Hadoop —— 集群环境搭建
一、集群规划
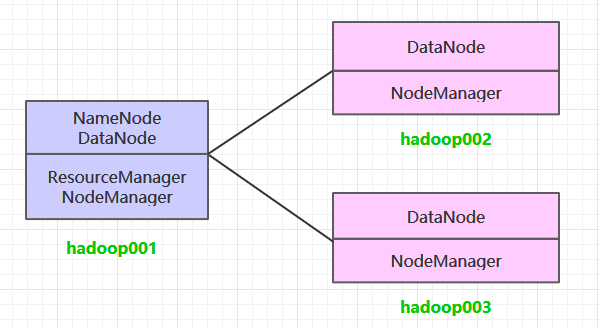
这里搭建一个3节点的Hadoop集群,其中三台主机均部署DataNode和NodeManager服务,但只有hadoop001上部署NameNode和ResourceManager服务。
二、前置条件
Hadoop的运行依赖JDK,需要预先安装。其安装步骤单独整理至:
三、配置免密登录
3.1 生成密匙
在每台主机上使用ssh-keygen命令生成公钥私钥对:
ssh-keygen
3.2 免密登录
将hadoop001的公钥写到本机和远程机器的~/ .ssh/authorized_key文件中:
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop001
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop002
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop003
3.3 验证免密登录
ssh hadoop002
ssh hadoop003
四、集群搭建
3.1 下载并解压
下载Hadoop。这里我下载的是CDH版本Hadoop,下载地址为:http://archive.cloudera.com/cdh5/cdh/5/
# tar -zvxf hadoop-2.6.0-cdh5.15.2.tar.gz
3.2 配置环境变量
编辑profile文件:
# vim /etc/profile
增加如下配置:
export HADOOP_HOME=/usr/app/hadoop-2.6.0-cdh5.15.2
export PATH=${HADOOP_HOME}/bin:$PATH
执行source命令,使得配置立即生效:
# source /etc/profile
3.3 修改配置
进入${HADOOP_HOME}/etc/hadoop目录下,修改配置文件。各个配置文件内容如下:
1. hadoop-env.sh
# 指定JDK的安装位置
export JAVA_HOME=/usr/java/jdk1.8.0_201/
2. core-site.xml
<configuration>
<property>
<!--指定namenode的hdfs协议文件系统的通信地址-->
<name>fs.defaultFS</name>
<value>hdfs://hadoop001:8020</value>
</property>
<property>
<!--指定hadoop集群存储临时文件的目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
</configuration>
3. hdfs-site.xml
<property>
<!--namenode节点数据(即元数据)的存放位置,可以指定多个目录实现容错,多个目录用逗号分隔-->
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop/namenode/data</value>
</property>
<property>
<!--datanode节点数据(即数据块)的存放位置-->
<name>dfs.datanode.data.dir</name>
<value>/home/hadoop/datanode/data</value>
</property>
4. yarn-site.xml
<property>
