2019-07-28【机器学习】无监督学习之聚类 DBSCAN方法及其应用 (在线大学生上网时间分析)
样本:
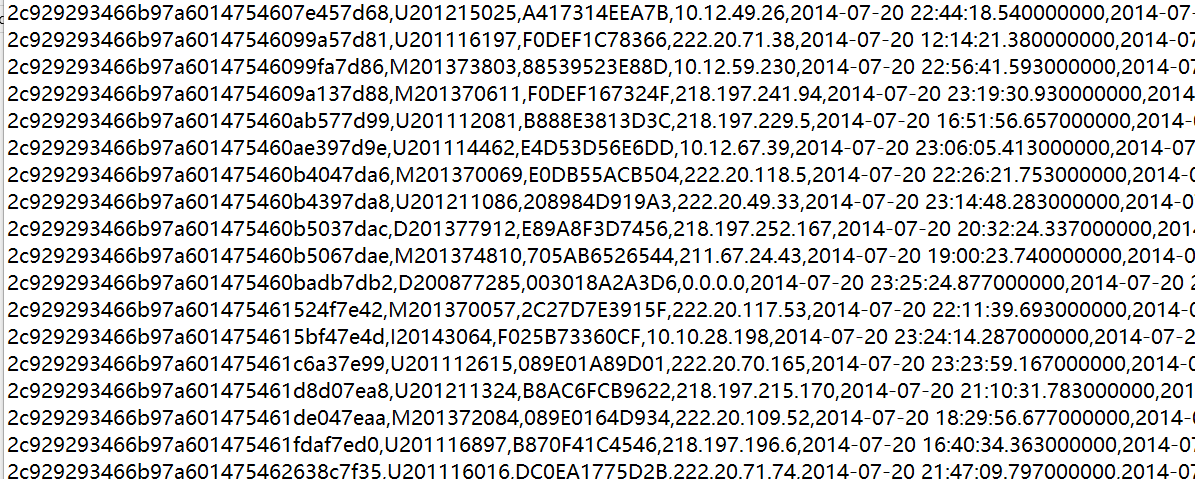
import numpy as np
import sklearn.cluster as skc
from sklearn import metrics
import matplotlib.pyplot as plt mac2id = dict()
onlinetimes = []
f = open('D:\python_source\Machine_study\mooc课程数据\课程数据\聚类\学生月上网时间分布-TestData.txt', encoding='utf-8')
for line in f:
mac = line.split(',')[2] #获取mac地址
onlinetime = int(line.split(',')[6]) #上网时间,单位为秒
starttime = int(line.split(',')[4].split(' ')[1].split(':')[0])#源数据为,2014-07-20 22:44:18.540000000,提取出22
if mac not in mac2id:
mac2id[mac] = len(onlinetimes) #字典,key-mac,??value-上网时长和上网时间/0,1,2,3,4,5,6,7
onlinetimes.append((starttime, onlinetime)) else:
onlinetimes[mac2id[mac]] = [(starttime, onlinetime)] real_X = np.array(onlinetimes).reshape((-1, 2)) #二维数组 X = real_X[:, 0:1] #提取出开始时间点
#S = np.log(1 + real_X[:, 1:]) 对数变换
#print(S)
db = skc.DBSCAN(eps=0.01, min_samples=20).fit(X) #lables为每个数据的簇标签
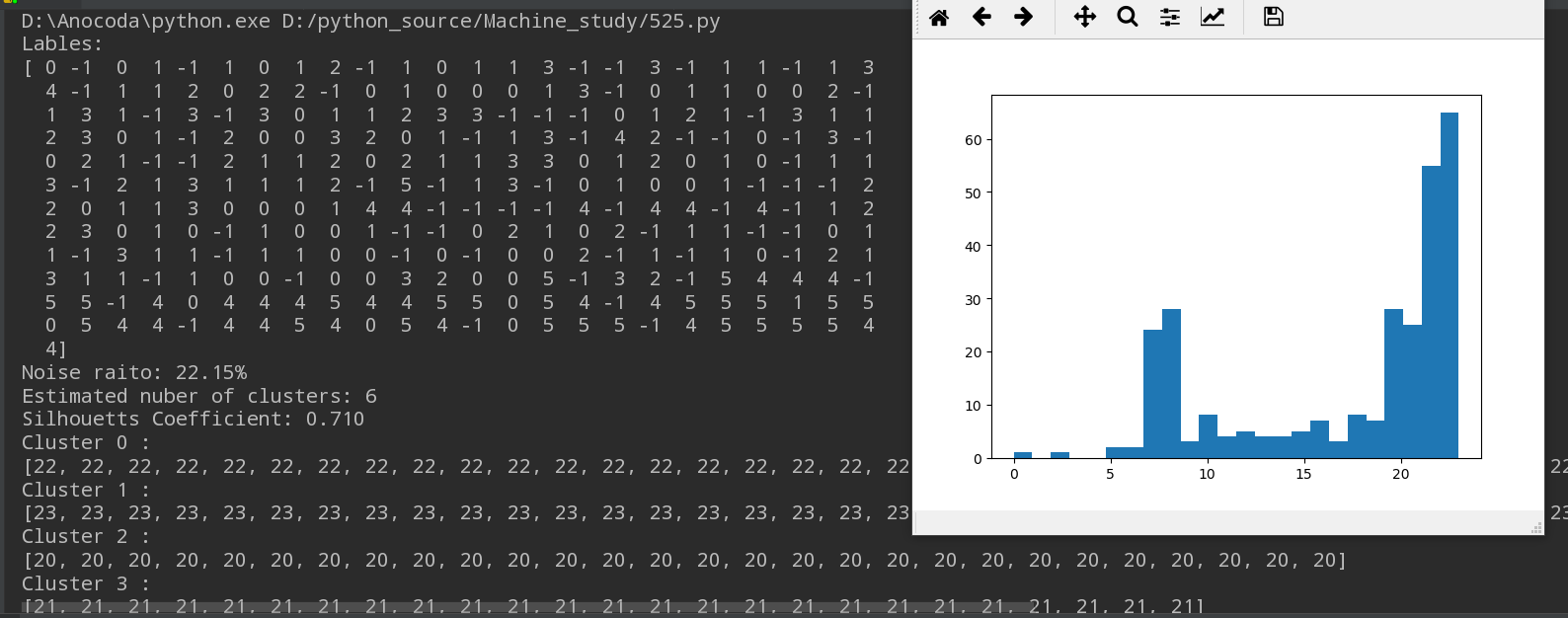
