【转载】 NVIDIA Tesla/Quadro和GeForce GPU比较
原文地址:
https://blog.csdn.net/m0_37462765/article/details/74394932
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
本文链接:https://blog.csdn.net/yiran103/article/details/78532855
————————————————
英伟达gtx不仅可以用来玩游戏,就深度学习任务而言,gtx具备的算力并不亚于tesla专业显卡。并且,游戏卡的价格相比专业卡要便宜不少。那么二者之间的差异是什么呢?
首先,gtx的单卡计算性能和tesla差别不大。虽然英伟达大幅削减了gtx的FP16性能,使其聊胜于无。但gtx的INT8性能并未受到影响。
然而,由于互联特性的缺失,gtx在多卡计算时会有性能损失,集群组网方面更是难堪重任。
-----------------------------------------------------------------------------------------
以下内容节选自Comparison of NVIDIA Tesla/Quadro and NVIDIA GeForce GPUs,完整内容可查看原文。
FP16 16位(半精度)浮点计算
英伟达Pascal架构GPU引入了对FP16操作的支持。虽然所有Pascal以及之后架构的GPU产品都支持FP16,但消费级GeForce GPU的性能要低得多。以下是GeForce和Tesla/Quadro GPU之间的半精度浮点计算性能比较:
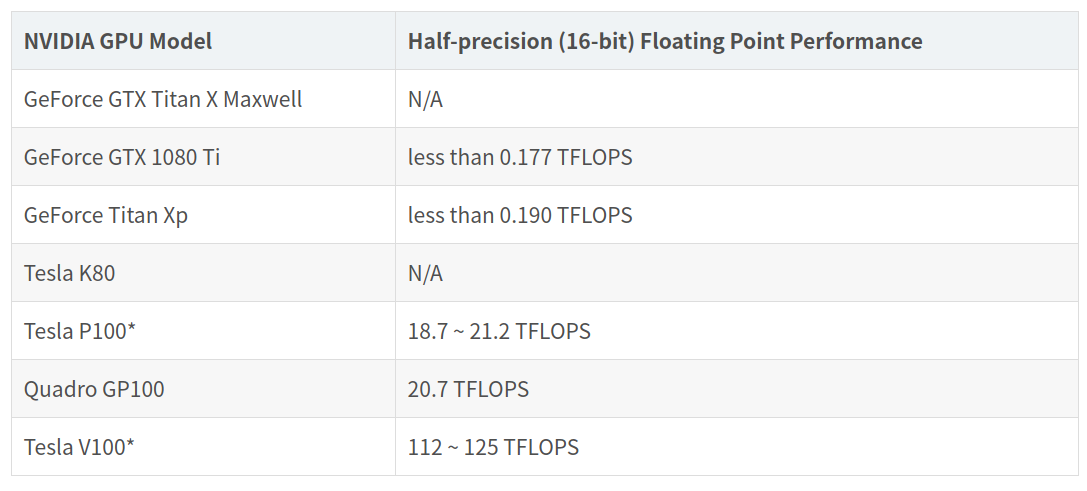
* 具体值取决于PCI-Express或SXM2 SKU
GPU显存性能
计算密集型应用程序需要高性能计算单元,但快速访问数据也非常重要。对于许多HPC应用程序来说,除非内存性能得到改善,否则计算性能的提高将无济于事。出于这个原因,Tesla GPU比GeForce GPU具有更好的实际性能:
这种性能差距的主要原因是,GeForce GPU使用GDDR5内存,而最新的Tesla GPU使用HBM2内存。
GPU显存大小
一般来说,内存越多,系统运行速度越快。一些HPC应用程序需要足够的内存才能运行起来。Tesla GPU提供了两倍于GeForce GPU的内存: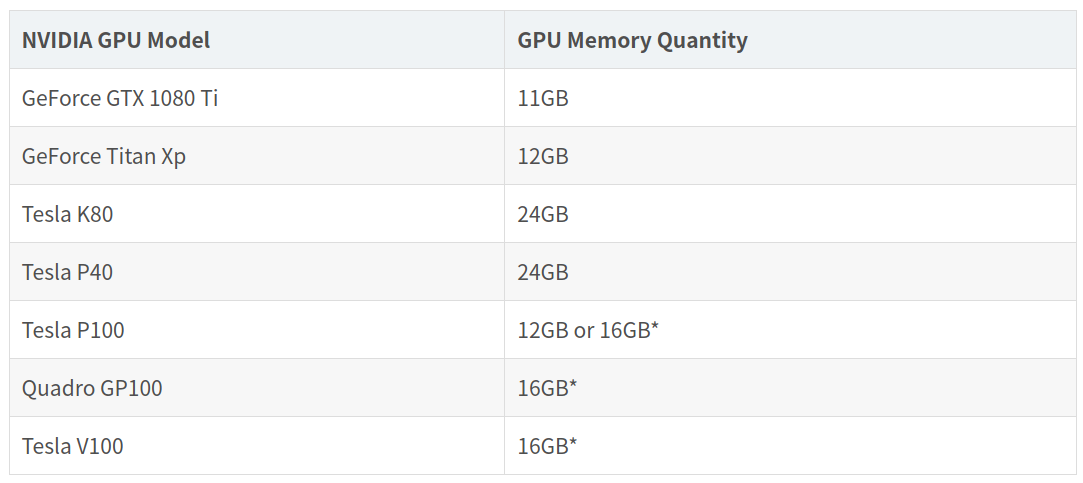
