填坑!线上Presto查询Hudi表异常排查
1. 引入
线上用户反馈使用Presto查询Hudi表出现错误,而将Hudi表的文件单独创建parquet类型表时查询无任何问题,关键报错信息如下
40931f6e-3422-4ffd-a692-6c70f75c9380-0_0-384-2545_20200513165135.parquet, start=0, length=67108864, fileSize=67108864, hosts=[], forceLocalScheduling=false, partitionName=dt=2020-05-08, s3SelectPushdownEnabled=false} (start = 2.3651547291593433E10, wall = 163 ms, cpu = 0 ms, wait = 0 ms, calls = 1): HIVE_BAD_DATA: Not valid Parquet file:
报Hudi表中文件格式不是合法的parquet格式错误。
2. 问题复现
开始根据用户提供的信息,模拟线上Hudi数据集大小、Presto和Hudi版本(0.5.2-incubating)来复现该问题。
进行试验发现当Hudi表单文件大小较小时,使用Presto查询一切正常。
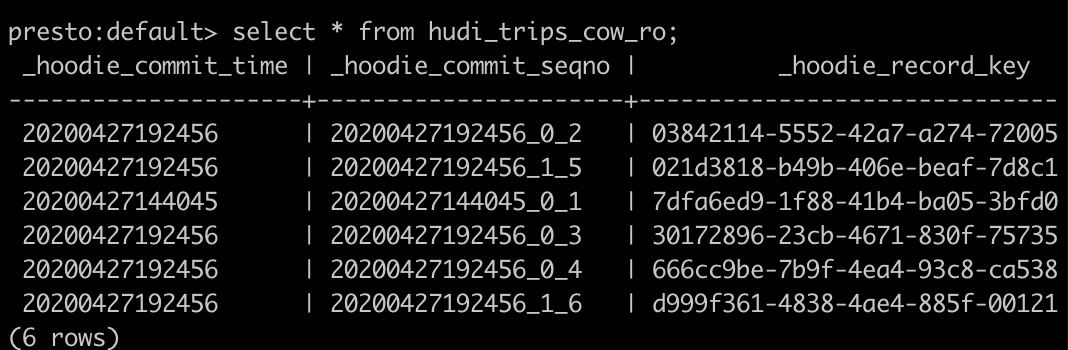
构建Hudi表中单文件大小为100MB以上数据集,使用Presto查询。
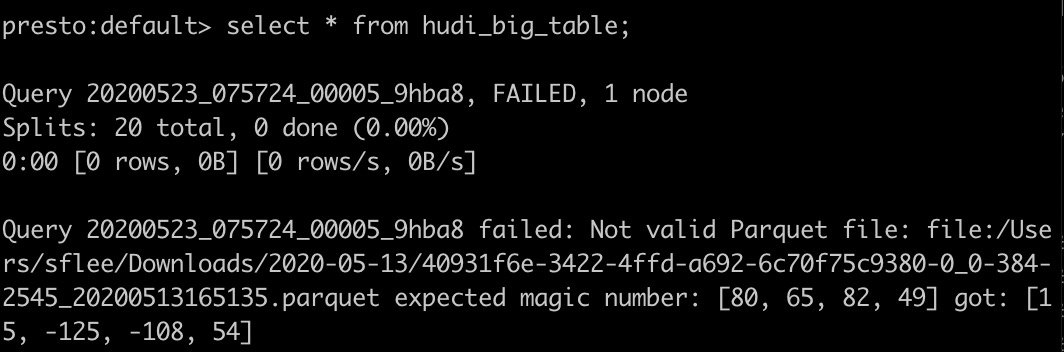
可以看到,当Hudi数据集中文件大小为100MB时复现了Not Valid Parquet file异常,通过Presto的web ui可以看到具体的错误堆栈如下
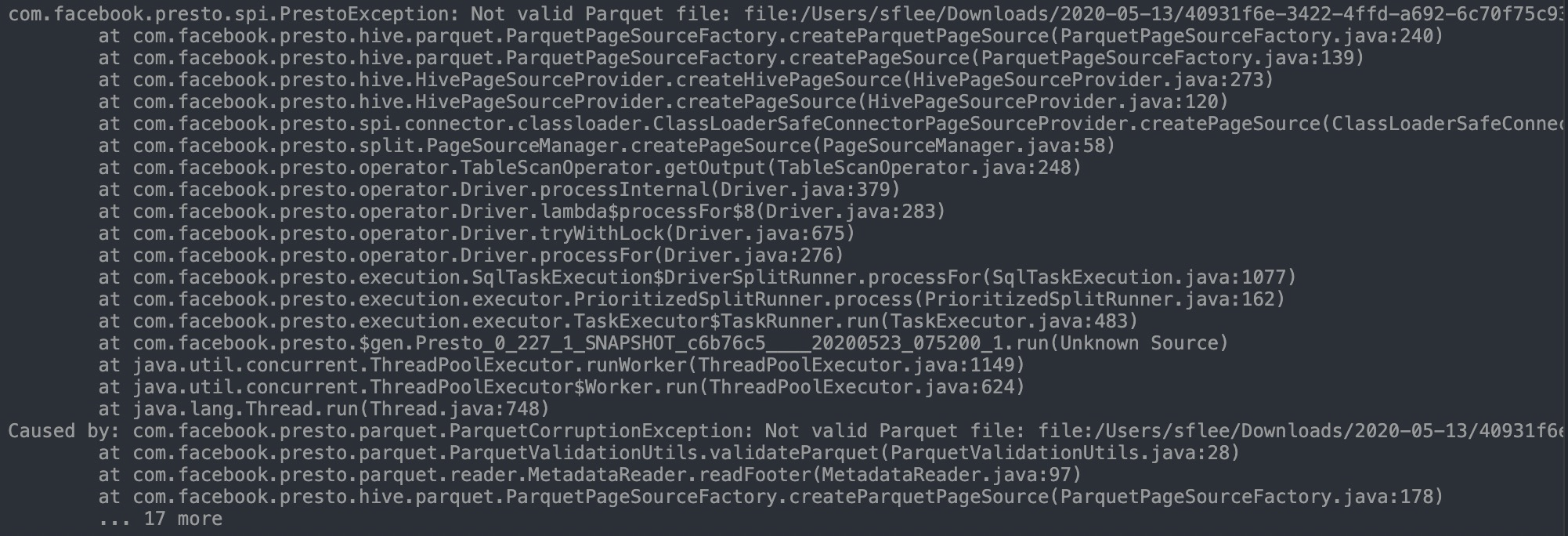
通过错误堆栈可以进一步确认在读取parquet文件时校验失败,开始怀疑parquet文件确实被损坏,但使用parquet-tools工具检查本地parquet文件,发现无问题。
3. 问题排查
经过上述步骤复现了问题,问题能够复现就好排查。但Presto对于合法parquet文件检查为何会报错?带着这个疑问开始在本地debug Presto,首先在Presto服务端和IDEA中进行相应的配置。
3.1 Presto服务端配置
要想能够连接到Presto服务端,需要在PRESTO_HOME根目录下创建etc目录,然后创建jvm.properties文件,内容如下