lables = db.labels_ print('Lables:')
print(lables) #分为7类标签
#输出噪点比例
raito = len(lables[lables[:] == -1])/len(lables)
print('Noise raito:', format(raito, '.2%')) n_clusters = len(set(lables)) - (1 if -1 in lables else 0) #噪点为-1,如果有噪点,则7-1==6类 print('Estimated nuber of clusters: %d' %n_clusters)
print("Silhouetts Coefficient: %0.3f" %metrics.silhouette_score(X, lables)) #聚类效果评价指标 for i in range(n_clusters):
print('Cluster', i, ':')
print(list(X[lables == i].flatten())) plt.hist(X, 24)
plt.show()
效果图
2019-07-28【机器学习】无监督学习之聚类 DBSCAN方法及其应用 (在线大学生上网时间分析)的更多相关文章
- 斯坦福机器学习视频笔记 Week8 无监督学习:聚类与数据降维 Clusting & Dimensionality Reduction
监督学习算法需要标记的样本(x,y),但是无监督学习算法只需要input(x). 您将了解聚类 - 用于市场分割,文本摘要,以及许多其他应用程序. Principal Components Analy ...
- <机器学习>无监督学习算法总结
本文仅对常见的无监督学习算法进行了简单讲述,其他的如自动编码器,受限玻尔兹曼机用于无监督学习,神经网络用于无监督学习等未包括.同时虽然整体上分为了聚类和降维两大类,但实际上这两类并非完全正交,很多地方 ...
- 易百教程人工智能python修正-人工智能无监督学习(聚类)
无监督机器学习算法没有任何监督者提供任何指导. 这就是为什么它们与真正的人工智能紧密结合的原因. 在无人监督的学习中,没有正确的答案,也没有监督者指导. 算法需要发现用于学习的有趣数据模式. 什么是聚 ...