* 请注意,Tesla/Quadro Pascal Unified Memory允许GPU共享彼此的内存来加载更大的数据集。
PCI-E vs NVLink - Device-to-Host和Device-to-Device的吞吐量
程序运行中最大的潜在瓶颈之一是等待数据传输到GPU。当多个GPU并行工作时,会出现更多的瓶颈。加速数据传输可以直接提升应用程序的性能。
GeForce GPU通过PCI-Express连接,理论峰值吞吐量为16GB/s。带有NVLink的NVIDIA Tesla/Quadro GPU可以实现更快的连接。NVIDIA Pascal架构中的NVLink允许每个GPU以高达80GB/s(双向160GB/s)的速度进行通信。NVIDIA Volta中的NVLink 2.0允许每个GPU以150GB/s(300GB/s双向)进行通信。 GPU之间以及支持OpenPOWER平台上的CPU和GPU之间支持NVLink连接。只有Tesla和Quadro系列的GPU支持NVLink。
DMA引擎
GPU的直接内存访问(DMA)引擎允许在系统内存和GPU内存之间快速传输数据。由于这种传输是实际应用程序的一部分,因此其性能对于GPU加速非常重要。慢速传输会导致GPU内核空闲,直至数据到达GPU内存。同样,返回缓慢也会导致CPU等待GPU返回结果。
*GeForce产品具有1个DMA引擎,可以单向传输数据。**如果数据正在上传到GPU,则在上传完成之前无法返回由GPU计算的任何结果。同样,从GPU返回结果将阻止任何新数据上传到GPU。
* 一个GeForce GPU型号,GeForce GTX Titan X,具有双DMA引擎
Tesla GPU产品采用双DMA引擎来缓解这一瓶颈。数据可以同时传入和传出GPU。
GPU Direct RDMA
NVIDIA的GPU-Direct技术可以显着改善GPU之间的数据传输速度。很多功能都属于GPU-Direct的范畴,但是RDMA能力保证了最大的性能提升。
传统上,在集群的GPU之间发送数据需要3个内存拷贝(一次到GPU的系统内存,一次到CPU的系统内存,一次到InfiniBand驱动程序的内存)。GPU Direct RDMA消除系统内存拷贝,允许GPU通过InfiniBand直接将数据发送到远端系统。实际上,对于小的MPI消息,这将导致延迟降低67%,带宽增加430%1.
