的一些快捷键: Windows + e 我的电脑Ctrl + Tab 网页间不同页面切换F2 重命名Ctrl+Shift+S 另存为 前端的一些常识:前端意义:将效果图生成网页网页组成:文字.图片 ...
- Hackerrank GCD Product(莫比乌斯反演)
题意 题目链接 Sol 一道咕咕咕了好长时间的题 题解可以看这里 #include<bits/stdc++.h> #define LL long long using namespace ...
- p2p状态码
因为需要的确定状态太多,减少数据库的压力,采取二进制表示状态码 状态码工具类 package com.xmg.p2p.base.util; /** * 用户状态类,记录用户在平台使用系统中所有的状态. ...
- Ubuntu VNC 打开spyder无法输入(检测不到键盘配置)解决方法
在ubuntu中安装好spyder后, 打开spyder发现无法输入. 在打开spyder的终端窗口,有如下提示: QXcbConnection: Failed to initialize XRand ...
- eclipse中DDMS 视图中sdcard中文件导入的处理
首先需要说明下,这里说的sdcard的权限并不是指在Android application程序中设置sdcard的权限读 取问题.而是指在DDMS看到的目录下的那个sdcard目录的权限问题. ...
- ES6-Function
Function 箭头函数 ES6中对于函数的扩展最吸引人的莫过于箭头函数啦,不多说,先学会再说. 函数体内的this对象,是定义时所在的对象,而不是使用时所在的对象,这个特性与正常函数不同. // ...
- 观察者模式 - Java 实现1(使用JDK内置的Observer模式)
使用JDK内置的观察者模式 1. 可观察者(主题) 被观察的主题继承 Observable 对象, 使用该对象的调用 notifyObservers() 或 notifyObservers(arg) ...
- nginx 的socket 选项处理--TCP_DEFER_ACCEPT
在nginx listen配置项的说明中有一个选项: deferred -- indicates to use that postponed accept(2) on Linux with. the ...
- SQL Server ->> 数据类型不一致比较时的隐式转换
当使用操作符进行比较的时候,两边数据类型不一致的情况下,数据类型优先级别低的会往优先级别高的发生隐式转换.下面的参考链接是优先级别列表. 参考: Data Type Precedence (Trans ...