-server
-Xmx8G
-XX:+UseG1GC
-XX:G1HeapRegionSize=32M
-XX:+UseGCOverheadLimit
-XX:+ExplicitGCInvokesConcurrent
-XX:+HeapDumpOnOutOfMemoryError
-XX:+ExitOnOutOfMemoryError
-agentlib:jdwp=transport=dt_socket,server=y,suspend=n,address=5005
-XX:+TraceClassLoading
-XX:+TraceClassUnloading
-verbose:class
上述配置除了可以连接服务端进行debug外,添加的-XX:+TraceClassLoading、-XX:+TraceClassUnloading两个配置项,还会打印每个类加载和卸载的日志(这个在排查presto类加载器问题时非常有用,建议开启)。
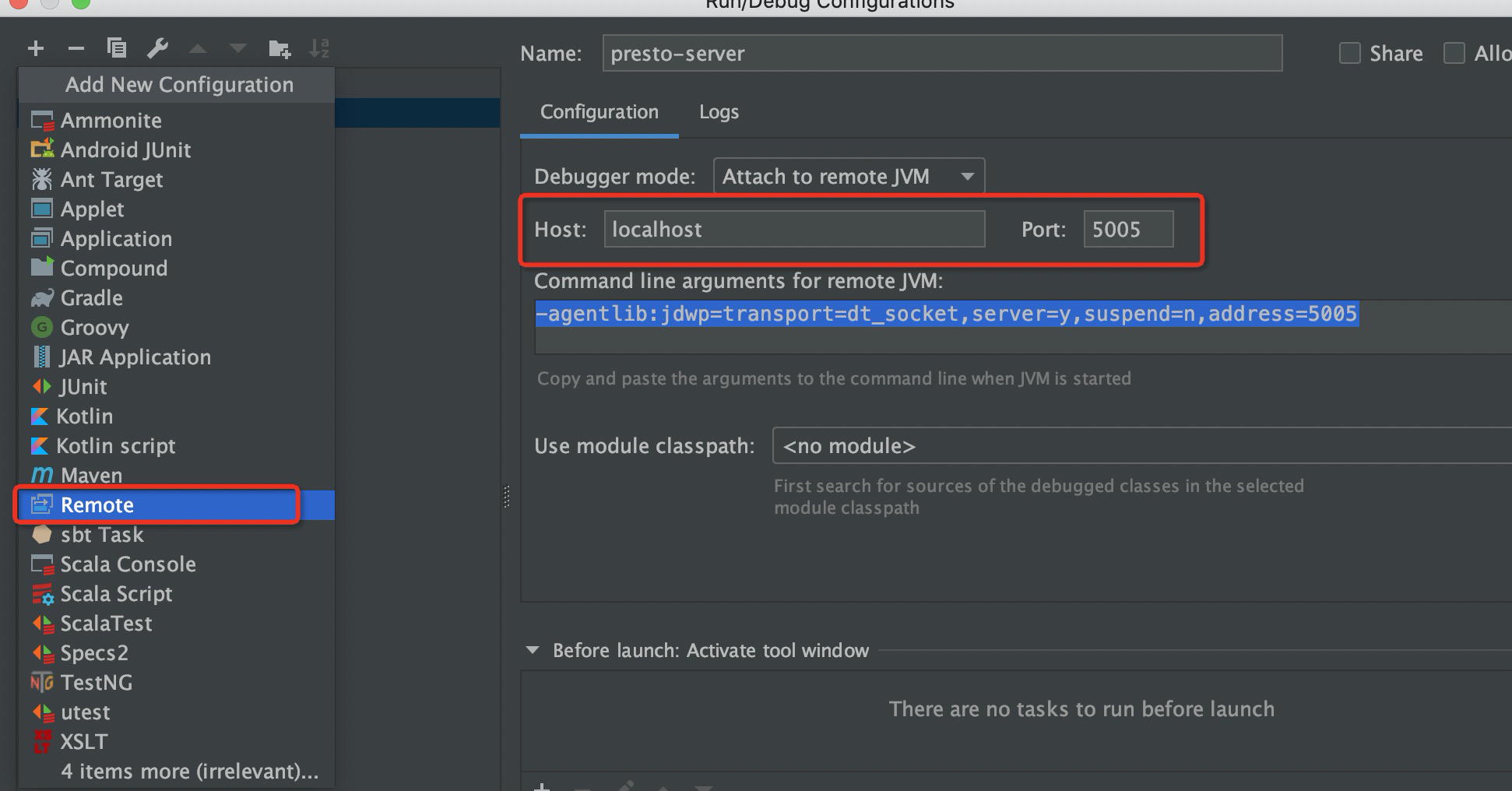
3.2 IDEA配置
配置完Presto服务端后,在IDEA进行如下配置即可。
3.3 单步调试