- 2019-07-25【机器学习】无监督学习之聚类 K-Means算法实例 (1999年中国居民消费城市分类)
样本 北京,2959.19,730.79,749.41,513.34,467.87,1141.82,478.42,457.64天津,2459.77,495.47,697.33,302.87,284.1 ...
- 2019-07-31【机器学习】无监督学习之聚类 K-Means算法实例 (图像分割)
样本: 代码: import numpy as np import PIL.Image as image from sklearn.cluster import KMeans def loadData ...
- 4.无监督学习--K-means聚类
K-means方法及其应用 1.K-means聚类算法简介: k-means算法以k为参数,把n个对象分成k个簇,使簇内具有较高的相似度,而簇间的相似度较低.主要处理过程包括: 1.随机选择k个点作为 ...
- 【机器学习基础】无监督学习(3)——AutoEncoder
前面主要回顾了无监督学习中的三种降维方法,本节主要学习另一种无监督学习AutoEncoder,这个方法在无监督学习领域应用比较广泛,尤其是其思想比较通用. AutoEncoder 0.AutoEnco ...
- Python 机器学习实战 —— 监督学习(上)
前言 近年来AI人工智能成为社会发展趋势,在IT行业引起一波热潮,有关机器学习.深度学习.神经网络等文章多不胜数.从智能家居.自动驾驶.无人机.智能机器人到人造卫星.安防军备,无论是国家级军事设备还是 ...
- Machine Learning Algorithms Study Notes(4)—无监督学习(unsupervised learning)
1 Unsupervised Learning 1.1 k-means clustering algorithm 1.1.1 算法思想 1.1.2 k-means的不足之处 1 ...
随机推荐
- WTM 3.5发布,VUE来了!
千呼万唤中,WTM的Vue前后端分离版本终于和大家见面了,我曾经跟群里1000多位用户保证过Vue版本会在春天到来,吹过的牛逼总算是圆上了. WTM一如既往地追求最大程度提高生产效率,所以内置的代码生 ...
- 「每日五分钟,玩转JVM」:两种算法
前言 上篇文章,我们了解了GC 的相关概念,这篇文章我们通过两个算法来了解如何去确定堆中的对象实例哪些是我们需要去回收的垃圾对象. 引用计数算法 引用计数法的原理很简单,就是在对象中维护一个计数器,当 ...
- 记一次有趣的thinkphp代码执行
0x00 前言 朋友之前给了个站,拿了很久终于拿下,简单记录一下. 0x01 基础信息 漏洞点:tp 5 method 代码执行,payload如下 POST /?s=captcha _method= ...
- C 2015年真题【保】
1.编写一个完整的程序,使之能完成以下功能:从键盘中输入若干个整数,用链表储存这些输入的数,并要求存储的顺序与输入的顺序相反. 分析:链表建立[头插法] 代码: #include <stdio. ...
- identityserver4源码解析_3_认证接口
目录 identityserver4源码解析_1_项目结构 identityserver4源码解析_2_元数据接口 identityserver4源码解析_3_认证接口 identityserver4 ...
- 题解 P6249 【神帖】
这道题目我一看到就想起了经典题--关路灯 但是时间好像不太好搞啊! 我们可以枚举时间qwq 考虑 \(4\) 维 \(dp\) \(f_{i,j,t,0/1}\) 表示 \(zrl\) 看了第 \(i ...
- 初识ASP.NET CORE
首先创建一个asp.net core web应用程序 第二步 目前官方预置了7种模板项目供我们选择.从中我们可以看出,既有我们熟悉的MVC.WebAPI,又新添加了Razor Page,以及结合比较流 ...
- flume面试题
1 你是如何实现Flume数据传输的监控的使用第三方框架Ganglia实时监控Flume. 2 Flume的Source,Sink,Channel的作用?你们Source是什么类型?1.作用 (1)S ...
- HDU 4325 Flowers 树状数组+离散化
Flowers Problem Description As is known to all, the blooming time and duration varies between differ ...
- ArcGIS Desktop的安装
1.双击ArcGIS Desktop安装目录下的Setup.exe. 2.点击“下一步”. 3.选择“我接受许可协议(A)”,点击“下一步”. 4.选择“完全安装”,点击“下一步”. 5.点击“更改” ...