selenium + python自动化测试unittest框架学习(三)webdriver元素定位(一)
1.Webdriver原理
webdirver是一款web自动化操作工具,为浏览器提供统一的webdriver接口,由client也就是我们的测试脚本提交请求,remote server浏览器进行响应请求,相对于原来selenium1中的selenium rc更加的简便,对浏览器的操作更加灵活。
2.定位
(1)元素的定位:
元素的定位可以通过id,name,class name,tag name,link_text,partial_link_text,css selector,xpath等
语法格式为:find_element_by_xxxx()
例如百度的搜索框
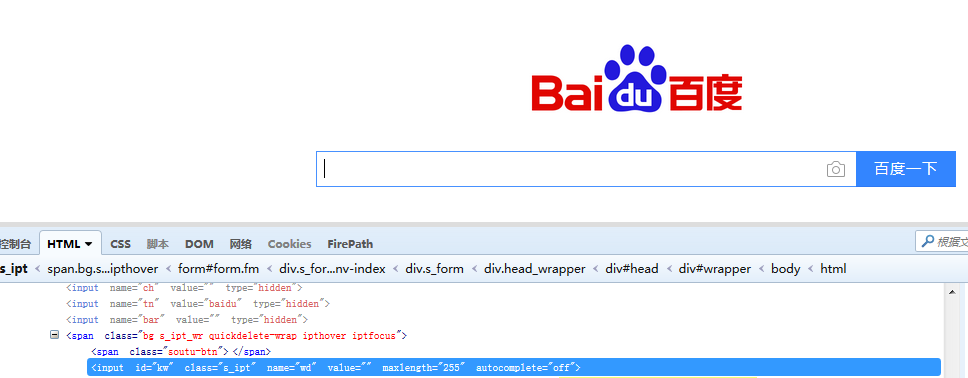
如果想要定位百度搜索框则可以
find_element_by_id("kw") or find_element_by_class_name("s_pt") or find_element_by_name("wd") or find_element_by_tag_name("input")
或者通过xpath定位:可以使用FirePath工具定位:
xpath:find_element_by_xpth(".//*[@id='kw']")
如果是一个文本链接可以通过link_name("文本")或者文本信息较长的可以通过部分文本信息来定位partial_link_text("部分文本")
以上的所有定位准确前提是必须保证定位元素括号中填写的信息的唯一性,才可以准确定位到元素上,例如定位class_name,必须确定仅有该元素应用到该calss name,否则请更换其他的定位方式。
有关元素的定位一般还是建议有id的,有name的,用这两者定位更加准确,xpath也是一个重要的定位方式。
*.xpath定位
虽然说xpath定位可以借用类似FirePath这样的工具来获取,但是我们还是必须清楚xpath定位的语法,以便后期我们在修改代码的时候能够清楚元素到底定位的是哪个。
xpath的路径表达式:
| 路径表达式 | 结果 |
|---|---|
| bookstore | 选取 bookstore 元素的所有子节点。 |
| /bookstore |
选取根元素 bookstore。 注释:假如路径起始于正斜杠( / ),则此路径始终代表到某元素的绝对路径! |
| bookstore/book | 选取属于 bookstore 的子元素的所有 book 元素。 |
| //book | 选取所有 book 子元素,而不管它们在文档中的位置。 |
| bookstore//book | 选择属于 bookstore 元素的后代的所有 book 元素,而不管它们位于 bookstore 之下的什么位置。 |
| //@lang | 选取名为 lang 的所有属性。 |
带谓语的表达式,谓语用中括号括描述,选取所有可以用*
| 路径表达式 | 结果 |
|---|---|
| /bookstore/book[] | 选取属于 bookstore 子元素的第一个 book 元素。 |
| /bookstore/book[last()] | 选取属于 bookstore 子元素的最后一个 book 元素。 |
| /bookstore/book[last()-1] | 选取属于 bookstore 子元素的倒数第二个 book 元素。 |
| /bookstore/book[position()<3] | 选取最前面的两个属于 bookstore 元素的子元素的 book 元素。 |
| //title[@lang] | 选取所有拥有名为 lang 的属性的 title 元素。 |
| //title[@lang='eng'] | 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 |
| /bookstore/book[price>35.00] | 选取 bookstore 元素的所有 book 元素,且其中的 price 元素的值须大于 35.00。 |