IDEA中开启了debug后,通过Presto客户端查询时(select * from hudi_big_table),就可以进行单步调试,首先我们在BackgroundHiveSplitLoader类中打了些断点(该类是加载Split的关键类)。
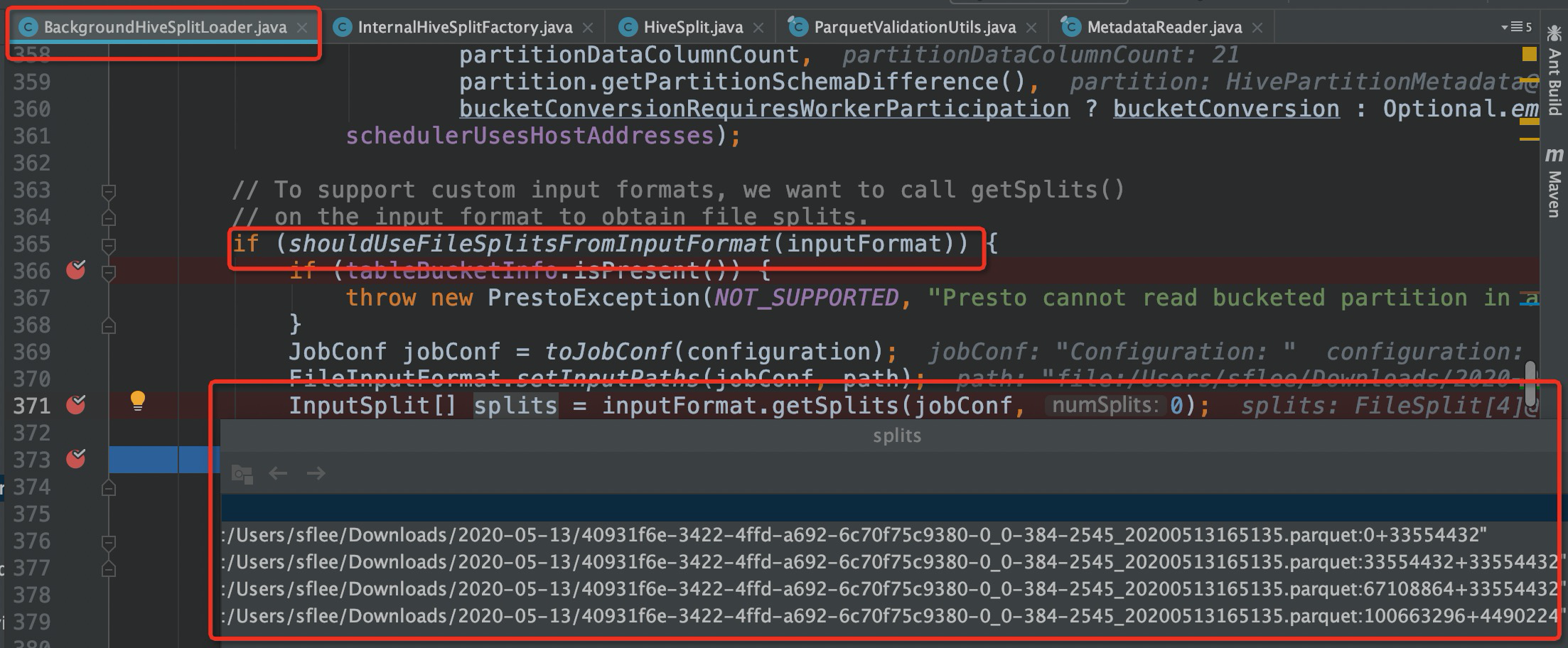
通过shouldUseFileSplitsFromInputFormat方法判断是否直接通过注解(@UseFileSplitsFromInputFormat)获取FileSplit。Hudi与外部系统交互的HoodieParquetInputFormat和HoodieParquetRealtimeInputFormat两个类都使用了该注解。
从上图可以看到100MB的文件被分成了四个InputSplit(按照32MB大小进行切分),后续Presto会根据InputSplit来构造对应的InternalHiveSplit。
进一步在异常堆栈地方打断点如下
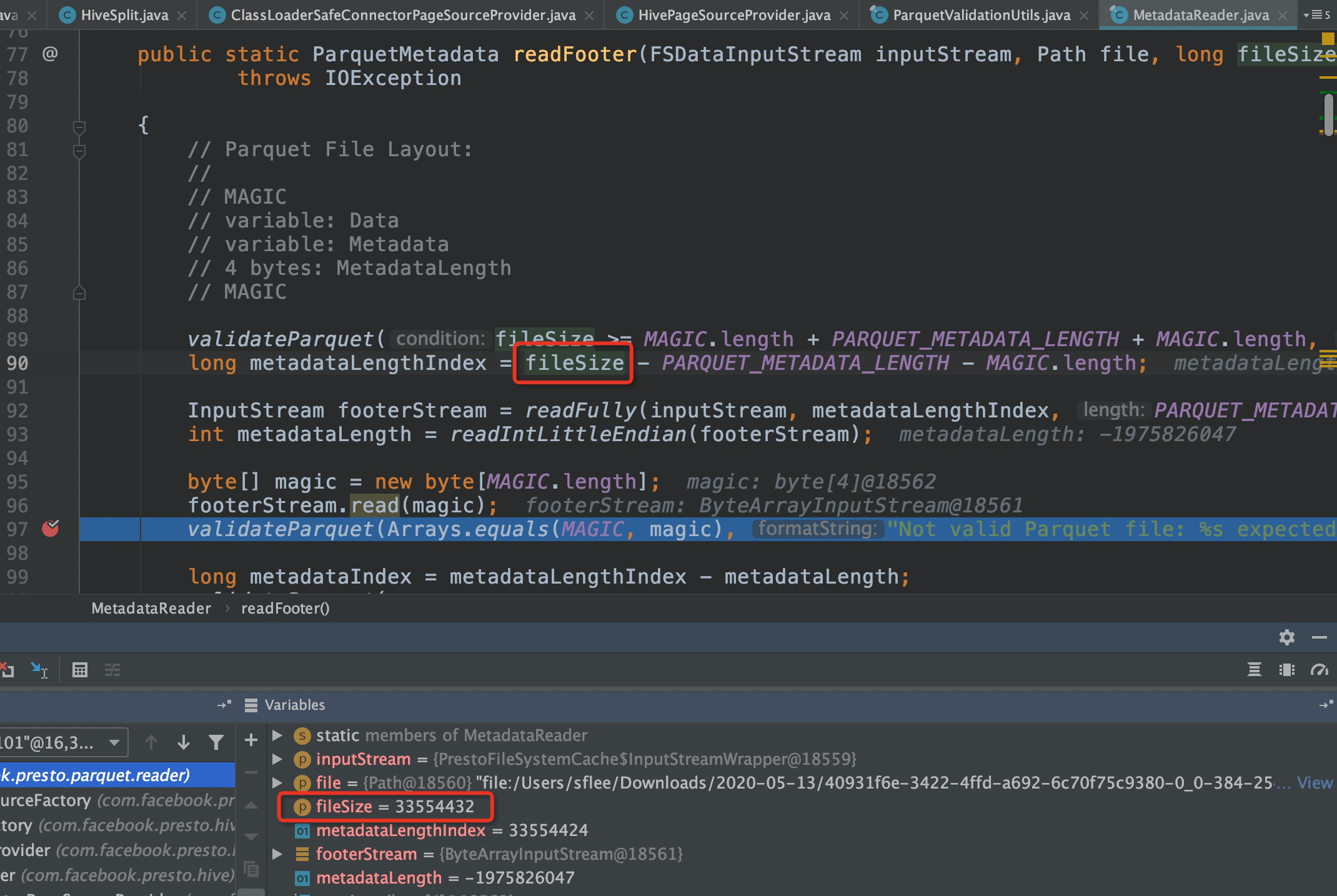
根据上述代码逻辑可知,从文件中读取magic与parquet文件的MAGIC不相等导致抛出了异常。