<!--配置NodeManager上运行的附属服务。需要配置成mapreduce_shuffle后才可以在Yarn上运行MapReduce程序。-->
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!--resourcemanager的主机名-->
<name>yarn.resourcemanager.hostname</name>
<value>hadoop001</value>
</property>
</configuration>
5. mapred-site.xml
<configuration>
<property>
<!--指定mapreduce作业运行在yarn上-->
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
5. slaves
配置所有从属节点的主机名或IP地址,每行一个。所有从属节点上的DataNode服务和NodeManager服务都会被启动。
hadoop001
hadoop002
hadoop003
3.4 分发程序
将Hadoop安装包分发到其他两台服务器,分发后建议在这两台服务器上也配置一下Hadoop的环境变量。
# 将安装包分发到hadoop002
scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop002:/usr/app/
# 将安装包分发到hadoop003
scp -r /usr/app/hadoop-2.6.0-cdh5.15.2/ hadoop003:/usr/app/
3.5 初始化
在Hadoop001上执行namenode初始化命令:
hdfs namenode -format
3.6 启动集群
进入到Hadoop001的${HADOOP_HOME}/sbin目录下,启动Hadoop。此时hadoop002和hadoop003上的相关服务也会被启动:
# 启动dfs服务
start-dfs.sh
# 启动yarn服务
start-yarn.sh
3.7 查看集群
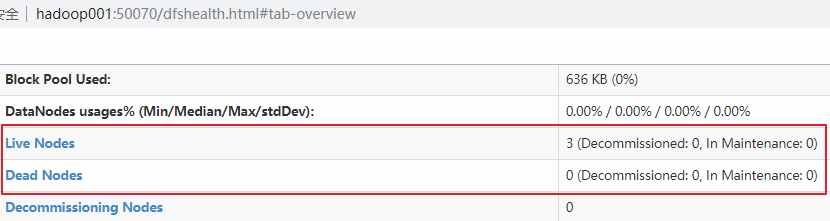
在每台服务器上使用jps命令查看服务进程,或直接进入Web-UI界面进行查看,端口为50070。可以看到此时有三个可用的Datanode:
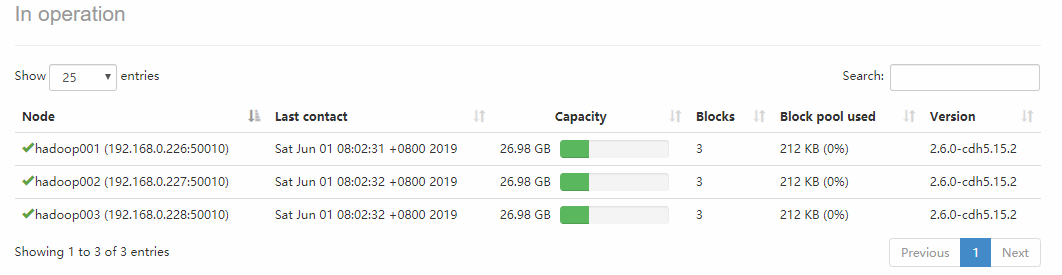
点击Live Nodes进入,可以看到每个DataNode的详细情况:
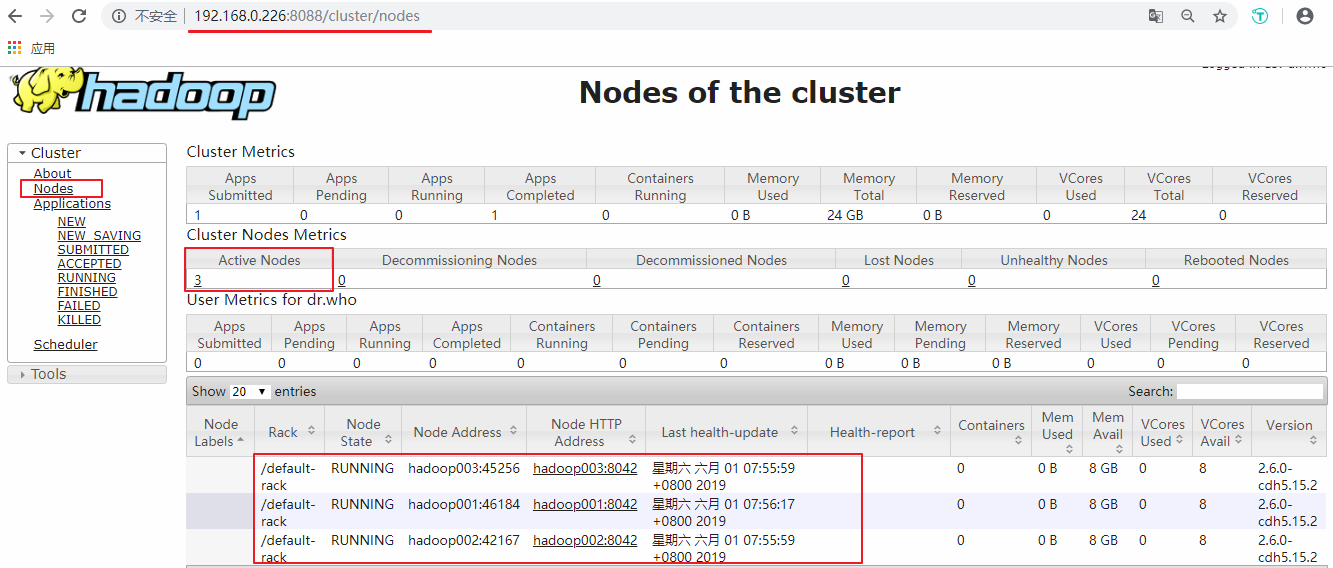
接着可以查看Yarn的情况,端口号为8088 :
五、提交服务到集群
提交作业到集群的方式和单机环境完全一致,这里以提交Hadoop内置的计算Pi的示例程序为例,在任何一个节点上执行都可以,命令如下:
hadoop jar /usr/app/hadoop-2.6.0-cdh5.15.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.15.2.jar pi 3 3
更多大数据系列文章可以参见个人 GitHub 开源项目: 程序员大数据入门指南
Hadoop —— 集群环境搭建的更多相关文章
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- hadoop集群环境搭建准备工作
一定要注意hadoop和linux系统的位数一定要相同,就是说如果hadoop是32位的,linux系统也一定要安装32位的. 准备工作: 1 首先在VMware中建立6台虚拟机(配置默认即可).这是 ...
