论文分享NO.3(by_xiaojian)
论文分享第三期-2019.03.29
Fully convolutional networks for semantic segmentation,CVPR 2015,FCN
一、全连接层与全局平均池化
在介绍FCN网络的全卷积连接之前,先介绍一下全连接层(fully connected layers)和全局平均池化(global average pooling)

以上两种实现GAP的方法,好像在程序中都有见过,也不太清楚那种更加合理,欢迎各位讨论指正。第二种方法中,卷积后面接激活函数;
二、FCN网络
优点:输入图像的尺寸任意,输出是与输入相同尺寸的语义分割图,即是像素级别的分类图。将浅层特征图谱和深层特征图谱反卷积的结果融合,再进行反卷积,使获得的结果兼具鲁棒性和细节。较浅层的结果更精细,较深层的结果更鲁棒。
缺点:仅借助卷积操作,考虑的图像中空间信息是局部的、不全面的。可以借助条件随机场CRF、非局部均值NML等方法改进。生成的结果细节表现能力有待提升。FCN是第一个端到端训练的、进行像素预测(语义分割)的全卷积网络。
FCN程序1-Marivn Teicha'mann/tensorflow-fcn,程序2-shelamer/fcn.berkeleyvision.org。本博文结合程序1,研究论文。
FCN-8算法框图:

框图中的模块说明:浅黄色的框和箭头表示卷积操作,正黄色的箭头表示反卷积操作,浅紫色的框表示最大池化,圆圈加号表示对应通道逐像素求和。紫红色的框为卷积操作得到的特征图,并非全连接层得到。
FCN-8模型,当输入图像为224x224x3时:
- 经过五组卷积和池化操作之后得到7x7x512大小的特征图谱,
- 然后用卷积操作代替传统的全连接层,第一个使用7x7的卷积核得到一个1x1x4096的特征图谱,第二个使用1x1的卷积核得到一个1x1x4096的特征图谱。
- 接下来为了得到像素级别的分类(语义分割),以VOC2007数据集为例,算上背景共有21类,所以将1x1x4096的特征图谱用1x1的卷积核得到一个1x1x21的类别图谱(程序中用score_fr表示),也就是一幅224x224大小的图像经过一系列的卷积操作后在21个各类别的概率得分,
- 然后进行反卷积得到整幅图像各像素点在21个各类别的概率得分。需要经过三次反卷积操作(正黄色的箭头),第一次1x1x21的类别图谱经过4x4、步长为2的卷积核,得到14x14x21的类别图谱(程序中用upscore表示),然后将pool-4输出的14x14x512特征图谱经过1x1、步长为1的卷积,得到14x14x21的类别图谱,最后再将两个类别图谱依通道逐像素求和,得到了融合浅层卷积特征的14x14x21的类别图谱。第二次与第一次反卷积的操作流程相同,最后得到的是28x28x21的类别图谱;第三次反卷积没有在融合更浅层的特征了,将28x28x21的类别图谱经过16x16、步长为8的卷积核,得到224x224x21的类别图谱,尺寸与输入的图像相同,
