【POI word】使用POI实现对Word的读取以及生成
项目结构如下:
那第一部分:先是读取Word文档
package com.it.WordTest; import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
import java.util.Date;
import java.util.List; import org.apache.poi.POIXMLProperties.CoreProperties;
import org.apache.poi.xwpf.extractor.XWPFWordExtractor;
import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.poi.xwpf.usermodel.XWPFTable;
import org.apache.poi.xwpf.usermodel.XWPFTableCell;
import org.apache.poi.xwpf.usermodel.XWPFTableRow;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTPPr;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTTblPr; /**
* 读取docx文件
* @author Administrator
*POI在读写word docx文件时是通过xwpf模块来进行的,其核心是XWPFDocument。一个XWPFDocument代表一个docx文档,其可以用来读docx文档,也可以用来写docx文档。
*XWPFDocument中主要包含下面这几种对象:
*XWPFParagraph:代表一个段落。
*XWPFRun:代表具有相同属性的一段文本。
*XWPFTable:代表一个表格。
*XWPFTableRow:表格的一行。
*XWPFTableCell:表格对应的一个单元格。
*/
public class ReadWord { /**
* 通过XWPFWordExtractor读取word文档
* 只能获取到文本,不能获取到文本对应的属性值
*/
public static void readByXWPFWordExtractor(){
try {
FileInputStream input = new FileInputStream("f:/test/肥胖早知道模板.docx");
XWPFDocument doc = new XWPFDocument(input);
XWPFWordExtractor docE = new XWPFWordExtractor(doc);
String text = docE.getText();
//将读取到文档中的文本信息,存放在一个txt文件中
FileWriter write = new FileWriter("f:/test/肥胖早知道的文本信息.txt");
write.write(text);
write.close(); //获取文档的附属信息
CoreProperties coreP = docE.getCoreProperties();
//打印文档的分类信息
System.out.println(coreP.getCategory());
//打印创建者信息
System.out.println(coreP.getCreator());
//打印创建时间
System.out.println(coreP.getCreated());
//打印标题
System.out.println(coreP.getTitle()); input.close();
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
} /**
* 通过XWPFDocument读取word文档
* 通过XWPFDocument读取docx文档时,我们就可以获取到文本比较精确的属性信息了。比如我们可以获取到某一个XWPFParagraph、XWPFRun或者是某一个XWPFTable,包括它们对应的属性信息
*/
public static void readByXWPFDocument(){
Date data = new Date();
try {
FileInputStream inputStream = new FileInputStream("f:/test/肥胖早知道模板.docx");
XWPFDocument doc =new XWPFDocument(inputStream);
//获取所有段落
List<XWPFParagraph> list = doc.getParagraphs();
FileWriter writer = new FileWriter("f:/test/肥胖早知道 带属性.txt");
StringBuffer str = new StringBuffer();
for (XWPFParagraph xwpfParagraph : list) {
//获取当前段落的属性
CTPPr CPPR = xwpfParagraph.getCTP().getPPr();
str.append(xwpfParagraph.getText());
}
writer.write(str.toString()); //获取多有table
List<XWPFTable> tableList = doc.getTables();
List<XWPFTableRow> rowList;
List<XWPFTableCell> cellList;
StringBuilder build = new StringBuilder();
for (XWPFTable xwpfTable : tableList) {
//获取表格信息
CTTblPr tablePer = xwpfTable.getCTTbl().getTblPr();
//获取表格相对应的行
rowList =xwpfTable.getRows();
for (XWPFTableRow xwpfTableRow : rowList) {
cellList = xwpfTableRow.getTableCells();
for (XWPFTableCell xwpfTableCell : cellList) {
build.append("【单元格信息】:"+xwpfTableCell.getText()+"\r\n");
}
}
}
writer.append(build);
writer.close(); inputStream.close(); Date date2 = new Date();
System.out.println("消耗时间:"+(date2.getTime()-data.getTime())+"ms");
