springboot中实现kafa指定offset消费
kafka消费过程难免会遇到需要重新消费的场景,例如我们消费到kafka数据之后需要进行存库操作,若某一时刻数据库down了,导致kafka消费的数据无法入库,为了弥补数据库down期间的数据损失,有一种做法我们可以指定kafka消费者的offset到之前某一时间的数值,然后重新进行消费。
首先创建kafka消费服务
@Service
@Slf4j
//实现CommandLineRunner接口,在springboot启动时自动运行其run方法。
public class TspLogbookAnalysisService implements CommandLineRunner {
@Override
public void run(String... args) {
//do something
}
}
kafka消费模型建立
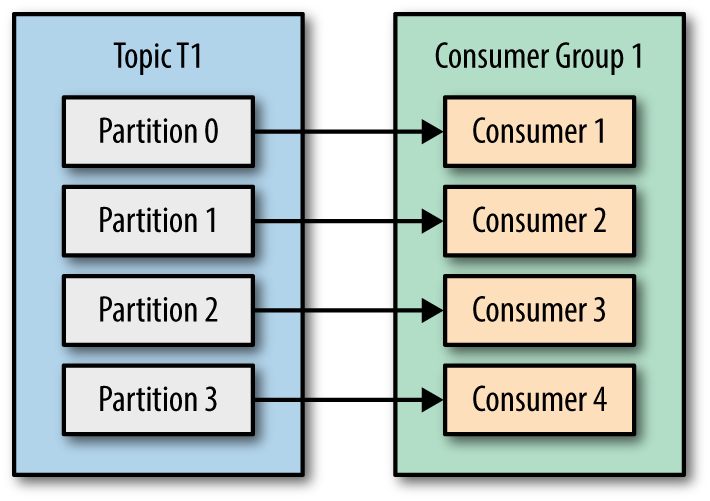
kafka server中每个主题存在多个分区(partition),每个分区自己维护一个偏移量(offset),我们的目标是实现kafka consumer指定offset消费。
在这里使用consumer-->partition一对一的消费模型,每个consumer各自管理自己的partition。
@Service
@Slf4j
public class TspLogbookAnalysisService implements CommandLineRunner {
//声明kafka分区数相等的消费线程数,一个分区对应一个消费线程
private static final int consumeThreadNum = 9;
//特殊指定每个分区开始消费的offset
private List<Long> partitionOffsets = Lists.newArrayList(1111,1112,1113,1114,1115,1116,1117,1118,1119);
private ExecutorService executorService = Executors.newFixedThreadPool(consumeThreadNum);
@Override
public void run(String... args) {
//循环遍历创建消费线程
IntStream.range(0, consumeThreadNum)
.forEach(partitionIndex -> executorService.submit(() -> startConsume(partitionIndex)));
}
}
kafka consumer对offset的处理
声明kafka consumer的配置类
private Properties buildKafkaConfig() {
Properties kafkaConfiguration = new Properties();
kafkaConfiguration.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.GROUP_ID_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "");
kafkaConfiguration.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG,"");
kafkaConfiguration.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "");
...更多配置项
return kafkaConfiguration;
}
创建kafka consumer,处理offset,开始消费数据任务
private void startConsume(int partitionIndex) {
//创建kafka consumer
KafkaConsumer<String, byte[]> consumer = new KafkaConsumer<>(buildKafkaConfig());
try {
//指定该consumer对应的消费分区
TopicPartition partition = new TopicPartition(kafkaProperties.getKafkaTopic(), partitionIndex);
consumer.assign(Lists.newArrayList(partition));
//consumer的offset处理
if (collectionUtils.isNotEmpty(partitionOffsets) && partitionOffsets.size() == consumeThreadNum) {
Long seekOffset = partitionOffsets.get(partitionIndex);
log.info("partition:{} , offset seek from {}", partition, seekOffset);
consumer.seek(partition, seekOffset);
}
//开始消费数据任务
kafkaRecordConsume(consumer, partition);
} catch (Exception e) {
log.error("kafka consume error:{}", ExceptionUtils.getFullStackTrace(e));
} finally {
try {
consumer.commitSync();
} finally {
consumer.close();
}
}
}
消费数据逻辑,offset操作
private void kafkaRecordConsume(KafkaConsumer<String, byte[]> consumer, TopicPartition partition) {
while (true) {
try {
ConsumerRecords<String, byte[]> records = consumer.poll(TspLogbookConstants.POLL_TIMEOUT);
//具体的处理流程
records.forEach((k) -> handleKafkaInput(k.key(), k.value()));
//
springboot中实现kafa指定offset消费的更多相关文章
- spark streaming从指定offset处消费Kafka数据
spark streaming从指定offset处消费Kafka数据 -- : 770人阅读 评论() 收藏 举报 分类: spark() 原文地址:http://blog.csdn.net/high ...