| /bookstore/book[price>35.00]/title | 选取 bookstore 元素中的 book 元素的所有 title 元素,且其中的 price 元素的值须大于 35.00。 |
(2)定位一组对象
定位单个元素是find_element,那么定位一组对象则是find_elements
定位一组对象的情况是对需要对一组对象进行批量操作或者是需要选取多个条件一样或类似的元素,其是先选取一组对象后再根据筛选条件进行遍历过滤最终定位所需的符合条件的元素。
例如:勾选所有的checbox元素或者是对一组元素做同样的操作的时候
checbox = find_elements_by_xx() #首先定位一组元素
for i in checkbox: #遍历勾选所有checkbox
i.click()
(3)层级定位
很多元素都没有规范的id或者name来定位,而且元素的class name和tag name都是一样的,且又是第几层的元素,很难定位,所以定位该元素的方法是,先定位父级元素,然后再定位子级元素
例如:菜单list中子级菜单标签的定位
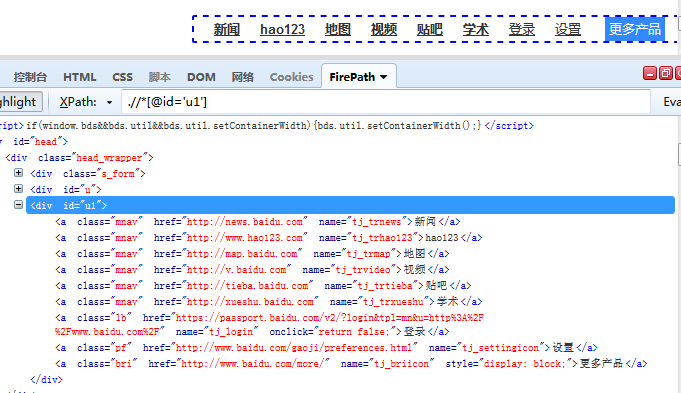
如果要定位新闻标签,我们可以通过先定位ul元素,再定位a元素,这样定位比较准确
parent = find_element_by_id("ul")
children = parent.find_element_by_name("tj_tnews")
chidren.click()
(4)定位Frame中的对象
有些页面的框架嵌套着另一个框架,如果需要定位被嵌套的框架里的内容则可以先定位到外部框架,再定位到被嵌套的框架,然后就可以定位里面的页面元素,其实这个思路和定位层级元素是一样的,只是这里用到定位框架的语句需要记下
switch_to_frame(id)
例如:框架A嵌套这框架B,现在需要定位框架B中的文本框
switch_to_frame(id = a)
switch_to_frame(id = b)
find_element_by_id("textboxid")
定位弹出的框架后操作完成需要跳出框架才可以定位原先页面上的元素。
driver.switch_to_frame("layui-layer-iframe1") #定位框架
.....
driver.switch_to_default_content() 跳出框架
driver.find_element_by_xpath("html/body")
selenium + python自动化测试unittest框架学习(三)webdriver元素定位(一)的更多相关文章
- selenium + python自动化测试unittest框架学习(二)
1.unittest单元测试框架文件结构 unittest是python单元测试框架之一,unittest测试框架的主要文件结构: File >report >all_case.py &g ...
- selenium + python自动化测试unittest框架学习(五)webdriver的二次封装
因为webdriver的api方法很长,再加上大多数的定位方式是以xpath方式定位,更加让代码看起来超级长,为了使整体的代码看起来整洁,对webdriver进行封装,学习资料来源于虫师的<se ...
- selenium + python自动化测试unittest框架学习(一)selenium原理及应用
unittest框架的学习得益于虫师的<selenium+python自动化实践>这一书,该书讲得很详细,大家可以去看下,我也只学到一点点用于工作中,闲暇时记录下自己所学才能更加印象深刻. ...
- selenium + python自动化测试unittest框架学习(三)webdriver对页面其他控件操作(三)
1.对话框,下拉框 (1)对话框的有两种,一种是iframe格式的,需要switch_to_iframe()进行定位,现在大部分的对话框是div格式的,这种格式的可以通过层级定位来定位元素,先定位对话 ...