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- 大数据 -- Hadoop集群环境搭建
首先我们来认识一下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式文件系统.它其实是将一个大文件分成若干块保存在不同服务器的多个节点中.通过联网 ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- 简单Hadoop集群环境搭建
最近大数据课程需要我们熟悉分布式环境,每组分配了四台服务器,正好熟悉一下hadoop相关的操作. 注:以下带有(master)字样为只需在master机器进行,(ALL)则表示需要在所有master和 ...
- Hadoop集群环境搭建(一)
1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 NameNode / DataN ...
- Java+大数据开发——Hadoop集群环境搭建(一)
1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主要有 NameNode / DataN ...
- Hadoop(4)-Hadoop集群环境搭建
准备工作 开启全部三台虚拟机,确保hadoop100的机器已经配置完成 分发脚本 操作hadoop100 新建一个xsync的脚本文件,将下面的脚本复制进去 vim xsync #这个脚本使用的是rs ...
随机推荐
- CentOS 由 JavaCPP 转让 FFMPEG
1. Java 与 FFMPEG FFMPEG 它是一种广泛使用的媒体处理库,于Java天地,处理视频较弱的能力,因此,有非常大的需求需求Java 转让 FFMPEG. Java 转让C 的方式有非常 ...
- matlab 二元函数的画法
plot:画线(curve,二维空间以及三维空间) surf:画面(surface,一般在三维空间) 1. surf 绘图函数 surf 是 surface 的缩写,表示表面(显然至少三维图像才会有表 ...
- Python实例讲解 -- 获取本地时间日期(日期计算)
1. 显示当前日期: print time.strftime('%Y-%m-%d %A %X %Z',time.localtime(time.time())) 或者 你也可以用: print list ...
- qt线程(转)----这篇很专业!
本文档是自己所整理的一份文档,部分是原创,还转贴了网上的一此资料(已经标明了),(难点是多线程的编写),是有源代码的,大家可以作为参考,用到的知识是视频采集,压缩解压(xvid),实时传输(jrtp) ...
- C#(WPF)为Grid添加实线边框。
原文:C#(WPF)为Grid添加实线边框. 相信大家在做WPF项目的时候,都会用到Grid这个布局控件,一般情况下,如果只是为了布局,那就不需要显示它的边框,但是也有特殊需求,如果把它当做表格来使用 ...
- WPF 自定义范围分组
<Window x:Class="ViewExam.MainWindow" xmlns="http://schemas.microsoft.com/w ...
- WPF 数据模板DataType属性的使用,不用指定ItemTemplate
<Window x:Class="CollectionBinding.MainWindow" xmlns="http://schemas.micros ...
- Linux下C语言RPC(远程过程调用)编程实例
在查看libc6-dev软件包提供的工具(用 dpkg -L libc6-dev 命令)的时候,发现此软件包提供了一个有用的工具rpcgen命令.通过rpcgen的man手册看到此工具的作用是把RPC ...
- 规则“Microsoft Visual Studio 2008 的早期版本”失败。此计算机上安装了 Microsoft Visual Studio 2008 的早期版本。请在安装 SQL Server 2008 前将 Microsoft Visual Studio 2008 升级到 SP1。
今天重装了一下系统后,需要装开发工具,我用的开发工具是Visual Studio2008 和SQL Server2008R2,装完Visual Studio2008的时候在装数据库的时候却出现这样的问 ...
- 问题记录,Release模式和Debug运行效果不一样,Release必须加延时
这个程序大体是这样一个逻辑,通过win32程序与设备交互,主线程先向设备发送命令要求 循环验证 然后一个线程专门负责接收设备返回信息 两边通过全局变量的变化来交流,主线程通过接收线程收到的信息设置界面 ...