- springboot中RedisTemplate的使用
springboot中RedisTemplate的使用 参考 了解 Redis 并在 Spring Boot 项目中使用 Redis--以IBM为学习模板 springboot之使用redistemp ...
- javascript中常用坐标属性offset、scroll、client
原文:javascript中常用坐标属性offset.scroll.client 今天在学习js的时候觉得这个问题比较容易搞混,所以自己画了一个简单的图,并且用js控制台里面输出测试了下,便于理解. ...
- SpringBoot(四)SpringBoot中lombok使用
lombok概述 lombok简介 Lombok想要解决了的是在我们实体Bean中大量的Getter/Setter方法,以及toString, hashCode等可能不会用到,但是某些时候仍然需要复写 ...
- SpringBoot 中常用注解@PathVaribale/@RequestParam/@GetMapping介绍
SpringBoot 中常用注解@PathVaribale/@RequestParam/@GetMapping介绍 本篇博文将介绍几种如何处理url中的参数的注解@PathVaribale/@Requ ...
- SpringBoot中对于异常处理的提供的五种处理方式
1.自定义错误页面 SpringBoot 默认的处理异常机制:SpringBoot默认的已经提供了一套处理异常的机制.一旦程序中出现了异常,SpringBoot会向/error的url发送请求.在Sp ...
- Spring-boot中@ConfigurationProperties,@Value,@PropertySource
1.利用@ConfigurationProperties获取配置的值,@ConfigurationProperties是springboot提供的基于安全类型的配置放置. application.pr ...
- Springboot中使用Xstream进行XML与Bean 相互转换
在现今的项目开发中,虽然数据的传输大部分都是用json格式来进行传输,但是xml毕竟也会有一些老的项目在进行使用,正常的老式方法是通过获取节点来进行一系列操作,个人感觉太过于复杂.繁琐.推荐一套简单的 ...
- springBoot中实现自定义属性配置、实现异步调用、多环境配置
springBoot中其他相关: 1:springBoot中自定义参数: 1-1.自定义属性配置: 在application.properties中除了可以修改默认配置,我们还可以在这配置自定义的属性 ...
随机推荐
- 浅谈oracle中for update 和 for update nowait 和 for update wait x的区别
在执行update的时候,不加nowait/wait x的时候,当数据记录被锁住的时候,会一直处于等待状态,直到资源锁定被释放: 而加了nowait的时候,马上就会进行反馈“ORA-00054错误,内 ...
- Python数据挖掘入门与实战PDF电子版加源码
Python数据分析挖掘实战讲解和分析PDF加源码 链接: https://pan.baidu.com/s/1SkZR2lGFnwZiQNav-qrC4w 提取码: n3ud 好的资源就要共享,我会一 ...
- 磁盘配额管理disk quotas
条件: a.确保系统内核支持,Linux一般都支持 b.确保分区格式支持,ext2都只持! c.安装有quota软件,centos默认都有! (1)检查内核是否打开磁盘配额支持 [root@cento ...
- openresty如何完美替换nginx
下载openresty wget https://openresty.org/download/openresty-1.15.8.1.tar.gz tar zxvf openresty-1.15.8. ...
- vue3.0里的生命周期函数
- mybatis精讲(三)--标签及TypeHandler使用
目录 话引 XML配置标签 概览 properties 子标签property resource 程序注入 settings 别名 TypeHandler 自定义TypeHandler EnumTyp ...
- 【01】主函数main
java和C#非常相似,它们大部分的语法是一样的,但尽管如此,也有一些地方是不同的. 为了更好地学习java或C#,有必要分清它们两者到底在哪里不同. 首先,我们将探讨主函数main. java的主函 ...
- [ch03-00] 损失函数
系列博客,原文在笔者所维护的github上:https://aka.ms/beginnerAI, 点击star加星不要吝啬,星越多笔者越努力. 第3章 损失函数 3.0 损失函数概论 3.0.1 概念 ...
- pdf 在线预览之 pdfobject插件
支持到ie9 可以不用安装 如果安装 npm i pdfobject 第一步:引入pdfObject包 申明一个变量 const { PDFObject } = require("../. ...
- Java关于Resource leak: 's' is never closed的问题
Resource leak: 's' is never closed的问题 问题:在编写Java时出现了Resource leak: 's' is never closed的问题,也就是对象s下面的波 ...