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
} public static void main(String[] args) {
//readByXWPFWordExtractor();
readByXWPFDocument();
}
}
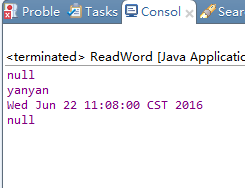
在读取到word的附属信息,会在控制台打印如下:
第二部分:生成Word
package com.it.WordTest; import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.math.BigInteger;
import java.util.List; import org.apache.poi.xwpf.usermodel.XWPFDocument;
import org.apache.poi.xwpf.usermodel.XWPFParagraph;
import org.apache.poi.xwpf.usermodel.XWPFRun;
import org.apache.poi.xwpf.usermodel.XWPFTable;
import org.apache.poi.xwpf.usermodel.XWPFTableCell;
import org.apache.poi.xwpf.usermodel.XWPFTableRow;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTPPr;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTTblPr;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTTblWidth;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTTcPr;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.CTTrPr;
import org.openxmlformats.schemas.wordprocessingml.x2006.main.STVerticalJc; public class WriteWord { public static void writeXWPFDocument(){ try {
//创建一个word文档
XWPFDocument xwpfDocument = new XWPFDocument();
FileOutputStream outputStream = new FileOutputStream("F:/test/word1.docx");
/**
* 创建一个段落
*/
XWPFParagraph paragraph = xwpfDocument.createParagraph();
XWPFRun run = paragraph.createRun();
run.setText("德玛西亚!!");
//加粗
run.setBold(true); run = paragraph.createRun();
run.setText("艾欧尼亚");
run.setColor("fff000"); /**
* 创建一个table
*/
//创建一个10行10列的表格
XWPFTable table =xwpfDocument.createTable(10, 10);
//添加新的一列
table.addNewCol();
//添加新的一行
table.createRow();
//获取表格属性
CTTblPr tablePr = table.getCTTbl().addNewTblPr();
//获取表格宽度
CTTblWidth tableWidth = tablePr.addNewTblW();
//设置表格的宽度大小
tableWidth.setW(BigInteger.valueOf(8000)); /**
* 获取表格中的行 以及设计行样式
*/
//获取表格中的所有行
List<XWPFTableRow> rowList = table.getRows();
XWPFTableRow row;
row = rowList.get(0);
row.setHeight(2000);
//为这一行增加一列
row.addNewTableCell();
//获取行属性
CTTrPr rowPr = row.getCtRow().addNewTrPr();
row.getCtRow(); /**
* 获取表格中的列 以及设计列样式
*/
//获取某个单元格
XWPFTableCell cell ;
cell = row.getCell(0);
cell.setText("第一行\r\n第一列");
//单元格背景颜色
cell.setColor("676767");
//获取单元格样式
CTTcPr cellPr = cell.getCTTc().addNewTcPr();
//表格内容垂直居中
cellPr.addNewVAlign().setVal(STVerticalJc.CENTER);
//设置单元格的宽度
cellPr.addNewTcW().setW(BigInteger.valueOf(5000)); xwpfDocument.write(outputStream);
outputStream.close(); } catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
writeXWPFDocument();
}
}
生成word如下:

唯一的感觉就是 功能实现的太简单,没有涉及到核心的部分,感觉 不美丽!!!
【POI word】使用POI实现对Word的读取以及生成的更多相关文章
- python 使用win32com实现对word文档批量替换页眉页脚
最近由于工作需要,需要将70个word文件的页眉页脚全部进行修改,在想到这个无聊/重复/没有任何技术含量的工作时,我的内心是相当奔溃的.就在我接近奔溃的时候我突然想到完全可以用python脚本来实现这 ...
- jeecms系统使用介绍——通过二次开发实现对word、pdf、txt等上传附件的全文检索
转载请注明出处:http://blog.csdn.net/dongdong9223/article/details/76912307 本文出自[我是干勾鱼的博客] 之前在文章<基于Java的门户 ...
- C#实现对Word文件读写[转]
手头上的一个项目报表相对比较简单,所以报表打印采用VBA引擎,通过定制Word模版,然后根据模版需要填充数据,然后OK,打印即可. 实现方法:首先需要引用VBA组建,我用的是Office2003 Pr ...
