【OpenCV】opencv3.0中的SVM训练 mnist 手写字体识别
前言:
SVM(支持向量机)一种训练分类器的学习方法
mnist 是一个手写字体图像数据库,训练样本有60000个,测试样本有10000个
LibSVM 一个常用的SVM框架
OpenCV3.0 中的ml包含了很多的ML框架接口,就试试了。
详细的OpenCV文档:http://docs.opencv.org/3.0-beta/doc/tutorials/ml/introduction_to_svm/introduction_to_svm.html
mnist数据下载:http://yann.lecun.com/exdb/mnist/
LibSVM下载:http://www.csie.ntu.edu.tw/~cjlin/libsvm/
========================我是分割线=============================
训练的过程大致如下:
1. 读取mnist训练集数据
2. 训练
3. 读取mnist测试数据,对比预测结果,得到错误率
具体实现:
1. mnist给出的数据文件是二进制文件
四个文件,解压后如下
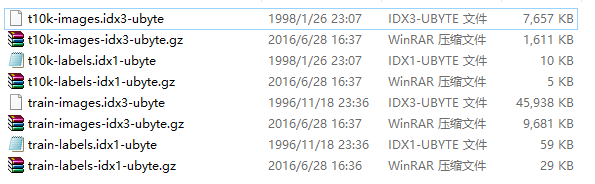
"train-images.idx3-ubyte" 二进制文件,存储了头文件信息以及60000张28*28图像pixel信息(用于训练)
"train-labels.idx1-ubyte" 二进制文件,存储了头文件信息以及60000张图像label信息
"t10k-images.idx3-ubyte"二进制文件,存储了头文件信息以及10000张28*28图像pixel信息(用于测试)
"t10k-labels.idx1-ubyte"二进制文件,存储了头文件信息以及10000张图像label信息
因为OpenCV中没有直接导入MINST数据的文件,所以需要自己写函数来读取
首先要知道,MNIST数据的数据格式

IMAGE FILE包含四个int型的头部数据(magic number,number_of_images, number_of_rows, number_of_columns)
余下的每一个byte表示一个pixel的数据,范围是0-255(可以在读入的时候scale到0~1的区间)
LABEL FILE包含两个int型的头部数据(magic number, number of items)
余下的每一个byte表示一个label数据,范围是0-9
注意(第一个坑):MNIST是大端存储,然而大部分的Intel处理器都是小端存储,所以对于int、long、float这些多字节的数据类型,就要一个一个byte地翻转过来,才能正确显示。
//翻转
int reverseInt(int i) {
unsigned char c1, c2, c3, c4; c1 = i & ;
c2 = (i >> ) & ;
c3 = (i >> ) & ;
c4 = (i >> ) & ; return ((int)c1 << ) + ((int)c2 << ) + ((int)c3 << ) + c4;
}
然后读取MNIST文件,但是它是二进制文件,打开方式
所以不能用
ifstream file(fileName);
而要改成
ifstream file(fileName, ios::binary);
注意(第二个坑):如果用第一条指令来打开文件,不会报错,但是数据会出现错误,头部数据仍然正确,但是后面的pixel数据大部分都是0,我刚开始没注意,开始training的时候发现等了很久...真的是很久...(7+ hours)...估计是达到迭代终止的最大次数了,才停下来的
嗯,stack overflow上也有类似的提问:

注意(第三个坑):
training时,IMAGE和LABEL的数据分别都放进一个MAT中存储,但是只能是CV32_F或者CV32_S的格式,不然会assertion报错
OPENCV给出的文档中,例子是这样的:(但是predict的时候又会要求label的格式是unsigned int)所以...可以设置data的Mat格式为CV_32FC1,label的Mat格式为CV_32SC1

顺便地,图像训练数据的转换存储格式(http://stackoverflow.com/questions/14694810/using-opencv-and-svm-with-images?rq=1)

最后,为了验证读取数据的正确性,一个有效的办法就是输出第一个和最后一个数据(可以输出打印第一个/最后一个image以及label)
2. 训练
(此处我是直接对原图像训练,并没有提取任何的特征)
也有人建议这里应该对图像做HOG特征提取,再配合label训练(我还没试过...不知道效果如何...)