- 最后再转换为热力图可视化显示。
对于FCN-16,反卷积操作有两次,第一次使用4x4、步长为2的卷积核,第二次使用32x32、步长为16的卷积核。对于FCN-32,反卷积操作有一次,使用64x64、步长为32的卷积核(没有融合浅层的特征)。
FCN的一大特点就是允许任意尺寸的输入图像,对于不同尺寸的输入图像,所使用的操作都是上述框图中的,区别在于特征图谱的尺寸。如下图所示为全卷积网络,
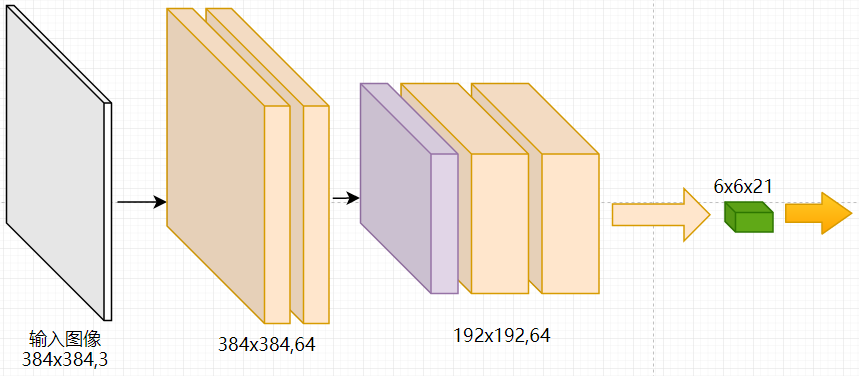
当输入为384×384的图像时:
- 经过五组卷积和池化操作后,pool-5的输出为12x12x512,
- 然后使用两个卷积核分别为7x7和1x1的全卷积操作,得到的输出为6x6x4096(输入尺寸=卷积核大小+步长x(输出尺寸-1)),
- 再使用1x1的卷积核得到6x6x21的类别图谱。
- 接下来就是框图中的三次反卷积操作,最终得到384x384x21的类别图谱,
以上的反卷积层因为是于pool-4和pool-3的尺寸对应,因此不受输入尺寸的影响。对比使用全连接层时的操作,因为需要将pool-5的特征图谱reshape成一条特征向量,对于224的输入,特征向量维度为7x7x512,则全连接层的权值尺寸为(7x7x512,4096);对于384的输入,特征向量维度为12x12x512,则全连接层的权值尺寸为(12x21x512,4096),全连接层的权值尺寸发生变化而不能训练。
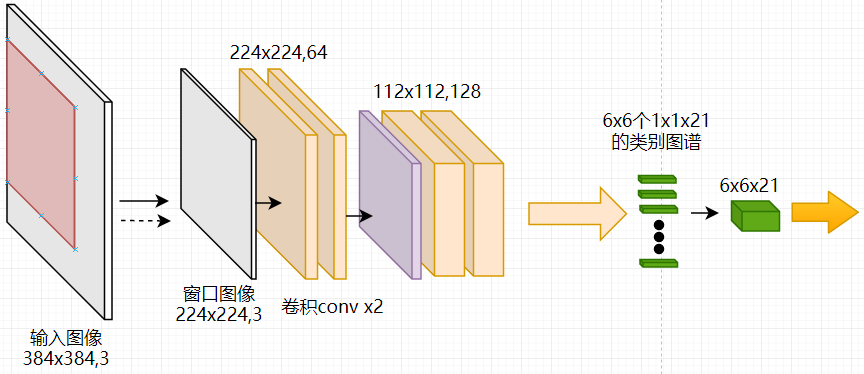
如下图为带有全连接层的网络,对于384的输入图像,当使用224×224尺寸的窗口、步长为32在384×384的图片上滑动,可以得到6x6个224x224的输入图像送给带全连接层的网络,然后得到6x6x21的类别图谱,与直接使用全卷积网络是相同的,但是使用全卷积网络效率更高。
三、Tensorflow中卷积与反卷积
卷积:tf.nn.conv2d(x, W, strides, padding=" ")
卷积核:W=[k, k, input_channel, output_channel]
反卷积:tf.nn.conv2d_transpose(x, W, output_shape, strides, padding=" ")
卷积核:W=[k, k, output_channel, input_channel]
输出尺寸:output_shape=[out_feature_h, out_feature_w, output_channel],out_feature_h、w为指定的输出尺寸
论文分享NO.3(by_xiaojian)的更多相关文章
- 论文分享NO.4(by_xiaojian)
论文分享第四期-2019.04.16 Residual Attention Network for Image Classification,CVPR 2017,RAN 核心:将注意力机制与ResNe ...
