DRF 序列化组件 序列化的两种方式 反序列化 反序列化的校验
| 序列化组件 |
django自带的有序列化组件不过不可控不建议使用(了解)
from django.core import serializers class Books(APIView):
def get(self,request):
response = {'code':100,'msg':'查询成功'}
books = models.Book.objects.all()
# 了解django自带的序列化组件
ret= serializers.serialize("json",books)
return HttpResponse(ret)

使用drf的序列化组件
自定义py文件里为了和view视图函数隔离开 自定义文件中写serializer组件
1 新建一个序列化类继承Serializer 2 在类中写序列化的字段
source='表中字段' 自定义的字段不能和表中的字段名一样 username=serializer.CharField(source='name') username自定义的字段 source指定的是表中的字段
要序列化的对象默认传给instance 视图函数中的instance可以不写
source可以写跨表字段'publish.name' 之前跨表是book.publish.name 现在用source就可以省略book了 写成publish.name
source不但可以指定一个字段 还可以指定一个方法
#自定义的py文件中 from rest_framework import serializers #序列化组件 class BookSerializer(serializers.Serializer):
# 指定source = 'name' 表示序列化模型表中的name字段 重命名为name5(name5这个字段名 和source=’name'指定的模型表中的name字段名不能一样)
name5 = serializers.CharField(source='name')
# write_only 序列化的时候,该字段前端不显示
# read_only 反序列化的时候,该字段不传 前端传过来的时候可以不传参数或者字段
price = serializers.CharField(write_only=True) #如果要取 出版社的city 之前跨表查询是 book.publish.city 现在 source = 'publish.city' 不需要点击本身这张表的字段了
# source的值传给了默认形参instance
publish = serializers.CharField(source='publish.name') #出版社名字 #source不但可以指定一个字段,还可以指定一个方法 自定义choices字段取值固定用法get_字段_display
book_type = serializers.CharField(source='get_category_display',read_only=True)
#model.py模型表
class Book(models.Model):
nid = models.AutoField(primary_key=True)
name = models.CharField(max_length=32)
price = models.DecimalField(max_digits=8,decimal_places=2)
category = models.IntegerField(choices=((0,'文学类'),(1,'情感类')),default=1,null=True)
publish = models.ForeignKey(to='Publish',to_field='nid',on_delete=models.CASCADE,null=True)
authors = models.ManyToManyField(to='Author') def __str__(self):
return self.name def test(self):
return '方法'
在视图中使用序列化的类
实例化序列化的类产生对象,在产生对象的时候,传入需要序列化的对象
对象.data
return Response(对象.data) 返回值用Response返回
如果序列化多条 many=True(也就是queryset对象,就需要写many=True) 如果序列化一条(可以不用写many=False默认就是False)instance是要序列化的对象
from app01.app01serializer import BookSerializer #自定义的py文件下的序列化组件
from rest_framework.response import Response #返回用的 class Books(APIView):
def get(self,request):
response = {'code':100,'msg':'查询成功'}
books = models.Book.objects.all() bookser = BookSerializer(instance=books,many=True)
# 如果序列化多条,many=True(也就是queryset对象,就需要写)
print(bookser.data,type(bookser.data))