值得注意的是fileSize的大小为33554432,表示一个InputSplit的大小,而并非文件大小,因此获取metadataLength时并不准确,导致并非读取了parquet文件的magic,而是读取了InputSplit的数据,因此校验时抛出异常。理论上对于不同的InputSplit,该方法传入的fileSize大小应该等于文件的大小,而非InputSplit的大小,那么这个fileSize的大小是在哪个步骤传递错误的呢?带着这个疑问,继续进行debug。
根据前面debug信息得知Presto会通过InputSplit创建InternalHiveSplit,继续debug生成InternalHiveSplit的逻辑
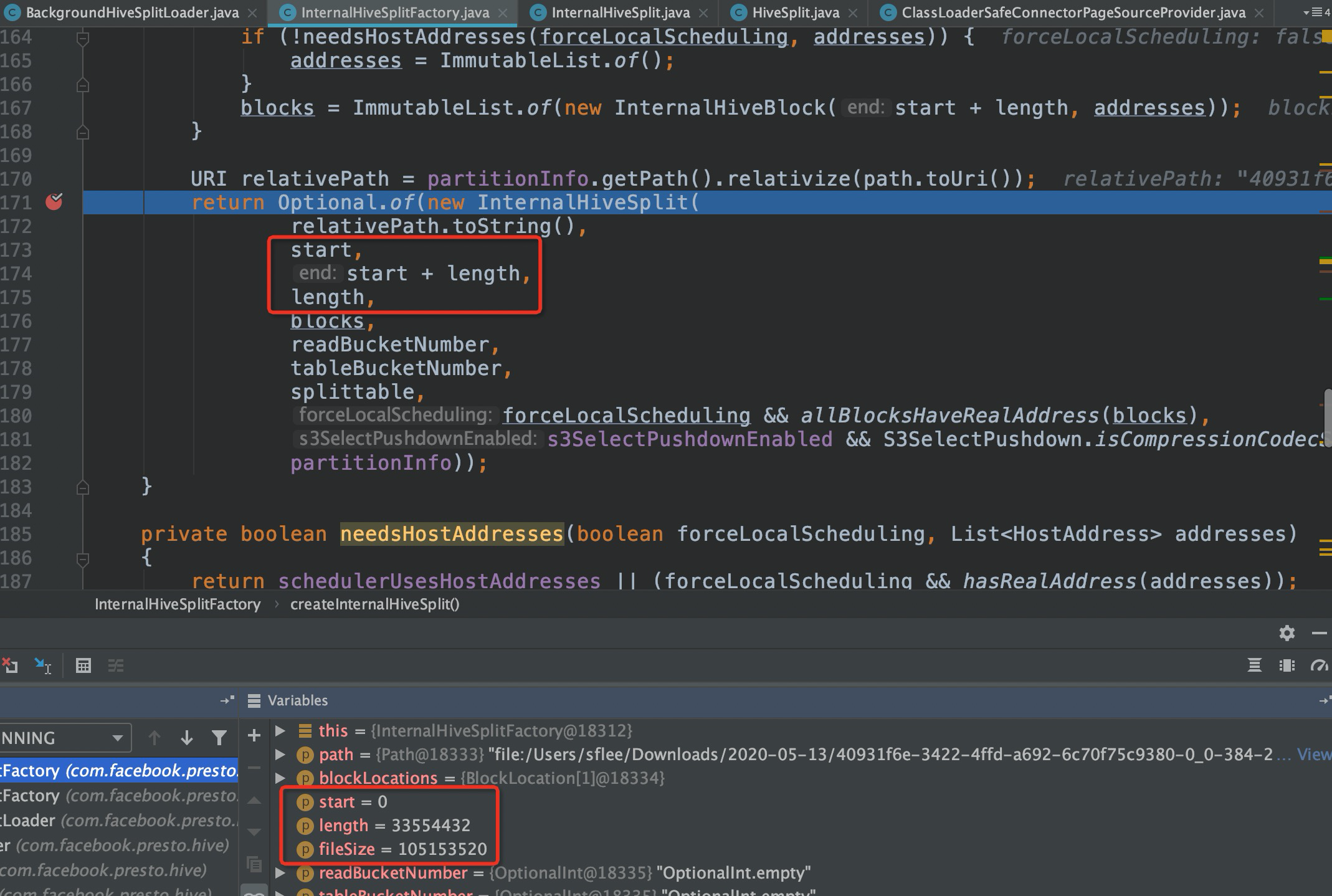
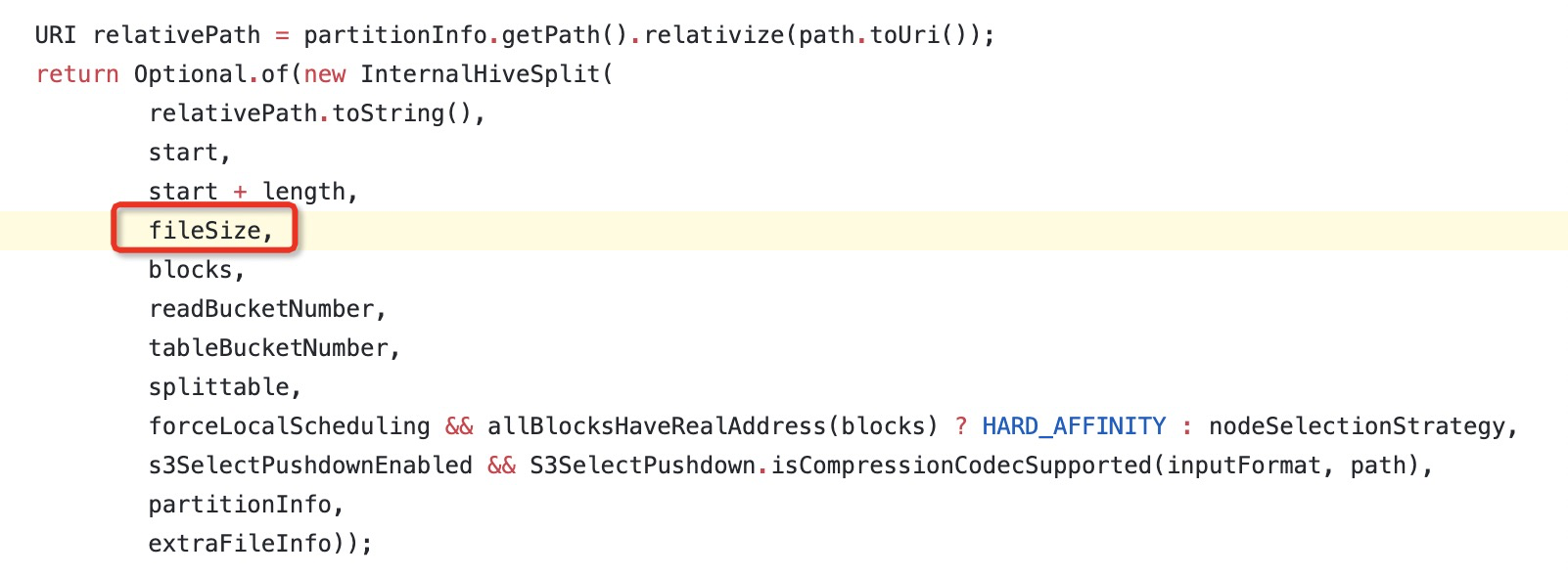
可以看到在上面构造InternalHiveSplit时,传递的参数值为start=0、start + length=33554432,length=33554432,而InternalHiveSplit本身的参数对应为start、end、fileSize,可以看到错误地将length当成fileSize传递了。