在CUDA 8.0版本中,NVIDIA推出了GPU Direct RDMA ASYNC,它允许GPU在不与CPU进行任何交互的情况下启动RDMA传输。
GeForce GPU不支持GPU-Direct RDMA。虽然MPI调用会返回成功,但传输将通过标准的内存复制路径执行。GPU Direct-to-Peer(P2P)是唯一支持GeForce显卡的GPU-Direct。这允许在单个计算机内进行快速传输,但对于跨多个服务器/计算节点运行的应用程序没有任何作用。
Tesla GPU完全支持GPU Direct RDMA和各种其他GPU Direct功能。它们是这些能力的主要目标,因此在该领域测试和使用最多。
Hyper-Q
用于MPI和CUDA流的Hyper-Q代理允许多个CPU线程或进程在单个GPU上启动工作。这对于使用MPI编写的现有并行应用程序尤为重要,因为这些代码旨在利用多个CPU核心。允许GPU接受来自系统上运行的每个MPI线程的工作,可以显着提升性能。它还可以减少将GPU加速添加到现有应用程序所需重构源代码的数量。
但是,GeForce GPU上支持的Hyper-Q的唯一形式是针对CUDA Streams的Hyper-Q。这使GeForce能够有效地接受和运行来自不同CPU核心的并行计算,但在多台计算机上运行的应用程序将无法在GPU上高效地开展工作。
GPU健康监控和管理功能
许多健康监控和GPU管理功能(这对维护多GPU系统至关重要)只在专业的Tesla GPU上得到支持。GeForce GPU不支持的健康功能包括:
- NVML/nvidia-smi 用于监视和管理每个GPU的状态和功能。这使得Ganglia等许多第三方应用程序和工具能够支持GPU。Perl和Python绑定也是可用的。
- OOB (通过IPMI进行带外监控),系统可监控GPU运行状况,调节风扇速度以适当冷却设备,并在出现问题时发出警报
- InfoROM (持久性配置和状态数据)为系统提供有关每个GPU的附加数据
- NVHealthmon 实用程序为集群管理员提供了一个随时可用的GPU运行状况工具
- TCC 允许将GPU专门设置为仅显示模式或仅计算模式
- ECC (内存错误检测和纠正)
集群工具依赖NVIDIA NVML所提供的功能。大约60%的功能在GeForce上不可用——这张表更详细地比较了Tesla和GeForce GPU中支持的NVML功能:
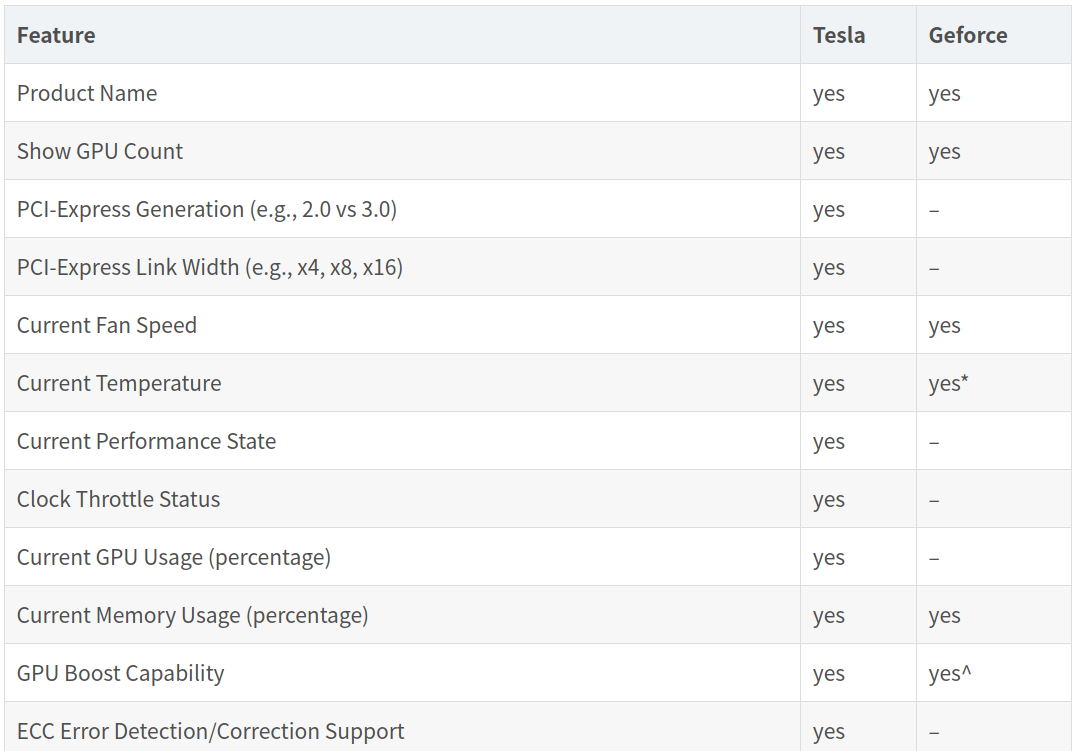
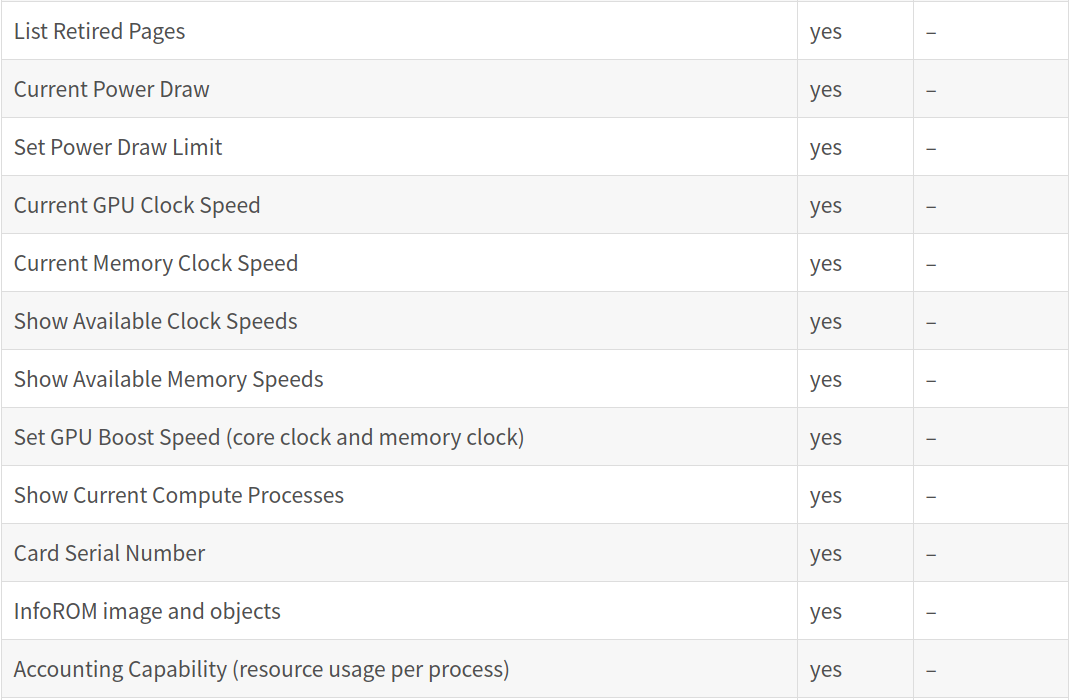