opencv3.0和2.4的SVM接口有不同,基本可以按照以下的格式来执行:
ml::SVM::Params params;
params.svmType = ml::SVM::C_SVC;
params.kernelType = ml::SVM::POLY;
params.gamma = ;
Ptr<ml::SVM> svm = ml::SVM::create(params);
Mat trainData; // 每行为一个样本
Mat labels;
svm->train( trainData , ml::ROW_SAMPLE , labels );
// ... svm->save("....");//文件形式为xml,可以保存在txt或者xml文件中
Ptr<SVM> svm=statModel::load<SVM>("...."); Mat query; // 输入, 1个通道
Mat res; // 输出
svm->predict(query, res);
但是要注意,如果报错的话最好去看opencv3.0的文档,里面有函数原型和解释,我在实际操作的过程中,也做了一些改动
1)设置参数
SVM的参数有很多,但是与C_SVC和RBF有关的就只有gamma和C,所以设置这两个就好,终止条件设置和默认一样,由经验可得(其实是查阅了很多的资料,把gamma设置成0.01,这样训练收敛速度会快很多)
Ptr<SVM> svm = SVM::create();
svm->setType(SVM::C_SVC);
svm->setKernel(SVM::RBF);
svm->setGamma(0.01);
svm->setC(10.0);
svm->setTermCriteria(TermCriteria(CV_TERMCRIT_EPS, ,FLT_EPSILON));
svm_type –指定SVM的类型,下面是可能的取值:
CvSVM::C_SVC C类支持向量分类机。 n类分组 (n \geq 2),允许用异常值惩罚因子C进行不完全分类。
CvSVM::NU_SVC \nu类支持向量分类机。n类似然不完全分类的分类器。参数为 \nu 取代C(其值在区间【0,1】中,nu越大,决策边界越平滑)。
CvSVM::ONE_CLASS 单分类器,所有的训练数据提取自同一个类里,然后SVM建立了一个分界线以分割该类在特征空间中所占区域和其它类在特征空间中所占区域。
CvSVM::EPS_SVR \epsilon类支持向量回归机。训练集中的特征向量和拟合出来的超平面的距离需要小于p。异常值惩罚因子C被采用。
CvSVM::NU_SVR \nu类支持向量回归机。 \nu 代替了 p。
kernel_type –SVM的内核类型,下面是可能的取值:
CvSVM::LINEAR 线性内核。没有任何向映射至高维空间,线性区分(或回归)在原始特征空间中被完成,这是最快的选择。K(x_i, x_j) = x_i^T x_j.
CvSVM::POLY 多项式内核: K(x_i, x_j) = (\gamma x_i^T x_j + coef0)^{degree}, \gamma > 0.
CvSVM::RBF 基于径向的函数,对于大多数情况都是一个较好的选择: K(x_i, x_j) = e^{-\gamma ||x_i - x_j||^2}, \gamma > 0.
CvSVM::SIGMOID Sigmoid函数内核:K(x_i, x_j) = \tanh(\gamma x_i^T x_j + coef0).
degree – 内核函数(POLY)的参数degree。
gamma – 内核函数(POLY/ RBF/ SIGMOID)的参数\gamma。
coef0 – 内核函数(POLY/ SIGMOID)的参数coef0。
Cvalue – SVM类型(C_SVC/ EPS_SVR/ NU_SVR)的参数C。
nu – SVM类型(NU_SVC/ ONE_CLASS/ NU_SVR)的参数 \nu。
p – SVM类型(EPS_SVR)的参数 \epsilon。
class_weights – C_SVC中的可选权重,赋给指定的类,乘以C以后变成 class\_weights_i * C。所以这些权重影响不同类别的错误分类惩罚项。权重越大,某一类别的误分类数据的惩罚项就越大。
term_crit – SVM的迭代训练过程的中止条件,解决部分受约束二次最优问题。您可以指定的公差和/或最大迭代次数。
2)训练
Mat trainData;
Mat labels;
trainData = read_mnist_image(trainImage);
labels = read_mnist_label(trainLabel); svm->train(trainData, ROW_SAMPLE, labels);
3)保存
svm->save("mnist_dataset/mnist_svm.xml");
3. 测试,比对结果
(此处的FLT_EPSILON是一个极小的数,1.0 - FLT_EPSILON != 1.0)
Mat testData;
Mat tLabel;
testData = read_mnist_image(testImage);
tLabel = read_mnist_label(testLabel); float count = ;
for (int i = ; i < testData.rows; i++) {
Mat sample = testData.row(i);
float res = svm1->predict(sample);
res = std::abs(res - tLabel.at<unsigned int>(i, )) <= FLT_EPSILON ? .f : .f;
count += res;
}
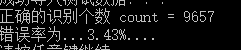
cout << "正确的识别个数 count = " << count << endl;
cout << "错误率为..." << ( - count + 0.0) / * 100.0 << "%....\n";
这里没有使用svm->predict(query, res);
然后就查看了opencv的文档,当传入数据是Mat 而不是cvMat时,可以利用predict的返回值(float)来判断预测是否正确。

运行结果:
1)1000个训练数据/1000个测试数据

2)2000个训练数据/2000个测试数据

3)5000个训练数据/5000个测试数据

4)10000个训练数据/10000个测试数据
5)60000个训练数据/10000个测试数据

