利用AdaBoost方法构建多个弱分类器进行分类
1.AdaBoost 思想
补充:这里的若分类器之间有比较强的依赖关系;对于若依赖关系的分类器一般使用Bagging的方法
弱分类器是指分类效果要比随机猜测效果略好的分类器,我们可以通过构建多个弱分类器来进行最终抉择(俗话说,三个臭皮匠顶个诸葛亮大概就这意思)。首先我们给每个样例初始化一个权重,构成向量D,然后再更新D,更新规则如下:
当一个样例被分类器正确分类时,我们就减小它的权重
否则,增大它的权重
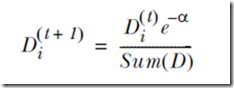
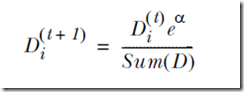
对于每个弱分类器,我们根据它对样例分类错误率来设置它的权重alpha,分类错误率越高,相应的alpha就会越小,如下所示

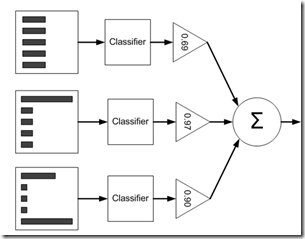
最终我们训练出多个弱分类器,通过加权分类结果,输出最终分类结果,如下图所示
2.实验过程
# -*- coding: utf-8 -*-
"""
Created on Wed Mar 29 16:57:37 2017 @author: MyHome
"""
import numpy as np '''返回分类结果向量'''
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
retArray = np.ones((np.shape(dataMatrix)[0],1))
if threshIneq == "lt":
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0 return retArray '''构造一个最佳决策树,返回决策树字典'''
def buildStump(dataArr,classLabels,D):
dataMatrix = np.mat(dataArr)
labelMat = np.mat(classLabels).T
m,n = dataMatrix.shape
numSteps = 10.0
bestStump = {}
bestClassEst = np.mat(np.zeros((m,1)))
minError = np.inf for i in xrange(n):
rangeMin = dataMatrix[:,i].min()
rangeMax = dataMatrix[:,i].max()
stepSize = (rangeMax - rangeMin)/numSteps
for j in xrange(-1,int(numSteps)+1):
for inequal in ["lt","gt"]:
threshVal = (rangeMin + float(j)*stepSize)
#print threshVal
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)
errArr = np.mat(np.ones((m,1)))
errArr[predictedVals==labelMat] = 0
weightedError = D.T*errArr if weightedError < minError:
minError = weightedError
bestClassEst = predictedVals.copy()
bestStump["dim"] = i
bestStump["thresh"] = threshVal
bestStump["ineq"] = inequal return bestStump,minError,bestClassEst '''训练多个单层决策树分类器,构成一个数组'''
def adaBoostTrainDS(dataArr,classLabels,numIt =40):
weakClassArr = []
m = np.shape(dataArr)[0]
D = np.mat(np.ones((m,1))/m)
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst = buildStump(dataArr,classLabels,D)
#print "D:",D.T
alpha = float(0.5*np.log((1.0-error)/max(error,1e-16)))
bestStump["alpha"] = alpha
weakClassArr.append(bestStump)
#print "ClassEst:",classEst.T.shape
expon = np.multiply(-1*alpha*np.mat(classLabels).T,classEst)
#print expon
D = np.multiply(D,np.exp(expon))
D = D / D.sum()
aggClassEst += alpha*classEst
#print "aggClassEst: ",aggClassEst.T
aggErrors = np.multiply(np.sign(aggClassEst)!= np.mat(classLabels).T,np.ones((m,1)))
errorRate = aggErrors.sum()/m
print "total error:",errorRate,"\n"
if errorRate ==0.0:
break
return weakClassArr '''分类器'''
def adaClassify(datToClass,classifierArr):
dataMatrix = np.mat(datToClass)
m = np.shape(dataMatrix)[0]
aggClassEst = np.mat(np.zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]["dim"],\
classifierArr[i]["thresh"],classifierArr[i]["ineq"])
aggClassEst += classifierArr[i]["alpha"]*classEst
#print aggClassEst
return np.sign(aggClassEst) '''载入数据'''
def loadDataSet(fileName):
numFeat = len(open(fileName).readline().split("\t"))
dataMat = []
labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = []
curLine = line.strip().split("\t")
for i in range(numFeat-1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
#print dataMat,labelMat
return dataMat,labelMat if __name__ == "__main__":
datArr,labelArr = loadDataSet("horseColicTraining2.txt") classifierArray = adaBoostTrainDS(datArr,labelArr,10)
testData,testY = loadDataSet("horseColicTest2.txt")
predictionArr = adaClassify(testData,classifierArray)
errorArr = np.mat(np.ones((len(testData),1)))
FinalerrorRate = errorArr[predictionArr!= np.mat(testY).T].sum()/float(errorArr.shape[0])
print "FinalerrorRate:",FinalerrorRate
3.实验结果
total error: 0.284280936455
total error: 0.284280936455
total error: 0.247491638796
total error: 0.247491638796
total error: 0.254180602007
total error: 0.240802675585
total error: 0.240802675585
total error: 0.220735785953
total error: 0.247491638796
total error: 0.230769230769
FinalerrorRate: 0.238805970149
4.实验总结
通过多个构建多个弱分类器,然后根据各个弱分类器的能力大小(即权重)来对分类结果进行加权求和,得出最终结果。只要数据集比较完整,这种方法还是很强大的,后续还可以尝试更多其他的分类器进行集成。
利用AdaBoost方法构建多个弱分类器进行分类的更多相关文章
- 用cart(分类回归树)作为弱分类器实现adaboost
在之前的决策树到集成学习里我们说了决策树和集成学习的基本概念(用了adaboost昨晚集成学习的例子),其后我们分别学习了决策树分类原理和adaboost原理和实现, 上两篇我们学习了cart(决策分 ...