response['data'] = bookser.data
return Response(response)
SerializerMethodField 对应着一个方法:get_字段名 方法返回值是什么该字段就是什么 write_only 反序列化的时候该字段前端不显示 read_only 反序列化的时候前端可以不传这个字段
自定义py文件下的序列化组件 类下 from rest_framework import serializers # 序列化组件
from app01 import models class BookSerializer(serializers.Serializer):
#序列化出版社的详情,指定SerializerMethodField之后,可以对应一个方法,返回什么内容,publish_detail就是什么内容
publish_detail = serializers.SerializerMethodField(read_only=True)
#对应的方法固定写法get_字段名
def get_publish_detail(self,obj): #这个obj 就是app01.models.Book
print(obj,type(obj))
return {'name':obj.publish.name,'city':obj.publish.city} # 返回所有作者信息
authors = serializers.SerializerMethodField(read_only=True)
def get_authors(self,obj):
return [{'name':author.name,'age':author.age} for author in obj.authors.all()]
| 序列化的两种方式 |
1 Serializers没有指定表模型
source:指定要序列化那个字段,可以是字段,可以是方法
SerializerMethodFields的用法
方式1:
authors = serializer.SerializerMethodField()
def get_authors(self,obj):
return {'name':obj.publish.name,'city':obj.publish.city}
#拓展性差 如果要查询一张表完整数据 那要写很多kv键值对 方式2:
class AuthorSerializer(serializer.Serializer):
name = serializer.CharField()
age = serializer.CharField() authors = serializer.SerializerMethodField()
def get_authors(self,obj):
ret = AuthorSerializer(instance=obj.authors.all(),man=True) #instance是默认参数可以不写
return ret.data
2 ModelSerializers:指定了表模型
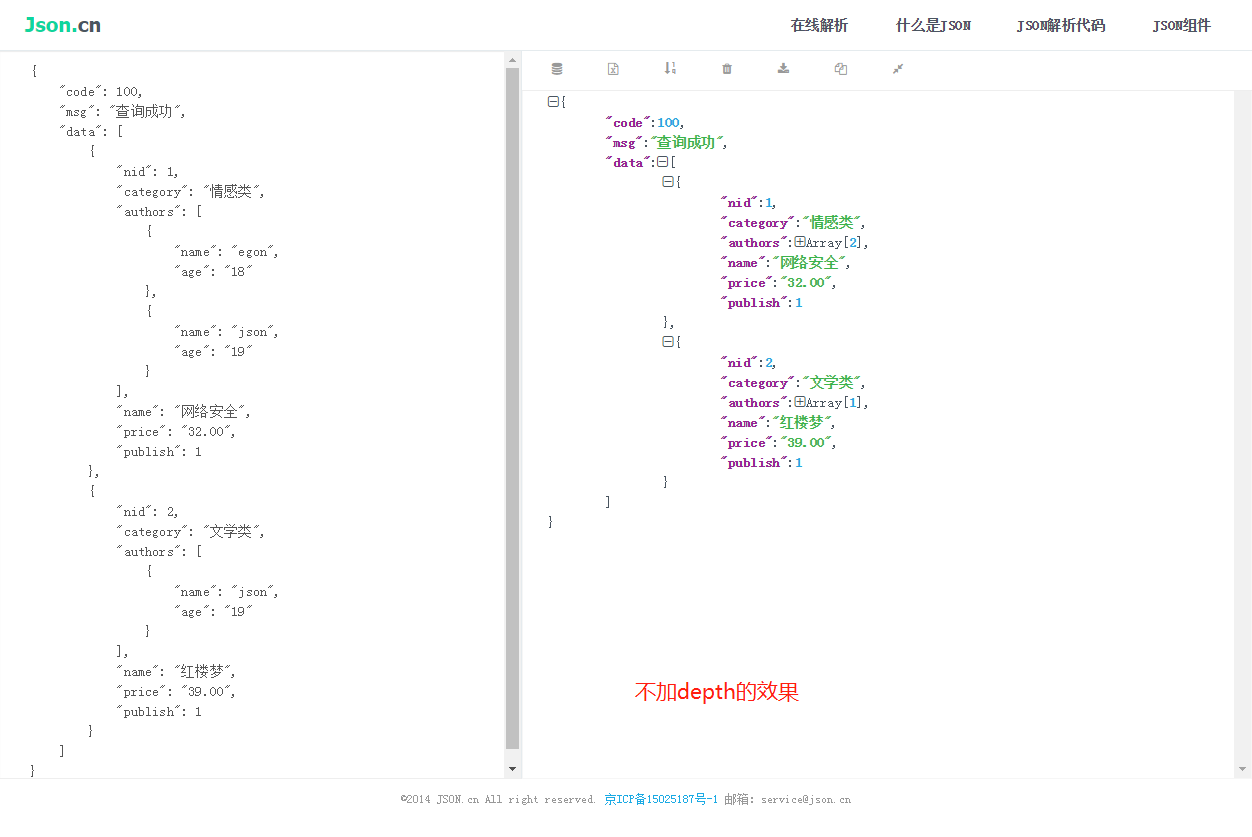
class Meta: model=表模型 fields = ('__all__')显示所有的字段 fields = ('id','name')显示部分字段 exclude=['name'] 排除这个字段其他内容都显示 不能和fields同时使用 depth=1跨表深度是1,官方建议不要超过10,个人建议不要超过3 重写某个字段 在Meta外部,重写某些字段,方式同Serializers
class AuthorSerializer(serializers.Serializer):
name = serializers.CharField()
age = serializers.CharField()
# class Meta:
# fields = ('__all__') serializers木有这个meta方法 只有modelserializer有 class BookSerializer(serializers.ModelSerializer):
class Meta:
model = models.Book #哪一张模型表
# fields = ('nid','name') #显示的字段
fields = ('__all__') #显示所有字段信息
# exclude = ['name'] #排除
# depth=1
# 深度是1,官方建议不要超过10,个人建议不要超过3
category = serializers.CharField(source='get_category_display')
authors = serializers.SerializerMethodField()
def get_authors(self,obj):
# 可以写列表生成式 如果是很多的话就要在生成式里面写很多 而且拓展性很差 可以继续写serializer
ret=AuthorSerializer(instance=obj.authors.all(),many=True)
return ret.data name5= serializers.CharField(source='name') #重写name字段 与meta同级别 方式和Serializers重写或者序列化组件一样