最后,关于运行时间(在程序正确的前提下,训练时长和初始的参数设置有关),给出我最的运行结果(1000张图是11s左右,60000张是1300s ~ 2000s左右)
代码:
#ifndef MNIST_H
#define MNIST_H #include <iostream>
#include <string>
#include <fstream>
#include <ctime>
#include <opencv2/opencv.hpp> using namespace cv;
using namespace std; //小端存储转换
int reverseInt(int i); //读取image数据集信息
Mat read_mnist_image(const string fileName); //读取label数据集信息
Mat read_mnist_label(const string fileName); #endif
mnist.h
#include "mnist.h" //计时器
double cost_time;
clock_t start_time;
clock_t end_time; //测试item个数
int testNum = ; int reverseInt(int i) {
unsigned char c1, c2, c3, c4; c1 = i & ;
c2 = (i >> ) & ;
c3 = (i >> ) & ;
c4 = (i >> ) & ; return ((int)c1 << ) + ((int)c2 << ) + ((int)c3 << ) + c4;
} Mat read_mnist_image(const string fileName) {
int magic_number = ;
int number_of_images = ;
int n_rows = ;
int n_cols = ; Mat DataMat; ifstream file(fileName, ios::binary);
if (file.is_open())
{
cout << "成功打开图像集 ... \n"; file.read((char*)&magic_number, sizeof(magic_number));
file.read((char*)&number_of_images, sizeof(number_of_images));
file.read((char*)&n_rows, sizeof(n_rows));
file.read((char*)&n_cols, sizeof(n_cols));
//cout << magic_number << " " << number_of_images << " " << n_rows << " " << n_cols << endl; magic_number = reverseInt(magic_number);
number_of_images = reverseInt(number_of_images);
n_rows = reverseInt(n_rows);
n_cols = reverseInt(n_cols);
cout << "MAGIC NUMBER = " << magic_number
<< " ;NUMBER OF IMAGES = " << number_of_images
<< " ; NUMBER OF ROWS = " << n_rows
<< " ; NUMBER OF COLS = " << n_cols << endl; //-test-
//number_of_images = testNum;
//输出第一张和最后一张图,检测读取数据无误
Mat s = Mat::zeros(n_rows, n_rows * n_cols, CV_32FC1);
Mat e = Mat::zeros(n_rows, n_rows * n_cols, CV_32FC1); cout << "开始读取Image数据......\n";
start_time = clock();
DataMat = Mat::zeros(number_of_images, n_rows * n_cols, CV_32FC1);
for (int i = ; i < number_of_images; i++) {
for (int j = ; j < n_rows * n_cols; j++) {
unsigned char temp = ;
file.read((char*)&temp, sizeof(temp));
float pixel_value = float((temp + 0.0) / 255.0);
DataMat.at<float>(i, j) = pixel_value; //打印第一张和最后一张图像数据
if (i == ) {
s.at<float>(j / n_cols, j % n_cols) = pixel_value;
}
else if (i == number_of_images - ) {
e.at<float>(j / n_cols, j % n_cols) = pixel_value;
}
}
}
end_time = clock();
cost_time = (end_time - start_time) / CLOCKS_PER_SEC;
cout << "读取Image数据完毕......" << cost_time << "s\n"; imshow("first image", s);
imshow("last image", e);
waitKey();
}
file.close();
return DataMat;
} Mat read_mnist_label(const string fileName) {
int magic_number;
int number_of_items; Mat LabelMat; ifstream file(fileName, ios::binary);
if (file.is_open())
{
cout << "成功打开Label集 ... \n"; file.read((char*)&magic_number, sizeof(magic_number));
file.read((char*)&number_of_items, sizeof(number_of_items));
magic_number = reverseInt(magic_number);
number_of_items = reverseInt(number_of_items); cout << "MAGIC NUMBER = " << magic_number << " ; NUMBER OF ITEMS = " << number_of_items << endl; //-test-
