hadoop的扩容
一、横向扩容(参见:https://www.cnblogs.com/yangy1/p/12362565.html)
现在在此基础上再添加一个节点
1、克隆一台主机hdp03(克隆hdp02)
修改ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33 IPADDR=192.168.0.43
修改主机名及添加主机映射
vim /etc/hostname hdp03
vim /etc/hosts 192.168.0.43 hdp03
删除tmp下的目录文件
cd /opt/software/hadoop-2.7./tmp rm -rf *
2、配置主(有namenode服务的主机)
添加主机映射
vim /etc/hosts 192.168.0.32 hdp01
192.168.0.42 hdp02
192.168.0.43 hdp03 //添加新的映射
配置slaves
vim /opt/software/hadoop-2.7./etc/hadoop/slaves hdp01
hdp02
hdp03 //添加新的主机名
3、启动hdp03的datanode
hadoop-daemon.sh start datanode //启动datanode
因为克隆的hdp02,所以和hdp02的私钥一样,不需要重新生成,hdp01可以直接访问
4、访问50070端口

可以看到节点添加上去了,变成了3个。
二、纵向扩容
纵向扩容在hdp01上添加一块新的硬盘
1、在虚拟机目录点击右键——>设置——>添加——>硬盘
然后用默认的配置一直点击下一步添加成功
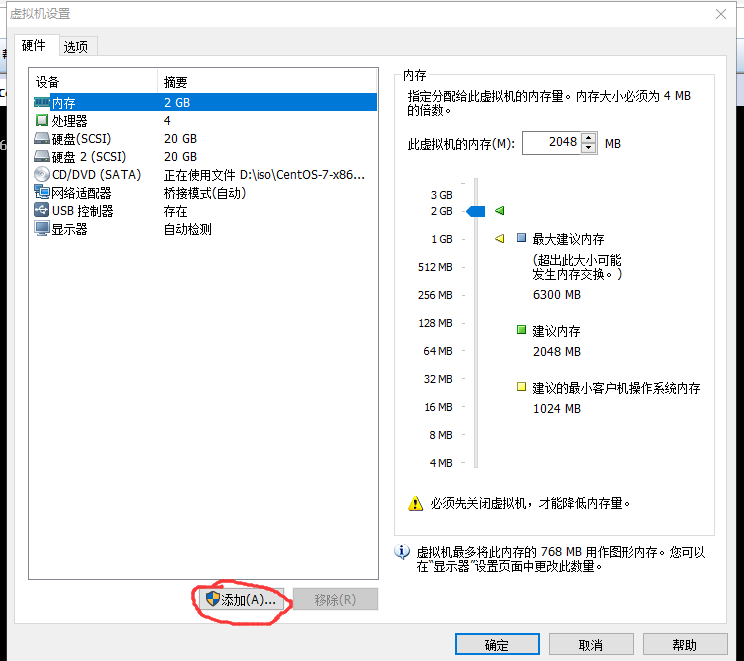
重启虚拟机
reboot
2、将硬盘分区并挂载
在/dev里可以看到新添加的硬盘sdb
cd /dev

分区
fdisk sdb m //查看帮助选项 n //添加分区 p //选择主分区 +10G //添加10G w //保存并退出
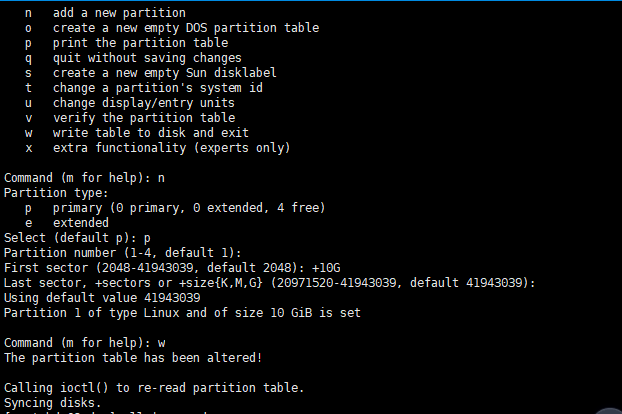
再次查看可以看到分区成功sdb1

挂载
先在根目录新建文件夹
cd /
mkdir sdb1 mount /dev/sdb1 /sdb1
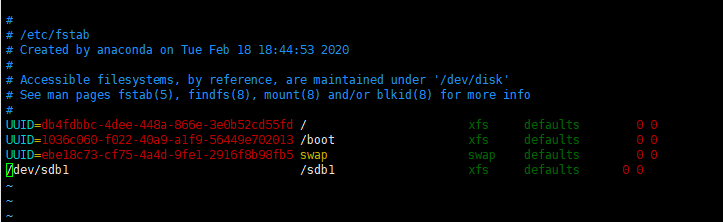
mount的挂载重启后就失效,要想永久挂载需要修改配置
vim /etc/fstab /dev/sdb1 /sdb1 xfs defaults 0 0 //添加配置
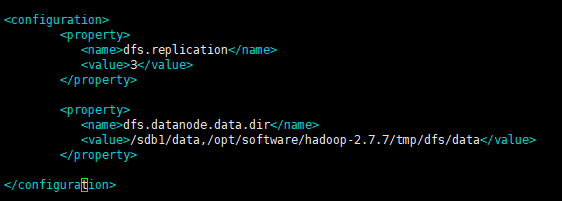
3、修改hdfs-site.xml
cd /opt/software/hadoop-2.7./etc/hadoop vim hdfs-site.xml
启动
start-dfs.sh
访问50070端口