既然怀疑这个参数传递错误导致了异常,那么修改参数为fileSize后是否可以修复该问题?于是打包验证观察异常是否还会出现,即对presto-hive模块重新打包,放入$PRESTO_HOME/plugin/presto-hive目录中,重启Presto服务,再次进行验证。

可以看到修改参数后,查询一切正常!!!
另外对Hudi的小文件也进行了回归测试,查询也正常!自此可以发现是由于参数不对的bug导致了异常,鉴于这个bug对Presto社区其他用户也可能产生影响,于是查看Presto的master分支是否修复了该问题,若未修复,可将该patch回推到社区,于是查看了Presto的master分支对应代码,发现已经有开发者修复了!
3.4 影响的版本
由于该缺陷是在2019年5月引入Presto社区,在2020年4月得以修复,期间发布的版本(0.221 ~ 0.235)都会受到影响,如本地测试0.227、0.231版本都有问题。最近社区发布了0.236版本修复了该问题,如果生产环境使用的版本在0.221 ~ 0.235之间,建议升级或者cherry-pick对应的patch。
4. 总结
根据线上用户反馈查询Hudi表问题,由于线上环境不好debug,需根据上线环境在本地模拟复现问题,然后快速debug排查修复问题。当然本篇文章省略了debug的旁路路径,只给出了debug的关键路径。
填坑!线上Presto查询Hudi表异常排查的更多相关文章
- 记一次线上SpringCloud-Feign请求服务超时异常排查
由于近期线上单量暴涨,第三方反馈部分工单业务存在查询处理失败现象,经排查是当前系统通过FeignClient调用下游系统出现部分超时失败(异常代码贴在下方). Caused by: feign.Ret ...
- 解Bug之路-记一次线上请求偶尔变慢的排查
解Bug之路-记一次线上请求偶尔变慢的排查 前言 最近解决了个比较棘手的问题,由于排查过程挺有意思,于是就以此为素材写出了本篇文章. Bug现场 这是一个偶发的性能问题.在每天几百万比交易请求中,平均 ...
- 一次线上tomcat应用请求阻塞的排查经过
今天早上,收到一个报警,有个服务器的http往返时延飙升,同时曝出大量404,很是折腾了一番,特记录下思考和排查经过. 1.这是单纯的时延增大,还是有什么其他情况还未掌握? 因为不知道是只有时延变大而 ...
- python 通过线上API查询ip归属地
API为国外API,频率限制1分钟45个ip 脚本如下 1 #!/usr/bin/env python3 2 #-*-coding:utf-8-*- 3 4 import requests,re,js ...