- 论文分享NO.2(by_xiaojian)
论文分享第二期-2019.03.26 NIPS2015,Spatial Transformer Networks,STN,空间变换网络
- 论文分享NO.1(by_xiaojian)
论文分享第一期-2019.03.14: 1. Non-local Neural Networks 2018 CVPR的论文 2. Self-Attention Generative Adversar ...
- [论文分享] DHP: Differentiable Meta Pruning via HyperNetworks
[论文分享] DHP: Differentiable Meta Pruning via HyperNetworks authors: Yawei Li1, Shuhang Gu, etc. comme ...
- 论文分享|《Universal Language Model Fine-tuning for Text Classificatio》
https://www.sohu.com/a/233269391_395209 本周我们要分享的论文是<Universal Language Model Fine-tuning for Text ...
- Graph Transformer Networks 论文分享
论文地址:https://arxiv.org/abs/1911.06455 实现代码地址:https://github.com/ seongjunyun/Graph_Transformer_Netwo ...
- AAAI 2020论文分享:通过识别和翻译交互打造更优的语音翻译模型
2月初,AAAI 2020在美国纽约拉开了帷幕.本届大会百度共有28篇论文被收录.本文将对其中的机器翻译领域入选论文<Synchronous Speech Recognition and Spe ...
- [论文分享]Channel Pruning via Automatic Structure Search
authors: Mingbao Lin, Rongrong Ji, etc. comments: IJCAL2020 cite: [2001.08565v3] Channel Pruning via ...
- DNN论文分享 - Item2vec: Neural Item Embedding for Collaborative Filtering
前置点评: 这篇文章比较朴素,创新性不高,基本是参照了google的word2vec方法,应用到推荐场景的i2i相似度计算中,但实际效果看还有有提升的.主要做法是把item视为word,用户的行为序列 ...
随机推荐
- SSL握手通信详解及linux下c/c++ SSL Socket代码举例(另附SSL双向认证客户端代码)
SSL握手通信详解及linux下c/c++ SSL Socket代码举例(另附SSL双向认证客户端代码) 摘自: https://blog.csdn.net/sjin_1314/article/det ...
- T31P电子秤数据读取
连接串口后先发送"CP\r\n"激活电子秤数据发送,收到的数据包是17字节的 using System; using System.Collections.Generic; usi ...
- RocketMQ runbroker.sh 分析JVM启动参数
runbroker.sh #====================================================================================== ...
- jdb调试程序
1) jdb调试正在运行的进程: 先使用jps先确定进程号,然后让jdb连接上目标进程(23549换成实际的进程号): jdb -connect sun.jvm.hotspot.jdi.SAPIDAt ...
- Restful风格wcf调用2——增删改查
写在前面 上篇文章介绍如何将wcf项目,修改成restful风格的接口,并在上面提供了查询的功能,上篇文章中也感谢园友在评论中的提的建议,自己也思考了下,确实是那个道理.在urltemplate中,定 ...
- Google Tango Java SDK开发:Motion Tracking 运动追踪
Java API Motion Tracking Tutorial运动追踪教程 This page describes how the Java API handles motion tracking ...
- Chain Of Responsibility Design Pattern Example
Avoid coupling the sender of a request to the receiver by giving more than one object a chance to ha ...
- 如何注册GitHub
一.个人介绍 姓名:张志龙 学号:1413042026 班级:网工141 爱好:宅物 能力:c++编程 二.注册 注册GitHub其实很简单 首先我们要做的是打开官网 www.github.com(如 ...
- 自己写一个图片按钮(XAML)
有时需要用三张图片(正常状态,鼠标移上,鼠标按下)来作为一个按钮的样式,虽然这种做法不好,应该用矢量的方式制作样式,但有的时候还是需要这样做的. 每次都修改按钮的样式来实现这个做法,既麻烦又会生成大段 ...
- Markdown编辑器——常用语法
Markdown是什么? 简短来说,他就是一款特别适用于写博客的编辑器.为什么适合呢,因为它特别的方便.以博客园的编辑界面来说,它原本的界面是这样的(有没有一种Word2003的既视感): 但是,当你 ...