| 反序列化 |
1 使用继承了Serializers序列化类的对象,反序列化
json格式转成对象,保存到数据库
在保存之前一定要先调用 对象.is_valid()方法
在自己写的序列化类中重写create方法,反序列化
重写create放法,实现序列化(根据业务需求具体实现还是自定义create方法)
在序列化类中: 序列化类中写create方法表里面需要什么字段还是要传什么字段
from rest_framework import serializers # 序列化组件
class BookSerializer(serializers.Serializer):
#反序列化创建
def create(self, validated_data):
ret = models.Book.objects.create(**validated_data)
return ret
在视图中:
from app01.app01serializer import BookSerializer #自定义py文件里为了和view视图函数隔离开 自定义文件就写serializer组件 class Books(APIView):
#使用Serializers序列化类的对象,反序列化
def post(self,request):
#实例化产生一个序列化类的对象,data是要反序列化的字典
bookser = BookSerializer(data=request.data)
if bookser.is_valid():
#清洗通过的数据
ret = bookser.create(bookser.validated_data)
return Response()
2 使用继承了ModelSerializers序列化类的对象,反序列化
json格式转成对象,保存到数据库
在保存之前一定要先调用 对象.is_valid()
在视图中 在视图中写save() 表里面需要什么字段还是要传什么字段
from django.shortcuts import render,HttpResponse,redirect from rest_framework.views import APIView
from app01 import models from rest_framework.response import Response #返回用的 # 把对象转成json格式字符串
from app01.app01serializer import BookSerializer #自定义py文件里为了和view视图函数隔离开 自定义文件就写serializer组件 class Books(APIView): # 使用继承了ModelSerializers序列化类的对象,反序列化
def post(self,request):
#实例化产生一个序列化类的对象,data是要反序列的字典
bookser = BookSerializer(data=request.data)
if bookser.is_valid(raise_exception=True): #抛出的异常有异常就返回了 下面代码不执行 可以不写if判断
#清洗通过的数据
bookser.save()
| 反序列化的校验 |
反序列化的校验局部校验 validate_字段名(self,value):
如果校验失败,抛出ValidationError(抛出的异常信息需要去视图层bookser.errors中取)
如果校验通过直接return value
from rest_framework import exceptions 序列化类下面写:
#反序列化的校验(局部校验,全局校验)
def validate_name(self,value): print(value)
raise exceptions.ValidationError('不能以sb开头')
# if value.startswith('sb'):
# raise ValidationError('不能以sb开头')
# return value
视图层 post请求内 校验错误信息
def post(self,request):
#实例化产生一个序列化类的对象,data是要反序列化的字典
bookser=BookSerializer(data=request.data)
# bookser.data
if bookser.is_valid(raise_exception=True): 有异常就直接返回了 下面代码不会被执行 如果执行说明已经通过了
#清洗通过的数据
bookser.save()
else:
print(bookser.errors['name'][0])
return Response()
反序列化的校验全局 validate(self,attrs) attrs所有校验通过的数据,是个字典 如果校验失败,抛出ValidationError 如果校验通过直接返回return attrs
序列化组件类中
#去局校验
def validate(self,attrs):
print(attrs) return attrs
| 读源码分析 |
全局和局部钩子源码部分
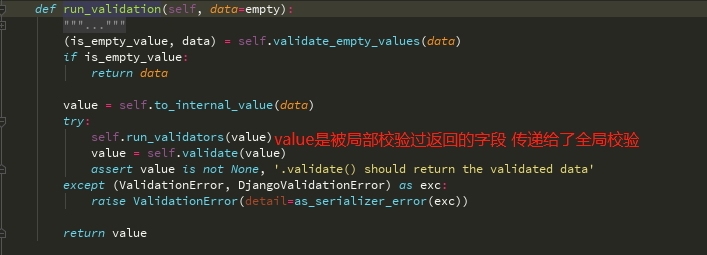
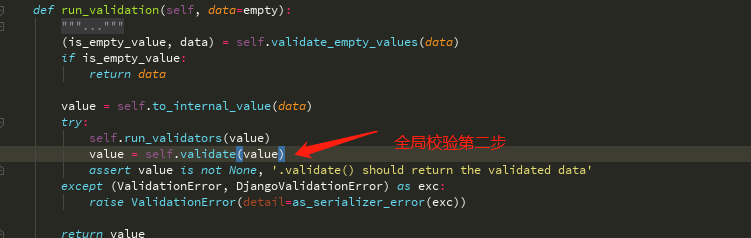
调用了bookser.is_valid方法才走校验---》Serlizer(没有is_valid)->BaseSerializer(is_valid) 走了self.run_validtaion方法(先从自身找)
(在Serializer找到)self.run_validation方法