//number_of_items = testNum;
//记录第一个label和最后一个label
unsigned int s = , e = ; cout << "开始读取Label数据......\n";
start_time = clock();
LabelMat = Mat::zeros(number_of_items, , CV_32SC1);
for (int i = ; i < number_of_items; i++) {
unsigned char temp = ;
file.read((char*)&temp, sizeof(temp));
LabelMat.at<unsigned int>(i, ) = (unsigned int)temp; //打印第一个和最后一个label
if (i == ) s = (unsigned int)temp;
else if (i == number_of_items - ) e = (unsigned int)temp;
}
end_time = clock();
cost_time = (end_time - start_time) / CLOCKS_PER_SEC;
cout << "读取Label数据完毕......" << cost_time << "s\n"; cout << "first label = " << s << endl;
cout << "last label = " << e << endl;
}
file.close();
return LabelMat;
}
mnist.cpp
/*
svm_type –
指定SVM的类型,下面是可能的取值:
CvSVM::C_SVC C类支持向量分类机。 n类分组 (n \geq 2),允许用异常值惩罚因子C进行不完全分类。
CvSVM::NU_SVC \nu类支持向量分类机。n类似然不完全分类的分类器。参数为 \nu 取代C(其值在区间【0,1】中,nu越大,决策边界越平滑)。
CvSVM::ONE_CLASS 单分类器,所有的训练数据提取自同一个类里,然后SVM建立了一个分界线以分割该类在特征空间中所占区域和其它类在特征空间中所占区域。
CvSVM::EPS_SVR \epsilon类支持向量回归机。训练集中的特征向量和拟合出来的超平面的距离需要小于p。异常值惩罚因子C被采用。
CvSVM::NU_SVR \nu类支持向量回归机。 \nu 代替了 p。 可从 [LibSVM] 获取更多细节。 kernel_type –
SVM的内核类型,下面是可能的取值:
CvSVM::LINEAR 线性内核。没有任何向映射至高维空间,线性区分(或回归)在原始特征空间中被完成,这是最快的选择。K(x_i, x_j) = x_i^T x_j.
CvSVM::POLY 多项式内核: K(x_i, x_j) = (\gamma x_i^T x_j + coef0)^{degree}, \gamma > 0.
CvSVM::RBF 基于径向的函数,对于大多数情况都是一个较好的选择: K(x_i, x_j) = e^{-\gamma ||x_i - x_j||^2}, \gamma > 0.
CvSVM::SIGMOID Sigmoid函数内核:K(x_i, x_j) = \tanh(\gamma x_i^T x_j + coef0). degree – 内核函数(POLY)的参数degree。 gamma – 内核函数(POLY/ RBF/ SIGMOID)的参数\gamma。 coef0 – 内核函数(POLY/ SIGMOID)的参数coef0。 Cvalue – SVM类型(C_SVC/ EPS_SVR/ NU_SVR)的参数C。 nu – SVM类型(NU_SVC/ ONE_CLASS/ NU_SVR)的参数 \nu。 p – SVM类型(EPS_SVR)的参数 \epsilon。 class_weights – C_SVC中的可选权重,赋给指定的类,乘以C以后变成 class\_weights_i * C。所以这些权重影响不同类别的错误分类惩罚项。权重越大,某一类别的误分类数据的惩罚项就越大。 term_crit – SVM的迭代训练过程的中止条件,解决部分受约束二次最优问题。您可以指定的公差和/或最大迭代次数。 */ #include "mnist.h" #include <opencv2/core.hpp>
#include <opencv2/imgproc.hpp>
#include "opencv2/imgcodecs.hpp"
#include <opencv2/highgui.hpp>
#include <opencv2/ml.hpp> #include <string>
#include <iostream> using namespace std;
using namespace cv;
using namespace cv::ml; string trainImage = "mnist_dataset/train-images.idx3-ubyte";
string trainLabel = "mnist_dataset/train-labels.idx1-ubyte";
string testImage = "mnist_dataset/t10k-images.idx3-ubyte";
string testLabel = "mnist_dataset/t10k-labels.idx1-ubyte";
//string testImage = "mnist_dataset/train-images.idx3-ubyte";
//string testLabel = "mnist_dataset/train-labels.idx1-ubyte"; //计时器
double cost_time_;
clock_t start_time_;
clock_t end_time_; int main()
{ //--------------------- 1. Set up training data ---------------------------------------
Mat trainData;
Mat labels;
trainData = read_mnist_image(trainImage);
labels = read_mnist_label(trainLabel); cout << trainData.rows << " " << trainData.cols << endl;
cout << labels.rows << " " << labels.cols << endl; //------------------------ 2. Set up the support vector machines parameters --------------------