- 【AdaBoost算法】弱分类器训练过程
一.加载数据(正样本.负样本特征) def loadSimpData(): #样本特征 datMat = matrix([[ 1. , 2.1, 0.3], [ 2. , 1.1, 0.4], [ 1 ...
- 利用AdaBoost元算法提高分类性能
当做重要决定时,大家可能都会吸取多个专家而不只是一个人的意见.机器学习处理问题时又何尝不是如此?这就是元算法背后的思路.元算法是对其他算法进行组合的一种方式. 自举汇聚法(bootstrap aggr ...
- 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
前言 最近在看Peter Harrington写的"机器学习实战",这是我的学习笔记,这次是第7章 - 利用AdaBoost元算法提高分类性能. 核心思想 在使用某个特定的算法是, ...
- 《机器学习实战第7章:利用AdaBoost元算法提高分类性能》
import numpy as np import matplotlib.pyplot as plt def loadSimpData(): dataMat = np.matrix([[1., 2.1 ...
- 【转载】 机器学习实战 - 读书笔记(07) - 利用AdaBoost元算法提高分类性能
原文地址: https://www.cnblogs.com/steven-yang/p/5686473.html ------------------------------------------- ...
- 【译】用boosting构建简单的目标分类器
用boosting构建简单的目标分类器 原文 boosting提供了一个简单的框架,用来构建鲁棒性的目标检测算法.这里提供了必要的函数来实现它:100% MATLAB实现,作为教学工具希望让它简单易得 ...
- Clumsy 利用无线网卡结合Clumsy软件模拟弱网络测试
利用无线网卡结合Clumsy软件模拟弱网络测试 by:授客 QQ:1033553122 实践环境 Clumsy 0.2 下载地址:http://jagt.github.io/clumsy/downlo ...
- 弱分类器的进化--Bagging、Boosting、Stacking
一般来说集成学习可以分为三大类: 用于减少方差的bagging 用于减少偏差的boosting 用于提升预测结果的stacking 一.Bagging(1996) 1.随机森林(1996) RF = ...
随机推荐
- HTTP Status 500 - Error instantiating servlet class XXXX
问题描述 web项目中请求出现错误,如下: HTTP Status 500 - Error instantiating servlet class XXXX类 type Exception rep ...
- 排序算法总结(C#版)
算法质量的衡量标准: 1:时间复杂度:分析关键字比较次数和记录的移动次数: 2:空间复杂度:需要的辅助内存: 3:稳定性:相同的关键字计算后,次序是否不变. 简单排序方法 .直接插入排序 直接插入排序 ...
- openid和unionId的区别
转:http://blog.csdn.net/wo849533144long/article/details/50194623
- Tornado输出和响应头
1.输出 再来看看输出`write`,实际上,`write`并没有直接把数据返回给前端,而是先写到缓存区,函数结束之后才会返回到前端,我们验证如下 class FlushHandler(tornado ...
- Oracle 常见hint
Hints 应该慎用,收集相关表的统计信息,根据执行计划,来改变查询方式 只能在SELECT, UPDATE, INSERT, MERGE, or DELETE 关键字后面,只有insert可以用2个 ...
- SecureCRT乱码问题解决方法
环境:SecureCRT登陆REDHAT5.3 LINUX系统 问题:vi编辑器编辑文件时文件中的内容中文显示乱码,但是直接使用linux系统terminal打开此文件时中文显示正常,确诊问题出现在客 ...
- linux下dmesg命令详解
前言: 有时候想查看一下开机启动信息,可以通过这个命令查询. 1,命令格式 功能说明:显示开机信息. 语 法:dmesg [-cn][-s <缓冲区大小>] 补充说明:kern ...
- 使用Docker模拟ansible集群环境
/etc/ansible/hosts 192.168.99.100 ansible_ssh_port=8081 ansible_ssh_user=root 配置容器免密码SSH登录
- DEV CheckComboboxEdit、CheckedListBoxControl(转)
CheckComboboxEdit //先清空所有,若在窗体Load事件中,也可以不清空 //cbRWYs.Properties.Items.Clear(); var RwyList = tspro. ...
- 2014.8.27 Vs2005宏的使用
终于知道怎么像在Word里那样使用宏了! 1.vs2005必须装补丁1 2.在C:\Program Files (x86)\Common Files\microsoft shared\VSA\8.0\ ...