Serializer中找to_internal_value

找所有的字段 于是就执行了局部校验的函数
于是就执行了局部校验的函数
全局校验
走自身的这个方法(Serializer的)
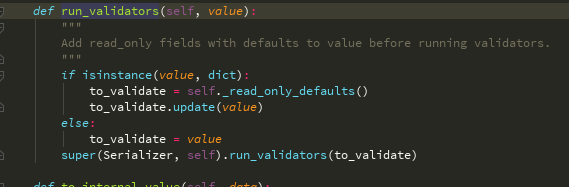

run_validators方法super继承run_validators--->BaseSerializer没有找--->Field中有这个方法 run_validators

然后全局校验的第一步走完了

在序列化的时候,传many=True和many=False,生成的对象并不是一个对象 Serializer中的基类BaseSerializer中的__new__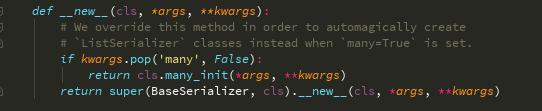
序列化对象.data 的时候做了什么事?
执行了Serializer内的data方法

又执行了父类(BaserSerializer)的data方法
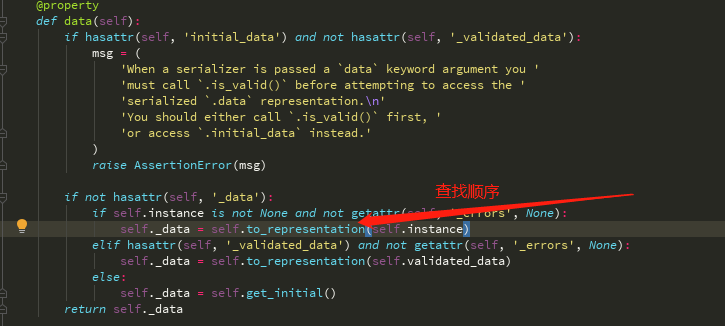
其实执行的是Serializer内的to_representation方法

