docker安装Elasticsearch Kibana和Cerebro
环境:win10家庭版,基于Docker Toolbox
首先先做好以下两步准备工作:
①、打开Oracle VM VirtualBox,设置虚拟机内存大小,默认不够安装,建议如下设置:

②、启动虚拟机后,通过xshell连接上虚拟机,切换管理员模式,编辑 /etc/sysctl.conf,追加以下内容:
Linux查看和编辑文件,可参考:https://www.cnblogs.com/bingle/p/9785621.html
vm.max_map_count=262144
保存后,执行:
sysctl -p
最后退出管理员模式。追加以上内容,是为了在启动ElasticSearch镜像时,防止发生max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]错误。
以上两步处理好之后,通过docker-compose一行命令即可启动Elasticsearch Kibana和Cerebro,当然这里需要docker-compose.yaml文件,具体其中的配置如下:
version: '3.1'
services:
cerebro:
image: lmenezes/cerebro:0.8.3
container_name: 'cerebro'
ports:
- 9000:9000
command:
- -Dhosts.0.host=http://elasticsearch:9200
networks:
- es7net
kibana:
image: docker.elastic.co/kibana/kibana:7.2.0
container_name: 'kibana7'
environment:
- I18N_LOCALE=zh-CN
- XPACK_GRAPH_ENABLED=true
- TIMELION_ENABLED=true
- XPACK_MONITORING_COLLECTION_ENABLED="true"
ports:
- 5601:5601
networks:
- es7net
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0
container_name: 'es7_01'
environment:
- cluster.name=geektime
- node.name=es7_01
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_01
- cluster.initial_master_nodes=es7_01,es7_02
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es7data1:/usr/share/elasticsearch/data
ports:
- 9200:9200
networks:
- es7net
elasticsearch2:
image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0
container_name: 'es7_0'
environment:
- cluster.name=geektime
- node.name=es7_02
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- discovery.seed_hosts=es7_01
- cluster.initial_master_nodes=es7_01,es7_02
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- es7data2:/usr/share/elasticsearch/data
ports:
- 9300:9200
networks:
- es7net volumes:
es7data1:
driver: local
es7data2:
driver: local networks:
es7net:
driver: bridge
将文件放在/home/docker目录下,通过xshell在该目录下执行以下命令,即可启动,第一次的时候需要去下载对应的镜像,会比较慢,如果速度实在太慢,直接取消,多尝试几次。
docker-compose up -d
如果顺利,即可看到启动的镜像
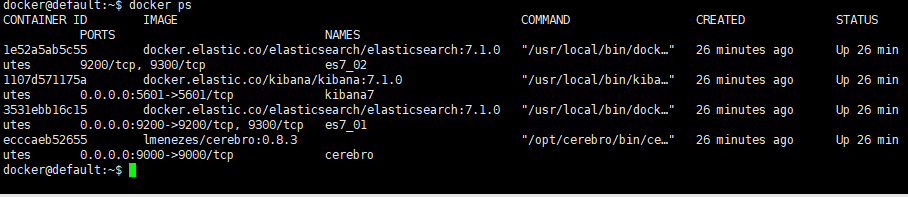
通过查看日志命令,可以观察对应组件的启动日志
docker logs -f 1e52a5ab5c55
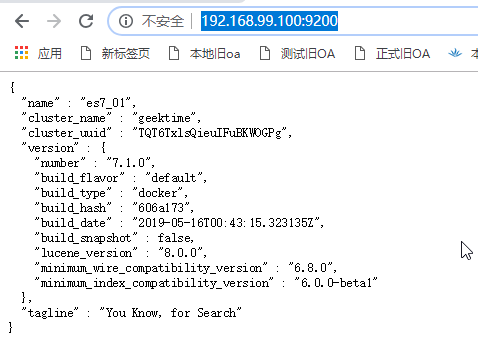
在浏览器中访问:http://192.168.99.100:9200/,如果出现以下界面说明Elasticsearch正常运行
在浏览器中输入http://192.168.99.100:5601,如果出现以下界面说明kibana正常运行
在浏览器中访问:http://192.168.99.100:9000/,如果出现以下界面说明Cerebro正常运行

docker安装Elasticsearch Kibana和Cerebro的更多相关文章
- 【最新】docker 安装elasticsearch + kibana步骤【第一篇_elasticsearch】
最近在用docker 安装elasticsearch + kibana 遇到了很多坑,最后成功安装elasticsearch + kibana (6.8.1)版本 安装了一下午,现总结过程中遇到 ...