* 系统平台没有温度读数,这意味着风扇速度无法调整。
^ 在双精度计算中,GPU Boost被禁用。此外,在某些情况下,GeForce时钟速率将自动降低。
错误检测和纠正
Titan X GPU不包括纠错或错误检测功能。如果发生错误,GPU和系统都不能提醒用户。用户可以检测错误(无论是导致应用程序崩溃、显然数据不正确还是数据错误)。这样的问题并不罕见——我们的技术人员经常在消费类游戏GPU上遇到内存错误。
英伟达Tesla GPU能够纠正单比特错误,并检测并警示双位错误。在最新的Tesla P100和Quadro GP100 GPU上,最主要的HBM2内存、寄存器文件、共享内存、L1缓存和L2缓存中都包含ECC支持。
GPU Boost
对于Geforce,显卡将根据GPU的温度自动确定时钟速率和电压。温度是合适的自变量,因为发热影响风扇速度。
而对于Tesla,GPU boost等级可由系统管理员或计算用户指定——将时钟速率设置为特定的频率。除非达到功耗阈值(TDP),可以静态地维持期望的时钟速率,而不是在各级别间浮动。这是一个重要的考虑因素,因为HPC环境中的加速器通常需要彼此同步。Tesla GPU boost的确定性允许系统管理员确定最佳时钟速率并将其锁定在所有GPU中。
对于需要额外性能的应用,最新的Tesla GPU包括同步增强组内的自动增强。启用Auto Boost功能后,每个GPU组在有余量时都会提高时钟速率。该组将保持时钟同步,以确保整个组的性能匹配。
能效
GeForce GPU旨在用于消费类游戏,并且通常没有节能考量。相比之下,Tesla GPU则是专为大规模部署而设计的,其能效非常重要。这使得Tesla GPU更适合大量部署。
操作系统支持
GeForce驱动程序不适用于Windows Server操作系统;不过,Linux驱动程序支持所有NVIDIA GPU。
保修
NVIDIA对GeForce GPU产品的保修条款明确规定,GeForce产品不适用于安装在服务器上。在服务器系统中运行GeForce GPU将使保修失效。
【转载】 NVIDIA Tesla/Quadro和GeForce GPU比较的更多相关文章
- 基于Ubuntu14.04系统的nvidia tesla K40驱动和cuda 7.5安装笔记
基于Ubuntu14.04系统的nvidia tesla K40驱动和cuda 7.5安装笔记 飞翔的蜘蛛人 注1:本人新手,文章中不准确的地方,欢迎批评指正 注2:知识储备应达到Linux入门级水平 ...