最终执行的是每个字段对象的get_attribute方法
Serializer---》BaseSerializer ---》Field --》
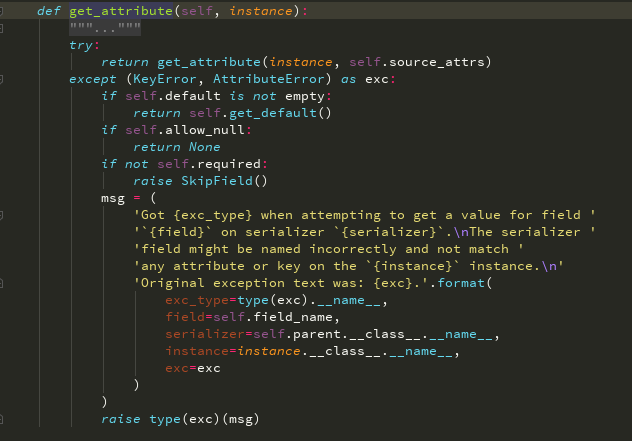
self.source_attrs Field类自己的方法

每个字段source后面指定的根据 点 切分 切分后的列表(publish.name:就会被分成[publish,name])
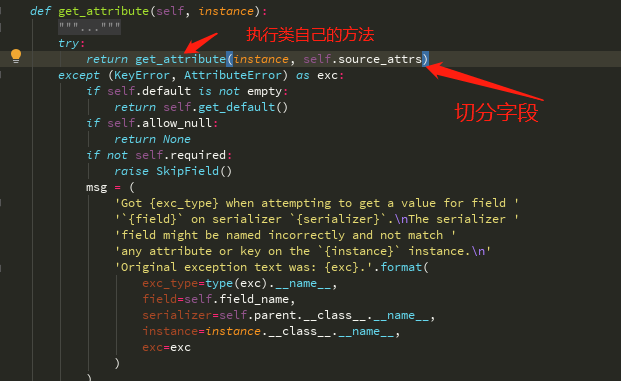
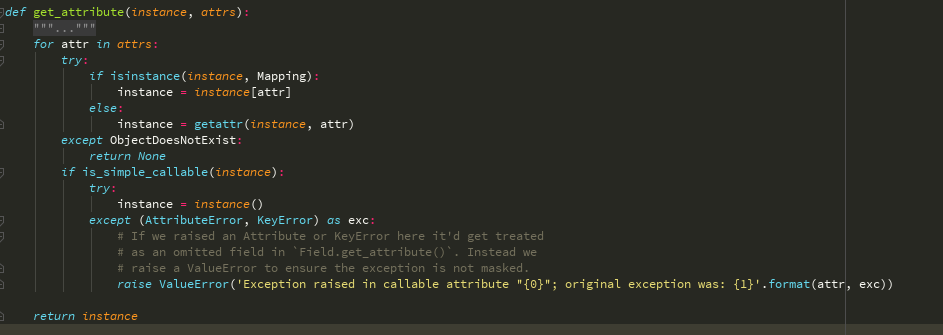
如果是方法会执行方法,如果是字段,通过反射取出值

Field类里面的方法
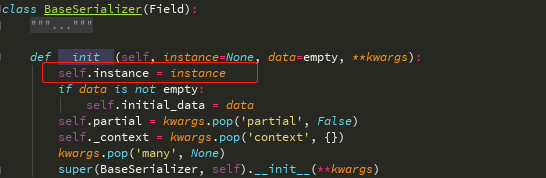
instance 当前序列化的对象(从data方法中看到self.instance就是当前序列化)
从BaseSerializer data中