可以看到hdp01的容量由原来的9.99GB扩容到19.98GB
hadoop的扩容的更多相关文章
- Hadoop 动态扩容 增加节点
基础准备 在基础准备部分,主要是设置hadoop运行的系统环境 修改系统hostname(通过hostname和/etc/sysconfig/network进行修改) 修改hosts文件,将集群所有节 ...
- hadoop HDFS扩容
1.纵向扩容(添加硬盘) 1.1 添加硬盘 确定完成添加,运行 lsblk 查看硬盘使用情况 1.2 硬盘分区 fdisk /dev/sdb #对新硬盘sdb进行分区 m 帮助 n 添加一个分区 p ...
- hadoop(1)入门
hadoop入门(一) 一.概述 1.什么是hadoop hadoop不仅是一个用于存储分布式文件系统,还是设计用来在有通用计算设备组成的大型集群上执行的分布式应用的基础框架. hadoop框架最 ...
- 小记---------Hadoop读、写文件步骤,HDFS架构理解
Hadoop 是一个开源框架,可编写和运行分布式应用处理大规模数据 Hadoop框架的核心是HDFS 和 MapReduce HDFS是分布式文件系统(存储) MapReduce是分布式数据处理模型和 ...
- 容器服务如何在企业客户落地?Rancher 解决之道分享
Docker 的优势和趋势我想不必再赘述,那么对于非互联网公司的传统企业客户,以及我们大量的围绕企业客户做集成.交付解决方案的服务提供商,需要考虑的一个问题就是怎么样把容器技术以高质量.低成本.易维护 ...
- Hadoop之HDFS扩容方法
HDFS就是用来存取数据的,那么当数据太多的时候存不下,我们必需扩充硬盘容量,或者换个更大的硬盘. 由于它是分布式文件系统,有两种扩充HDFS集群容量的方法:横向扩容和纵向扩容 横向扩容 横向扩容就是 ...
- 【hbase0.96】基于hadoop搭建hbase的心得
hbase是基于hadoop的hdfs框架做的分布式表格存储系统,所谓表格系统就是在k/v系统的基础上,对value部分支持column family和column,并支持多版本读写. hbase的工 ...
- hadoop 性能调优与运维
hadoop 性能调优与运维 . 硬件选择 . 操作系统调优与jvm调优 . hadoop运维 硬件选择 1) hadoop运行环境 2) 原则一: 主节点可靠性要好于从节点 原则二:多路多核,高频 ...
- Hadoop学习笔记【Hadoop家族成员概述】
Hadoop家族成员概述 一.Hadoop简介 1.1 什么是Hadoop? Hadoop是一个分布式系统基础架构,由Apache基金会所开发,目前Yahoo!是其最重要的贡献者. Hadoop实现了 ...
随机推荐
- Jenkins显示语言切换为中文(最终解决办法)
网上大部分搜索结果都指向同一种方法就是下载Locale插件,但该方法已失效. 新的解决办法: 下载完成之后重启Jenkins生效,会汉化大部分内容,部分设置不会汉化. 注:重启后不生效请检查 1.已安 ...
- Python:字典类型
概念 无序的,可变的,键值对集合 定义 方式1 {key1: value1, key2: value2, ......} 方式2 fromkeys(S, v=None) 静态方法:类和对象都可以调用 ...
- 吴裕雄--天生自然Numpy库学习笔记:NumPy 位运算
bitwise_and() 函数对数组中整数的二进制形式执行位与运算. import numpy as np print ('13 和 17 的二进制形式:') a,b = 13,17 print ( ...
- js指定范围指定个数的不重复随机数
今天偶然看到的 比如要生成 1-100范围之内的10个不重复随机数,代码就可以这么写 var arr = []; for (var i = 1; i <=100; i++) { arr.push ...
- Mybatis学习day2
Mybatis初探 之前已经用利用mybatis实现链接数据库查询所有用户的信息(用的是在resources下建立和Dao层一样目录的xml实现的).这次再来看一下增删改查等其它的操作. 利用Myba ...
- 将UIImage转换成圆形图片image
建议写成UIImage分类,如下: .h //变成圆形图片 - (UIImage *)circleImage; .m //变成圆形图片 - (UIImage *)circleImage { // NO ...
- ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数 HDFS_NAMENODE_USER=root HDFS_DATANODE_USER=root HDFS_SECONDARY ...
- webdriver-js操作滚动条
webdriver-js操作滚动条 1. webdriver高级应用-js操作滚动条 1.滑动页面的滚动条到页面最下面 2.滑动页面的滚动条到页面的某个元素 3.滑动页面的滚动条向下移动某个 ...
- mysql 连接数据库时时区报错
1.url: jdbc:mysql://192.168.0.101:3306/testdb?serverTimezone=UTC,在连接字符后面添加时区设置 2.使用navicat或者直接使用mysq ...
- kali apt update 错误——下列签名无效: EXPKEYSIG ED444FF07D8D0BF6 Kali Linux Repository
这是因为key过期了 wget -q -O - https://archive.kali.org/archive-key.asc | apt-key add apt update