- Iceberg学习日记(1) 定位两个线上Iceberg查不到文件的问题
前言 Iceberg是我们去年年底(2020)开始调研,目前上线了130多张表.主要用于流量日志清洗,数据报表,推荐特征基础数据.至今为也算是积累了一些使用及定位问题经验. 这篇文章会介绍两个线上Ic ...
- 不停机修改线上 MySQL 主键字段 以及其带来的问题和总结思考
起因: 线上 user 数据库没有自增字段,数据量已经达到百万级.无论是给离线仓库还是数据分析同步数据,没有主键自增 id 都是杀手级的困难.所以在使用 create_time 痛苦了几次之后准备彻底 ...
- [Python3 填坑] 001 格式化符号 & 格式化操作符的辅助指令
目录 1. print( 坑的信息 ) 2. 开始填坑 2.1 Python 格式化符号表 举例说明 (1) %c (2) %s 与 %d (3) %o (4) %x (5) %f (6) %e (7 ...
- 你要偷偷学会排查线上CPU飙高的问题,然后惊艳所有人!
GitHub 20k Star 的Java工程师成神之路,不来了解一下吗! GitHub 20k Star 的Java工程师成神之路,真的不来了解一下吗! GitHub 20k Star 的Java工 ...
- 提升50%!Presto如何提升Hudi表查询性能?
分享一篇关于使用Hudi Clustering来优化Presto查询性能的talk talk主要分为如下几个部分 演讲者背景介绍 Apache Hudi介绍 数据湖演进和用例说明 Hudi Clust ...
随机推荐
- 《Android的设计与实现:卷I》——第1章 1.2.2动态视角的体系结构
1.2.2 动态视角的体系结构静态的体系结构是从横向分层的角度诠释Android是什么.如果静态的体系结构不足以让读者理解Android的运行机制,我们可以看看Google工程师Sans Serif是 ...
- 家用PC机打造VSphere5.1 测试环境:之部署VCenter Server 5.1
家用PC机打造VSphere5.1 测试环境前言:实践出真知,同样学习VMware VSphere 的朋友,也需要不断的测试总结,再测试再总结只有不断的积累才能学好,但是动辄几万的服务器不是所有朋友都 ...
- C语言基础知识总结
知识点的回忆与巩固 一. 条件分支结构 1.if分支语句 2.switch语句 二.循环体部分知识点整理 1.for循环 2.while循环-适合不确定循环次数时使用 三.字符串与数组 数组的操作 1 ...
- POJ 2230 Watchcow 欧拉回路的DFS解法(模板题)
Watchcow Time Limit: 3000MS Memory Limit: 65536K Total Submissions: 9974 Accepted: 4307 Special Judg ...
- UDP广播的客户端和服务器端的代码设计
实验环境 linux 注意: 使用UDP广播,是客户端发送广播消息,服务器端接收消息.实际上是客户端探测局域网中可用服务器的一种手段.客户端发送,服务器端接收,千万不能弄混淆!!! 为了避免混淆,本文 ...
- CentOS启用iptables防火墙
centos 7默认的防火墙使用firewall,系统服务管理方式也变更了,可以通过systemctl命令控制. 可以参考这个链接 但是习惯用iptables,可以按下面的操作改下 1.关闭firew ...
- python-unittest环境下单独运行一个用例的方法
在unittest单元测试的框架下,想要调出如图所示的绿三角 需要有两个步骤: 1.确定在工具栏中时在unittest模式下运行的,如果为普通模式的话可以通过下三角下拉修改运行环境: 2.在代码中im ...
- js 如何保存代码段并执行以及动态加载script
1.模块化开发 通常使用的是 export和import 实现代码的共享和导入 2.特殊情况下需要将代码段作为参数传递 可以使用function 的toString方法将整合函数和里面的代码批量转化为 ...
- 面试被问了三次的http状态码到底有什么
面试被问了三次的http状态码到底有什么 想想很多人面试都会有被问到http的状态码的经历,我也是经历了三面,每次都有提及这个问题.今天就来细致的讨论一下HTTP的状态码,如有不足,欢迎留言交流: H ...
- E. Count The Blocks(找数学规律)
\(\color{Red}{先说一下自己的歪解(找规律)}\) \(n=1是答案是10\) \(n=2时答案是180\) \(n=3时模拟一下,很容易发现答案是2610\ \ 180\ \ 10\) ...