spark streaming 接收kafka消息之一 -- 两种接收方式
源码分析的spark版本是1.6。
首先,先看一下 org.apache.spark.streaming.dstream.InputDStream 的 类说明:
This is the abstract base class for all input streams. This class provides methods start() and stop()
which is called by Spark Streaming system to start and stop receiving data. Input streams that can
generate RDDs from new data by running a service/thread only on the driver node (that is, without
running a receiver on worker nodes), can be implemented by directly inheriting this InputDStream.
For example, FileInputDStream, a subclass of InputDStream, monitors a HDFS directory from the driver
for new files and generates RDDs with the new files. For implementing input streams that requires
running a receiver on the worker nodes, use org.apache.spark.streaming.dstream.ReceiverInputDStream
as the parent class.
翻译如下:
所有输入stream 的抽象父类,这个类提供了 start 和 stop 方法, 这两个方法被spark streaming系统来开始接收或结束接收数据。
两种接收数据的两种方式:
在driver 端接收数据;
1. 输入流通过在driver 节点上运行一个线程或服务,从新数据产生 RDD,继承自 InputDStream 的子类
2. 输入流通过运行在 worker 节点上的一个receiver ,从新数据产生RDD , 继承自 org.apache.spark.streaming.dstream.ReceiverInputDStream
也就是说 spark 1.6 版本的输入流的抽象父类就是 org.apache.spark.streaming.dstream.InputDStream,其子类如下图所示:
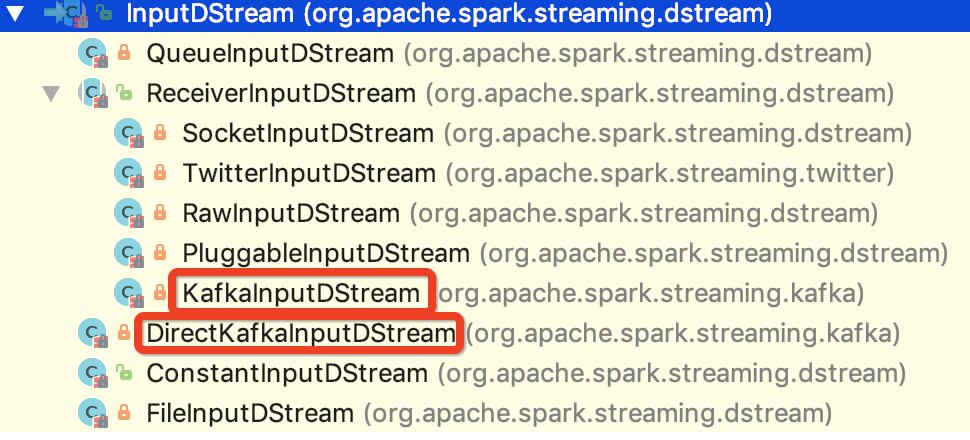
与kafka 对接的两个类已经 在上图中标明。
现在对两种方式做一下简单的比较:
相同点:
1.内部都是通过SimpleConsumer 来获取消息,在获取消息之前,在获取消息之前,from offset 和 until offset 都已经确定。
2.都需要在构造 FetchRequest之前,确定leader, offset 等信息。
3. 其内部都有一个速率评估器,起到平衡速率的作用
不同点:
1. offset 的管理不同。
DirectKafkaInputStream 可以通过外部介质来管理 offset, 比如 redis, mysql等数据库,也可以是hbase等。
KafkaInputStream 则需要使用zookeeper 来管理consumer offset数据, 其内部需要监控zookeeper 的状态。
2. receiver运行的节点不同。
DirectKafkaInputStream 对应的 receiver 是运行在 driver 节点上的。
KafkaInputStream 对应的 receiver 是运行在非driver 的executor 上的。
3. 内部对应的RDD不一样。
DirectKafkaInputStream 对应的是 KafkaRDD,内部的迭代器是KafkaRDDIterator
KafkaInputStream 对应的是 WriteAheadLogBackedBlockRDD 或者是 BlockRDD,内部的迭代器 是自定义的 NextIterator
4. 保证Exactly-once 语义的机制不一样。
DirectKafkaInputStream 是根据 offset 和 KafkaRDD 的机制来保证 exactly-once 语义的
KafkaInputStream 是根据zookeeper的 offset 和WAL 机制来保证 exactly-once 语义的,接收到消息之后,会先保存到checkpoint 的 WAL 中
spark streaming 接收kafka消息之一 -- 两种接收方式的更多相关文章
- SparkStreaming与Kafka,SparkStreaming接收Kafka数据的两种方式
SparkStreaming接收Kafka数据的两种方式 SparkStreaming接收数据原理 一.SparkStreaming + Kafka Receiver模式 二.SparkStreami ...