而BaseSerializer初始化的时候
DRF 序列化组件 序列化的两种方式 反序列化 反序列化的校验的更多相关文章
- React组件导入的两种方式(动态导入组件的实现)
一. react组件两种导入方式 React组件可以通过两种方式导入另一个组件 import(常用) import component from './component' require const ...
- vue实现组件切换的两种方式
<!DOCTYPE html> <html> <head> <title>组件的切换</title> <meta charset=&q ...
- vue之provide和inject跨组件传递属性值失败(父组件向子组件传值的两种方式)
简单介绍:当一个子组件需要用到父组件的父组件的某些参数.那么这个时候为了避免组件重复传参,使用vue的依赖注入是个不错的方法,直接在最外层组件设置一个provide,内部不管多少嵌套都可以直接取到最外 ...
- Django学习——ajax发送其他请求、上传文件(ajax和form两种方式)、ajax上传json格式、 Django内置序列化(了解)、分页器的使用
1 ajax发送其他请求 1 写在form表单 submit和button会触发提交 <form action=""> </form> 注释 2 使用inp ...
- java 的对象拷贝(有深浅拷贝两种方式,深拷贝实现的两种方式(逐层实现cloneable接口,序列化的方式来实现))
Java提高篇--对象克隆(复制)(转自:http://www.cnblogs.com/Qian123/p/5710533.html#_label0) 阅读目录 为什么要克隆? 如何实现克隆 浅克 ...
- K:java中序列化的两种方式—Serializable或Externalizable
在java中,对一个对象进行序列化操作,其有如下两种方式: 第一种: 通过实现java.io.Serializable接口,该接口是一个标志接口,其没有任何抽象方法需要进行重写,实现了Serializ ...
- 一步步分析Java深拷贝的两种方式-clone和序列化
今天遇到一道面试题,询问深拷贝的两种方法.主要就是clone方法和序列化方法.今天就来分析一下这两种方式如何实现深拷贝.如果想跳过解析的朋友,直奔"重点来了!"寻找答案. clon ...
- react学习笔记1之声明组件的两种方式
//定义组件有两种方式,函数和类 function Welcome(props) { return <h1>Hello, {props.name}</h1>; } class ...
- 使用react定义组件的两种方式
react组件的两种方式:函数定义,类定义 在定义一个组件之前,首先要明白一点:react元素(jsx)是react组件的最基本的组成单位 组件要求: 1,为了和react元素进行区分,组件名字首必须 ...
随机推荐
- codeforces#1166F. Vicky's Delivery (Service并查集+启发式合并)
题目链接: https://codeforces.com/contest/1166/problem/F 题意: 给出节点数为$n$,边数为$m$的图,保证每个点对都是互连的 定义彩虹路:这条路经过$k ...
- 【洛谷2053】 [SCOI2007]修车(费用流)
传送门 洛谷 Solution 考虑把每一个修车工人拆成\(n\)个点,那么考虑令\(id(i,j)\)为第\(i\)个工人倒数第\(j\)次修车. 然后就可以直接跑费用流了!!! 代码实现 /* m ...
- Nginx之共享内存与slab机制
1. 共享内存 在 Nginx 里,一块完整的共享内存以结构体 ngx_shm_zone_t 来封装,如下: typedef struct ngx_shm_zone_s ngx_shm_zone_t; ...
- mysql中的utf8mb4、utf8mb4_unicode_ci、utf8mb4_general_ci的关系
mysql中的utf8mb4.utf8mb4_unicode_ci.utf8mb4_general_ci的关系 一.总结 一句话总结: utf8mb4是utf8的超集并完全兼容utf8,能够用四个字节 ...
- 订阅发布模式eventEmiter
// 订阅发布模式 class EventEmitter { constructor() { this._events = {}; } on(name, callback) { if (this._e ...
- LC 640. Solve the Equation
Solve a given equation and return the value of x in the form of string "x=#value". The equ ...
- LC 957. Prison Cells After N Days
There are 8 prison cells in a row, and each cell is either occupied or vacant. Each day, whether the ...
- VLAN和VXLAN的区别
VLAN ·概况 VLAN (Virtual Local Area Network)意为虚拟局域网,是在交换机实现过程中涉及到的概念,由802.1Q标准所定义.由于交换机是工作在链路层的网络设备,连接 ...
- IDEA 底部工具栏没有 Version Control 解决办法
百度了半天 都说VCS配置不对 但是默认IDEA是配置好的 根本不需要修改 忽然看到 工具栏的快捷键 于是 Alt + 9 就出现了 完美
- 使用robotframework做接口测试5——一个用例中调多个接口
凡是涉及一点点有接口关联的,都可能下一个接口需要上一个接口的某个返回值作为入参,最直接的例子,就是登录依赖.用接口做业务性的测试,也绝对离不开接口依赖的,业务都是一系列接口串联的结果,有时候一个接口操 ...