Ptr<SVM> svm = SVM::create();
svm->setType(SVM::C_SVC);
svm->setKernel(SVM::RBF);
//svm->setDegree(10.0);
svm->setGamma(0.01);
//svm->setCoef0(1.0);
svm->setC(10.0);
//svm->setNu(0.5);
//svm->setP(0.1);
svm->setTermCriteria(TermCriteria(CV_TERMCRIT_EPS, , FLT_EPSILON)); //------------------------ 3. Train the svm ----------------------------------------------------
cout << "Starting training process" << endl;
start_time_ = clock();
svm->train(trainData, ROW_SAMPLE, labels);
end_time_ = clock();
cost_time_ = (end_time_ - start_time_) / CLOCKS_PER_SEC;
cout << "Finished training process...cost " << cost_time_ << " seconds..." << endl; //------------------------ 4. save the svm ----------------------------------------------------
svm->save("mnist_dataset/mnist_svm.xml");
cout << "save as /mnist_dataset/mnist_svm.xml" << endl; //------------------------ 5. load the svm ----------------------------------------------------
cout << "开始导入SVM文件...\n";
Ptr<SVM> svm1 = StatModel::load<SVM>("mnist_dataset/mnist_svm.xml");
cout << "成功导入SVM文件...\n"; //------------------------ 6. read the test dataset -------------------------------------------
cout << "开始导入测试数据...\n";
Mat testData;
Mat tLabel;
testData = read_mnist_image(testImage);
tLabel = read_mnist_label(testLabel);
cout << "成功导入测试数据!!!\n"; float count = ;
for (int i = ; i < testData.rows; i++) {
Mat sample = testData.row(i);
float res = svm1->predict(sample);
res = std::abs(res - tLabel.at<unsigned int>(i, )) <= FLT_EPSILON ? .f : .f;
count += res;
}
cout << "正确的识别个数 count = " << count << endl;
cout << "错误率为..." << ( - count + 0.0) / * 100.0 << "%....\n"; system("pause");
return ;
}
main.cpp
一些网站(资料):(其实都很容易搜索到的=_=, 但是搬了人家的东西,就还是贴一下...
http://blog.csdn.net/augusdi/article/details/9005352
http://blog.csdn.net/arthur503/article/details/19974057
http://blog.csdn.net/laihonghuan/article/details/49387237
http://docs.opencv.org/3.0-beta/modules/ml/doc/support_vector_machines.html#prediction-with-svm
http://stackoverflow.com/questions/14694810/using-opencv-and-svm-with-images?rq=1
http://docs.opencv.org/2.4/modules/ml/doc/support_vector_machines.html#cvsvm-train
http://blog.csdn.net/u010869312/article/details/44927721
http://blog.csdn.net/heroacool/article/details/50579955
http://docs.opencv.org/3.0-beta/doc/tutorials/ml/introduction_to_svm/introduction_to_svm.html
http://guyvercz.blog.163.com/blog/static/252545292011112974915402/
http://stackoverflow.com/questions/12993941/how-can-i-read-the-mnist-dataset-with-c?lq=1
【OpenCV】opencv3.0中的SVM训练 mnist 手写字体识别的更多相关文章
- 深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识
深度学习-tensorflow学习笔记(1)-MNIST手写字体识别预备知识 在tf第一个例子的时候需要很多预备知识. tf基本知识 香农熵 交叉熵代价函数cross-entropy 卷积神经网络 s ...
- 深度学习-tensorflow学习笔记(2)-MNIST手写字体识别
深度学习-tensorflow学习笔记(2)-MNIST手写字体识别超级详细版 这是tf入门的第一个例子.minst应该是内置的数据集. 前置知识在学习笔记(1)里面讲过了 这里直接上代码 # -*- ...