- ubuntu14.04下的NVIDIA Tesla K80显卡驱动的安装教程
搞深度学习如何能够不与浑身是“核”的显卡打交道呢? 人工智能的兴起除了数据量的大量提升,算法的不断改进,计算能力的逐步提高,还离不开软件基础设施的逐步完善.当下的主流的深度学习工具软件无论是Caffe ...
- 联想SR658安装显卡驱动【NVIDIA Tesla V100】
1. 安装基础依赖环境 yum -y install gcc kernel-devel kernel-headers 2.查看内核和源码版本是否一致 查看内核版本: ls /boot | grep v ...
- NVIDIA 显卡与 CUDA 在深度学习中的应用
CUDA(Compute Unified Device Architecture),是显卡厂商 NVIDIA 推出的运算平台. 0. 配置 显卡驱动的下载地址:Drivers - Download N ...
- 在Kaggle免费使用GPU训练自己的神经网络
Kaggle上有免费供大家使用的GPU计算资源,本文教你如何使用它来训练自己的神经网络. Kaggle是什么 Kaggle是一个数据建模和数据分析竞赛平台.企业和研究者可在其上发布数据,统计学者和数据 ...
- CUDA 8混合精度编程
CUDA 8混合精度编程 Mixed-Precision Programming with CUDA 8 论文地址:https://devblogs.nvidia.com/mixed-precisio ...
- 人工智能范畴及深度学习主流框架,IBM Watson认知计算领域IntelligentBehavior介绍
人工智能范畴及深度学习主流框架,IBM Watson认知计算领域IntelligentBehavior介绍 工业机器人,家用机器人这些只是人工智能的一个细分应用而已.图像识别,语音识别,推荐算法,NL ...
- 人工智能范畴及深度学习主流框架,谷歌 TensorFlow,IBM Watson认知计算领域IntelligentBehavior介绍
人工智能范畴及深度学习主流框架,谷歌 TensorFlow,IBM Watson认知计算领域IntelligentBehavior介绍 ================================ ...
- nvidia Compute Capability(GPU)
GPU Compute Capability NVIDIA TITAN X 6.1 GeForce GTX 1080 6.1 GeForce GTX 1070 6.1 GeForce GTX 1060 ...
随机推荐
- Bug搬运工-CSCux99539:Intermittent error message "Power supply 2 failed or shutdown"
Description Symptom:Following error messages will be seen intermittently.%PFMA-2-PS_FAIL: Power supp ...
- 2019冬季PAT甲级第一题
#define HAVE_STRUCT_TIMESPEC #include<bits/stdc++.h> using namespace std; ][]; ][]; ]; string ...
- 老大难的 Java ClassLoader,到了该彻底理解它的时候了
ClassLoader 是 Java 届最为神秘的技术之一,无数人被它伤透了脑筋,摸不清门道究竟在哪里.网上的文章也是一篇又一篇,经过本人的亲自鉴定,绝大部分内容都是在误导别人.本文我带读者彻底吃透 ...
- angular 页面中引入静态 PDF 文件
在web开发时我们有时会需要在线预览PDF内容,在线嵌入pdf文件 常用的几种PDF预览代码片段如下: 方法一: <object type="application/pdf" ...
- Python 之路
Python之路[第一篇]:Python简介和入门 Python之路[第二篇]:Python基础(一) Python之路[第三篇]:Python基础(二) Python之路[第四篇]:模块 Pytho ...
- blog主题——樱花
贮存一下,blog代码 QAQ 页脚html <!--live2d--> <script src="https://blog-static.cnblogs.com/file ...
- Dart语言学习(二) Dart的常量和变量
1.使用var声明变量,可赋予不同类型的值 Dart是一个强大的脚本类语言,可以不预先定义变量类型 ,自动会类型推导 Dart中定义变量可以通过var关键字可以通过类型来申明变量 var str='t ...
- linux内存查看、清理、释放命令
echo 1 > /proc/sys/vm/drop_caches 清理前 # free -h total used free shared buffers cached Mem: 19G 19 ...
- restful api的那些事
1.restful api 简介 传统api: 2.http状态码 3.数据结构格式 4.不可预知的api错误解决方案: 如使用框架,可写个类,重构错误提示.如TP框架可继承Handle并重载rend ...
- acm数论之旅--组合数(转载)
随笔 - 20 文章 - 0 评论 - 73 ACM数论之旅8---组合数(组合大法好(,,• ₃ •,,) ) 补充:全错排公式:https://blog.csdn.net/Carey_Lu/ ...