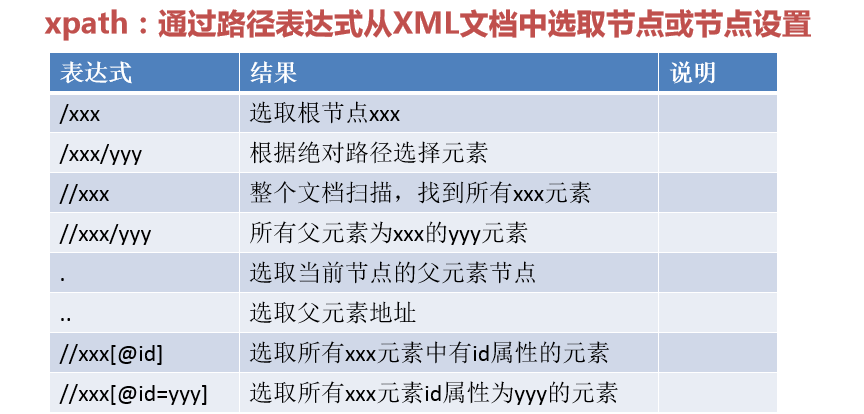
xpath:




from selenium import webdriver
b = webdriver.Firefox()
#路径读取方式一:
# b.get(r"C:\我的代码\selenium自动化测试\test.html")
#路径读取方式二:
# b.get("C:\\我的代码\\selenium自动化测试\\test.html")
#路径读取方式三:
b.get('file://C:\\我的代码\\selenium自动化测试\\test.html')
#打印选取根节点:
ele = b.find_element_by_xpath("/html")
print(ele)
#打印所有的文本:
print(ele.text)
#根据绝对路径选择元素:
ele1 = b.find_element_by_xpath("/html/body/form/input")
print(ele1)
#get_attribute查看type属性:
print(ele1.get_attribute("type"))
#同级定位输入框:
ele2 = b.find_element_by_xpath("/html/body/form/input[2]")
print(ele2.get_attribute("name"))
#遍历整个文档找到元素:
ele3 = b.find_element_by_xpath("//input")
print(ele3)
#遍历整个元素索引匹配:
ele4 = b.find_element_by_xpath("//input[2]")
print(ele4.get_attribute("name"))
#关闭页面:
# b.close()
#所有父元素为xxx的yyy元素:
ele5 = b.find_element_by_xpath("//form//input")
print(ele5.get_attribute("name"))
#获取id属性元素:
ele6 = b.find_element_by_xpath("//input[@id]")
print(ele6.id)
#找到所有的元素:
ele7 = b.find_element_by_xpath("//*")
print(ele7.tag_name)
#两个反斜杠是遍历整个文档、*是遍历整个元素、count元素统计标签个数
ele8 = b.find_element_by_xpath("//*[count(input)=2]")
print(ele8.tag_name)
#找到tag为某某的元素:
ele9 = b.find_element_by_xpath("//*[local-name()='input']")
print(ele9.tag_name)
#找到所有tag以某某开头的元素:
ele10 = b.find_element_by_xpath("//*[starts-with(local-name(),'i')]")
print(ele10.tag_name)
# 找到所有tag包含x的元素:
ele11 = b.find_element_by_xpath("//*[contains(local-name(),'i')]")
print(ele11.get_attribute("name"))
print(ele11.tag_name)
# 找到所有tag长度为3的元素:
# ele12 = b.find_element_by_xpath("//*[string-length(local-name())=5")
# print(ele12.get_attribute("name"))
# print(ele12.tag_name)
#多个路径查找:
ele13 = b.find_element_by_xpath("//title | //input")
print(ele13.tag_name)
#直接查找xpath:
ele14 = b.find_element_by_xpath("/html/body/p/input")
print(ele14.tag_name)
print(ele14.get_attribute("name"))
xpath:的更多相关文章
- json的xpath:简易数据查询
class JsonQuery(object): def __init__(self, data): super(JsonQuery, self).__init__() self.data = dat ...