- selenium + python自动化测试unittest框架学习(三)webdriver元素操作(二)
上一篇是元素的定位,那么定位元素的目的就是对元素进行操作,例如写入文本,点击按钮,拖动等等的操作 (1)简单元素操作 简单元素操作 find_element_by_id("kw") ...
- selenium + python自动化测试unittest框架学习(七)随机生成姓名
在自动化测试过程中经常要测试到添加用户的操作,每次都要输入中文,原本是找了十几个中文写成了列表,然后从列表中随机取出填入用户名文本框中,随着测试的增加,发现同名的人搜索出来一大堆,最后在网上找了个随机 ...
- selenium + python自动化测试unittest框架学习(四)python导入模块及包知识点
在写脚本的时候,发现导入某些模块,经常报错提示导入模块失败,这里来恶补下python导入模块的知识点. 1.模块导入时文件查找顺序 在脚本中,import xxx模块时的具体步骤: (1)新建一个mo ...
- selenium + python自动化测试unittest框架学习(六)分页
接触的项目分页的形式是以下形式: 想要获取总页数后,遍历执行翻页的功能,但由于分页是以javascript方法实现的,每次点击确定按钮后,页面就回刷新,webelement元素过期无法遍历下一个进行翻 ...
- selenium + python 自动化测试环境搭建
selenium + python 自动化测试 —— 环境搭建 关于 selenium Selenium 是一个用于Web应用程序测试的工具.Selenium测试直接运行在浏览器中,就像真正的用户在操 ...
随机推荐
- EMC光纤交换机故障处理和命令分析
主机没有Login到存储是一个比较常见的故障,故障多发于主机新上线,或者是重启后.例如在Unisphere中,显示Host状态是”Registered: Yes; Logged In: No” ...
- BZOJ2960:跨平面
题面 BZOJ Sol 对该平面图的对偶图建图后就是最小树形图,建一个超级点向每个点连 \(inf\) 边即可 怎么转成对偶图,怎么弄出多边形 把边拆成两条有向边,分别挂在两个点上 每个点的出边按角度 ...
- 洛谷P4781 【模板】拉格朗日插值(拉格朗日插值)
题意 题目链接 Sol 记得NJU有个特别强的ACM队叫拉格朗,总感觉少了什么.. 不说了直接扔公式 \[f(x) = \sum_{i = 1}^n y_i \prod_{j \not = i} \f ...
- FineReport和泛微OA(Ecology)的单点登录集成方案
最近出现了很多关于帆软报表和泛微OA的集成问题,均出现在“单点登录”上.直接也有相关的文章介绍一些FineReport和泛微集成的背景.价值等,以及FineReport和OA的深度集成的方案,但是并没 ...
- html5 移动端开发
移动端开发总结 目录 1.手机与浏览器 2.Viewport(视窗) 3. 媒体查询 4.px,em,rem,pt 5.设备像素比devicePixelRatio 6.移动web中的图标及字体 ...
- [学习] nofollow
[来源:百度百科 http://baike.baidu.com/view/1584081.htm] 简介 nofollow[1]是一个HTML标签的属性值.它的出现为网站管理员提供了一种方式,即告诉搜 ...
- js脚本快速评课----中科大教务系统
git地址:https://github.com/hzphzp/js_ustc_mis_teach 代码 for(var i = 1; i < document.getElementsByTag ...
- Linux /etc/fstab文件
一,作用 /etc/fstab是用来存放文件系统的静态信息的文件,当系统启动时,系统会自动地从这个文件读取信息,并且会自动将此文件中指定的文件系统挂在到执行的目录 二,挂载的限制 1,根目录是必须挂载 ...
- sequelize 学习之路
如果你觉得Sequelize的文档有点多.杂,不方便看,可以看看这篇. 在使用NodeJS来关系型操作数据库时,为了方便,通常都会选择一个合适的ORM(Object Relationship Mode ...
- C# Array类的Sort()方法
Array类实现了数组中元素的冒泡排序.Sort()方法要求数组中的元素实现IComparable接口.如System.Int32 和System.String实现了IComparable接口,所以下 ...