- 【最新】docker 安装elasticsearch + kibana步骤【第二篇_kibana】
本文主要讲解Docker 安装 kibana并设置中文语言 [如果有需要安装elasticsearch 的朋友请移步博主第一篇文章] 话不多说! 第一步:docker 下载kibana docker ...
- Docker 安装 Elasticsearch+kibana
1 下载镜像 docker pull elasticsearch:7.4.1 docker pull kibana:7.4.1 拉取的镜像如下: 2 创建network 创建一个网络,名字任意取,使得 ...
- 【ELK】【docker】【elasticsearch】1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安装ik分词器
系列文章:[建议从第二章开始] [ELK][docker][elasticsearch]1. 使用Docker和Elasticsearch+ kibana 5.6.9 搭建全文本搜索引擎应用 集群,安 ...
- 使用 docker 进行 ElasticSearch + Kibana 集群搭建
在Docker容器中运行Elasticsearch Kibana和Cerebro 机器信息 10.160.13.139 10.160.9.162 10.160.11.171 1. 安装docker和d ...
- Docker安装ElasticSearch 版本7.1.1
一.Docker 部署 ElasticSearch 1.从仓库中查找所有ElasticSearch的镜像 [root@iZwz99dhxbd6xwly17tb3bZ app]# docker sear ...
- 使用Docker 安装Elasticsearch、Elasticsearch-head、IK分词器 和使用
原文:使用Docker 安装Elasticsearch.Elasticsearch-head.IK分词器 和使用 Elasticsearch的安装 一.elasticsearch的安装 1.镜像拉取 ...
- linux centos7使用docker安装elasticsearch,并且用Django连接使用
一:elasticsearch安装及配置 1:需求分析 当用户在搜索框输入关键字后,我们要为用户提供相关的搜索结果.这种需求依赖数据库的模糊查询like关键字可以实现,但是like关键字的效率极低,而 ...
- Docker安装ElasticSearch及kibana
什么是Kibana? Kibana 是一个设计出来用于和 Elasticsearch 一起使用的开源的分析与可视化平台,可以用 kibana 搜索.查看.交互存放在Elasticsearch 索引里的 ...
随机推荐
- __imp__SetupDiDestroyDeviceInfoList
error LINK2019 unresolved external symbol __imp__SetupDiDestroyDeviceInfoList 分类: 转载文章2012-11-02 15: ...
- gitlab 搭建
一.ubuntu搭建gitlab 1. 如果以前有安装过gitlab请根据以下步骤来删除 https://www.cnblogs.com/shansongxian/p/6678110.htm ...
- 有趣的"=="与"==="
console.log([]==![]);//true //"=="会进行类型转换,转换成统一类型进行比较 // !符号优于==,[]boolean值为TRUE,所以![]就是FA ...
- elementui-插槽
<el-table-column label="操作"> <template slot-scope="scope"> <el-bu ...
- SuperMap iClient3D for WebGL 9D怎么将s3m图层的纹理变更精细些
设置S3MTilesLayer.lodRangeScale.默认值是1,设的越小越精细,最小值是0.01.越大越模糊,最大值是100
- Flutter 37: 图解 Flutter 基本动画 (一)
小菜一直对动画不太熟悉,最近学习了一些关于动画的皮毛知识,网上资料很多,小菜按自己的理解整理一下. Animation Animation 可以生成动画过程中的值,生成的值并非单一的 double 也 ...
- libusb移植
下载 https://sourceforge.net/projects/libusb/ 编译 # ./configure --build=i686-linux --host=arm-linux --p ...
- 【异常】azkaban.executor.ExecutorManagerException: No active executors found
1 azkaban启动异常 没有找到活动的executors,需在MySQL数据库里设置端口为12321的executors表的active为1 update azkaban.executors ...
- C 字符串几点
1.字符串结尾必须为“\0” 2.多种处理函数在<string.h> 3.常用字符串处理函数: 1.strlen 求字符串长度(\0不算在内) 2.strcpy(a,b) 将b复制到a中 ...
- Centos7下搭建WebGoat 8和DVWA环境
搭建WebGoat 安装前置条件说明 我们这里选择WebGoat的jar版本,由于WebGoat 8的jar文件已自带了tomcat和数据库,所以不需要再另外安装tomcat和mysql这种东西,只需 ...