- Spark Streaming中空batches处理的两种方法(转)
原文链接:Spark Streaming中空batches处理的两种方法 Spark Streaming是近实时(near real time)的小批处理系统.对给定的时间间隔(interval),S ...
- spark streaming 接收kafka消息之五 -- spark streaming 和 kafka 的对接总结
Spark streaming 和kafka 处理确保消息不丢失的总结 接入kafka 我们前面的1到4 都在说 spark streaming 接入 kafka 消息的事情.讲了两种接入方式,以及s ...
- Spark Streaming与Kafka集成
Spark Streaming与Kafka集成 1.介绍 kafka是一个发布订阅消息系统,具有分布式.分区化.多副本提交日志特点.kafka项目在0.8和0.10之间引入了一种新型消费者API,注意 ...
- Spark Streaming 交互 Kafka的两种方式
一.Spark Streaming连Kafka(重点) 方式一:Receiver方式连:走磁盘 使用High Level API(高阶API)实现Offset自动管理,灵活性差,处理数据时,如果某一时 ...
- spark streaming集成kafka接收数据的方式
spark streaming是以batch的方式来消费,strom是准实时一条一条的消费.当然也可以使用trident和tick的方式来实现batch消费(官方叫做mini batch).效率嘛,有 ...
- Spark Streaming和Kafka整合保证数据零丢失
当我们正确地部署好Spark Streaming,我们就可以使用Spark Streaming提供的零数据丢失机制.为了体验这个关键的特性,你需要满足以下几个先决条件: 1.输入的数据来自可靠的数据源 ...
- spark streaming 整合 kafka(一)
转载:https://www.iteblog.com/archives/1322.html Apache Kafka是一个分布式的消息发布-订阅系统.可以说,任何实时大数据处理工具缺少与Kafka整合 ...
- Spark Streaming使用Kafka保证数据零丢失
来自: https://community.qingcloud.com/topic/344/spark-streaming使用kafka保证数据零丢失 spark streaming从1.2开始提供了 ...
随机推荐
- SSH原理和使用
ssh 是什么 在 linux 上工作,ssh 是必须要了解的技术方法.它可以建立起多台主机之间的安全的加密传输,以进行远程的访问.操控.传输数据. SSH 為 Secure Shell 的縮寫.為建 ...
- Python 内置函数 —— format
科学计数法: >> format(2**20, '.2e') '1.05e+06' 小数 ⇒ 百分数 >> format(.1234, '.1%') 12.3%
- 简明Python3教程 11.数据结构
简介 数据结构基本上就是 – 可以将一些数据结合到一起的结构,换言之用于存储一组相关的数据. python拥有4种内建数据结构 – 列表,元组(tuple),字典和集合. 我们将看到如何它们,它们又是 ...
- Akka边学边写(1)-- Hello, World!
Akka Akka是什么呢?直接引用Akka站点上面的描写叙述吧: Akka is a toolkit and runtime for building highly concurrent, dist ...
- JQuery在一个简单的表单验证的例子
html代码例如以下: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http:/ ...
- Atitit.软件button和仪表板(13)--全文索引操作--db数据库子系统mssql2008
Atitit.软件button和仪表板(13)--全文索引操作--db数据库子系统mssql2008 全文索引操作 4.全文索引和like语句比較 1 5.倒排索引 inverted index 1 ...
- poj 1125 Stockbroker Grapevine(多源最短)
id=1125">链接:poj 1125 题意:输入n个经纪人,以及他们之间传播谣言所需的时间, 问从哪个人開始传播使得全部人知道所需时间最少.这个最少时间是多少 分析:由于谣言传播是 ...
- Ubuntu+NDK编译openssl(为了Android上使用libcurl且支持HTTPS协议)
为了Android上使用libcurl且支持HTTPS协议,需要依赖openssl,因此先来了解一下如何编译OpenSSL1.编译ARM下的共享库(默认的)我使用的是guardianproject的o ...
- 存储过程和输出分辨率表菜单JSON格式字符串
表的结构,如以下: SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO SET ANSI_PADDING ON GO CREATE TABLE [dbo] ...
- NSURLSession 网络库 - 原生系统送给我们的礼物
大家在进行iOS开发的时候一定会用到网络操作.但由于早期原生的 NSURLConnection 操作起来有很多不便,使得大家更愿意使用第三方库的解决方案,比如鼎鼎大名的 AFNetworking.正是 ...