- 爬虫系列3:Requests+Xpath 爬取租房网站信息并保存本地
数据保存本地 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参考前文 爬虫系列2:https://www ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- 爬虫解析:XPath总结
1.加载 XML 文档 所有现代浏览器都支持使用 XMLHttpRequest 来加载 XML 文档的方法. 针对大多数现代浏览器的代码: var xmlhttp=new XMLHttpRequest ...
- (三)XML基础(3):Xpath
五.XPath:快速定位到节点 5.1 简介 5.2 语法 5.3 案例 XPath对有命名空间的xml文件和没有命名空间的xml定位节点的方法是不一样的,所以再对不同的xml需要进行不同的处理. 使 ...
- Web自动化测试:xpath & CSS Selector定位
Xpath 和 CSS Selector简介 CSS Selector CSS Selector和Xpath都可以用来表示XML文档中的位置.CSS (Cascading Style Sheets)是 ...
- 网页解析:Xpath 与 BeautifulSoup
1. Xpath 1.1 Xpath 简介 1.2 Xpath 使用案例 2. BeautifulSoup 2.1 BeautifulSoup 简介 2.2 BeautifulSoup 使用案例 1) ...
- xpath轴的正确使用姿势
网上看了许多关于轴的介绍,只介绍了语法,而没有明说具体实际中该怎么使用,百思不得其解. 背景--python中使用xpath: ----------------------------------- ...
- Selenium脚本编写环境的搭建/XPath
编写环境主要分为三个部分: JUnit : java单元测试框架: Firebug: firefox 附加组件,Firebug是firefox下的一个扩展,能够调试所有网站语言,如Html,Css等, ...
随机推荐
- 在 Python 3.x 版本后,ConfigParser.py 已经更名为 configparser.py 所以出错!
在 Python 3.x 版本后,ConfigParser.py 已经更名为 configparser.py 所以出错!
- Spring(4)AOP
Spring(4)AOP 1.AOP概述 在软件业,AOP为Aspect Oriented Programming的缩写,意为:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种 ...
- SQL实用技巧:如何分割字符串
create function f_split(@c varchar(2000),@split varchar(2)) returns @t table(col varchar(20)) as beg ...
- SSM(SpringMVC+Spring+MyBatis)三大框架使用Maven快速搭建整合(实现数据库数据到页面进行展示)
本文介绍使用SpringMVC+Spring+MyBatis三大框架使用Maven快速搭建一个demo,实现数据从数据库中查询返回到页面进行展示的过程. 技术选型:SpringMVC+Spring+M ...
- C++ --const修饰指针
const修饰指针 1.const修饰指针 (常量指针)常量的指针 const int *p = &a; const修饰的是*p(表示内容为常量),不是p(指针) 指针指向的地址可以改,但指针 ...
- java之数据结构
数据结构有什么用? 现实世界的存储,我们使用的工具和建模.每种数据结构有自己的优点和缺点,想想如果Google的数据用的是数组的存储,我们还能方便地查询到所需要的数据吗?而算法,在这么多的数据中如何做 ...
- 线程池API总结
1.Executor:线程池顶级接口,只有一个方法 2.ExecutorService:真正的线程池接口 1) void execute(Runnable command) :执行任务/命令,没有返回 ...
- 第一章 1.1 计算机和Python基础
一.计算机基础 1.1.进制 计算机中的数字有四种存在形式,分别是:十进制.二进制.八进制和十六进制 1.1.1.十进制 1.基数:0-9 2.进位:逢10进1 3.位权:例:123 = 3*10^0 ...
- [灵魂拷问]MySQL面试高频100问(工程师方向)
作者:呼延十 juejin.im/post/5d351303f265da1bd30596f9 前言 本文主要受众为开发人员,所以不涉及到MySQL的服务部署等操作,且内容较多,大家准备好耐心和瓜子矿泉 ...
- Netty实战:设计一个IM框架
来源:逅弈逐码 bitchat 是一个基于 Netty 的 IM 即时通讯框架 项目地址:https://github.com/all4you/bitchat 快速开始 bitchat-example ...