- 利用COM组件实现对WORD书签处写入值
using System; using System.Collections.Generic; using System.Text; using Microsoft.Office.Interop.Wo ...
- 利用COM组件实现对WORD书签各种操作大全,看这一篇就够了
有个需求是,程序导出一份word报告,报告中有各种各样的表格,导出时还需要插入图片. 脑海中迅速闪过好几种组件,openxml组件,com组件,npoi.为了减少程序画复杂表格,我们选用了com组件+ ...
- 使用 xlrd 模块实现对excel 的读取、excel转json 、excel 转 mysql insert 语句
#-*- coding:utf-8 -*- # 处理 excel 中的 area 为 Mysql insert 语句 import xlrd, json, codecs, os # data = xl ...
- Apache POI 实现对 Excel 文件读写
1. Apache POI 简介 Apache POI是Apache软件基金会的开放源码函式库. 提供API给Java应用程序对Microsoft Office格式档案读和写的功能. 老外起名字总是很 ...
- 基于DevExpress实现对PDF、Word、Excel文档的预览及操作处理
http://www.cnblogs.com/wuhuacong/p/4175266.html 在一般的管理系统模块里面,越来越多的设计到一些常用文档的上传保存操作,其中如PDF.Word.Excel ...
- JAVA-----基于POI实现对Excel导入
在日常项目开发中, 数据录入和导出是十分普遍的需求,因此,导入导出也成为了开发中一个经典的功能.数据导出的格式一般是excel或者pdf,而批量导入的信息一般是借助excel来减轻工作量,提高效率. ...
随机推荐
- Python处理JSON数据
python解析json时为了方便,我们首先安装json模块,这里选择demjson,官方网址是:http://deron.meranda.us/python/demjson/ 访问之后点击页面的的D ...
- ACM/ICPC 之 Floyd范例两道(POJ2570-POJ2263)
两道以Floyd算法为解法的范例,第二题如果数据量较大,须采用其他解法 POJ2570-Fiber Network //经典的传递闭包问题,由于只有26个公司可以采用二进制存储 //Time:141M ...
- MongoDB 副本集管理(不定时更新)
简介: 前面介绍完了副本集的搭建.用户的管理.参数和日常操作的说明,那副本集搭建好该如何管理呢?现在来说明下副本集的日常查看和管理. 说明: 1)查看命令行参数:db.serverCmdLineOpt ...
- Struts2常用标签
Struts2常用标签总结 一 介绍 1.Struts2的作用 Struts2标签库提供了主题.模板支持,极大地简化了视图页面的编写,而且,struts2的主题.模板都提供了很好的扩展性.实现了更好的 ...
- Mathematics:Raising Modulo Numbers(POJ 1995)
阶乘总和 题目大意:要你算一堆阶乘对m的模... 大水题,对指数二分就可以了... #include <iostream> #include <functional> #inc ...
- 【leetcode】Best Time to Buy and Sell 3 (hard) 自己做出来了 但别人的更好
Say you have an array for which the ith element is the price of a given stock on day i. Design an al ...
- 基于Spring的可扩展Schema进行开发自定义配置标签支持
一.背景 最近和朋友一起想开发一个类似alibaba dubbo的功能的工具,其中就用到了基于Spring的可扩展Schema进行开发自定义配置标签支持,通过上网查资料自己写了一个demo.今天在这里 ...
- jquery.validation.js 表单验证
jquery.validation.js 表单验证 官网地址:http://bassistance.de/jquery-plugins/jquery-plugin-validation jQuer ...
- merge
当两个DataFrame相加的时候,如果,其中一个不全则会相加产生NA,所以必须一次性将数据的索引索引确定下来,然后对所有数据重建索引然后,填充0,再相加.否则有数据的和没数据的相加结果都变为了NA, ...
- request.getParameter 乱码问题
个简单的问题,我想追究一下深层次的原因: 前台的编码格式HTML里面的是utf-8的;; 但是后台使用request.getParameter("groupName");乱码; 我 ...