- 第二节,mnist手写字体识别
1.获取mnist数据集,得到正确的数据格式 mnist = input_data.read_data_sets('MNIST_data',one_hot=True) 2.定义网络大小:图片的大小是2 ...
- Android+TensorFlow+CNN+MNIST 手写数字识别实现
Android+TensorFlow+CNN+MNIST 手写数字识别实现 SkySeraph 2018 Email:skyseraph00#163.com 更多精彩请直接访问SkySeraph个人站 ...
- 基于tensorflow的MNIST手写数字识别(二)--入门篇
http://www.jianshu.com/p/4195577585e6 基于tensorflow的MNIST手写字识别(一)--白话卷积神经网络模型 基于tensorflow的MNIST手写数字识 ...
- 持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型
持久化的基于L2正则化和平均滑动模型的MNIST手写数字识别模型 觉得有用的话,欢迎一起讨论相互学习~Follow Me 参考文献Tensorflow实战Google深度学习框架 实验平台: Tens ...
- Tensorflow之MNIST手写数字识别:分类问题(1)
一.MNIST数据集读取 one hot 独热编码独热编码是一种稀疏向量,其中:一个向量设为1,其他元素均设为0.独热编码常用于表示拥有有限个可能值的字符串或标识符优点: 1.将离散特征的取值扩展 ...
- TensorFlow实战第五课(MNIST手写数据集识别)
Tensorflow实现softmax regression识别手写数字 MNIST手写数字识别可以形象的描述为机器学习领域中的hello world. MNIST是一个非常简单的机器视觉数据集.它由 ...
- TensorFlow——MNIST手写数字识别
MNIST手写数字识别 MNIST数据集介绍和下载:http://yann.lecun.com/exdb/mnist/ 一.数据集介绍: MNIST是一个入门级的计算机视觉数据集 下载下来的数据集 ...
随机推荐
- 【OpenCV & CUDA】OpenCV和Cuda结合编程
一.利用OpenCV中提供的GPU模块 目前,OpenCV中已提供了许多GPU函数,直接使用OpenCV提供的GPU模块,可以完成大部分图像处理的加速操作. 基本使用方法,请参考:http://www ...
- saltstack学习笔记1 --安装
salt官网:http://docs.saltstack.cn/zh_CN/latest/ 安装教程: - http://docs.saltstack.cn/zh_CN/latest/topics/i ...
- 七年IT生涯的经验教训
七年IT生涯的经验教训[转]我在IT界也拼打了有好几年了,但是现在和别人比较起来不是很如意.从天分上来说,我在属于智商不低的人:从技术上说,几乎没有我拿不下的:从见解上看,我是很有点子看法的人. ...
- Vue方法与事件
gitHub地址:https://github.com/lily1010/vue_learn/tree/master/lesson10 一 vue方法实现 <!DOCTYPE html> ...
- KindEditor编辑器在ASP.NET中的使用
KindEditor编辑器在ASP.NET中的使用 最近做的项目中都有用到富文本编辑器,一直在寻找最后用的富文本编辑器,之前用过CKEditor,也用过UEditor,这次打算用 一下KindEdit ...
- Sharepoint 2013 关于"SPChange"简介
在SharePoint中,我们经常会需要获取那些改变的项目,其实api为我们提供了SPChange对象,下面,我们通过列表简单介绍下这一对象. 1.创建一个测试列表,名字叫做“SPChangeItem ...
- SharePoint 错误集 3
1. workflow 流程走不下去,报 workflow fails to run 的错误 请确保下面二个service要么都start,要么都stop: Microsoft SharePoint ...
- Java中的继承与组合(转载)
本文主要说明Java中继承与组合的概念,以及它们之间的联系与区别.首先文章会给出一小段代码示例,用于展示到底什么是继承.然后演示如何通过“组合”来改进这种继承的设计机制.最后总结这两者的应用场景,即到 ...
- Sharepoint学习笔记—习题系列--70-573习题解析 -(Q100-Q103)
Question 100You create a Web Part.You need to display the number of visits to a SharePoint site coll ...
- 通过重写OnScrollListener来监听RecyclerView是否滑动到底部
为了增加复用性和灵活性,我们还是定义一个接口来做监听滚动到底部的回调,这样你就可以把它用在listview,scrollView中去. OnBottomListener package kale.co ...