机器学习基础之knn的简单例子
knn算法是人工智能的基本算法,类似于语言中的"hello world!",python中的机器学习核心模块:Scikit-Learn
Scikit-learn(sklearn)模块,为Python语言实现机器学习的核心模块,其包含了大量的算法模型函数API,
可以让我们很轻松地创建、训练、评估 算法模型。同时该模块也是Python在人工智能(机器学习)领域的基础应用模块。
核心依赖模块:
NumPy:pip install –U numpy
Scipy:pip install –U scipy
Pandas:pip install –U pandas
Matplotlib:pip install –U matplotlib
Scikit-Learn模块:
Scikit-Learn:pip install –U scikit-learn
机器学习分为五个步骤:
1.算法选型 看选择监督学习还是无监督学习
2.样本数据划分 需要样本数据对模型进行训练
3.魔性训练 使用fit()方法 算法模型对象.fit( X_train_features, X_train_labels )
4.模型评估 metrics 使用sklearn中的 meterics 类可以实现对训练后的模型进行量化指标评估
5.模型预测 predict Predict实现了对测试数据验证以及用于对新数据的预测
KNN算法的简单应用,文档树:
其中numbers.csv数据如下:
number,classes
1,A
2,A
3,A
4,B
5,B
6,B
7,C
8,C
9,C
num_knn.py源码:
from sklearn.neighbors import KNeighborsClassifier
import numpy as np
import matplotlib.pyplot as plt
import os
import pandas as pd
import imp
from sklearn.model_selection import train_test_split data=pd.read_csv(os.getcwd()+'\data'+os.sep+'numbers.csv')
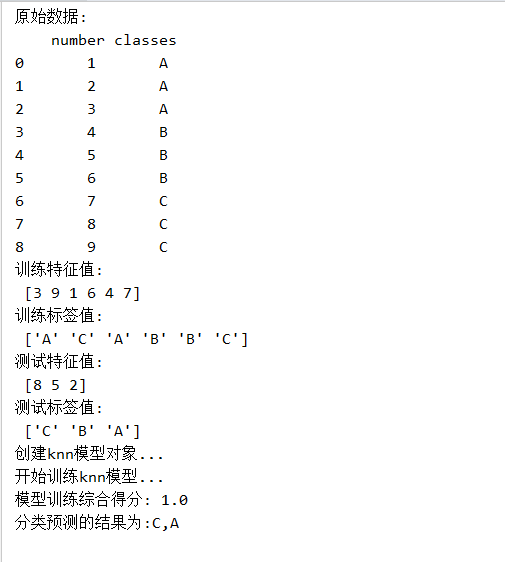
print('原始数据:\n',data) X_train,X_test,y_train,y_test=train_test_split(data['number'],data['classes'],test_size=0.25,random_state=40)
print('训练特征值:\n',X_train.values)
print('训练标签值:\n',y_train.values)
print('测试特征值:\n',X_test.values)
print('测试标签值:\n',y_test.values)
#print(y_train)
#print(y_test) plt.scatter(y_train,X_train) print('创建knn模型对象...')
knn=KNeighborsClassifier(n_neighbors=3) print('开始训练knn模型...')
knn.fit(X_train.values.reshape(len(X_train),1),y_train)
#print(X_train.values)
#print(X_train.values.reshape(len(X_train),1)) #变成列向量 # 评估函数
# 算法对象.score(测试特征值数据, 测试标签值数据)
score=knn.score(X_test.values.reshape(len(X_test),1),y_test)
print('模型训练综合得分:',score) # 步骤6:模型预测
# predict()函数实现
# predict(新数据(二维数组类型)): 分类结果
result = knn.predict([[12],[1.5]])
print('分类预测的结果为:{0},{1}'.format(result[0],result[1])) # 绘制测试数据点
plt.scatter(result[0], 12, color='r')
plt.scatter(result[1], 1.5, color='g')
plt.grid(linestyle='--')
plt.show()
运行结果如下图:
KNN第二个例子:
movies.csv:
filename,war_count,love_count,movietype
movieA,3,104,爱情片
movieB,2,100,爱情片
movieC,1,81,爱情片
movieD,101,10,战争片
movieF,99,5,战争片
movieF,98,2,战争片
movie_knn.py:
import pandas as pd
import os
import imp
#导入分解词
from sklearn.model_selection import train_test_split
#导入knn算法模型
from sklearn.neighbors import KNeighborsClassifier
# 导入分类器性能监测报告模块
from sklearn.metrics import classification_report def loaddata(filepath): #加载数据
data=pd.read_csv(filepath)
print('样本数据集:\n',data)
#print('样本数据集:\n{0}'.format(data)) # 步骤2:数据抽取
# 获取war_count、love_count、movietype列数据
data = data[['war_count', 'love_count', 'movietype']]
print('原始样本数据集(数据抽取):\n{0}'.format(data)) # 返回数据
return data def splitdata(data):
print('--数据划分--')
X_train,X_test,y_train,y_test=train_test_split(data[['war_count','love_count']],data['movietype'],\
test_size=0.25,random_state=30)
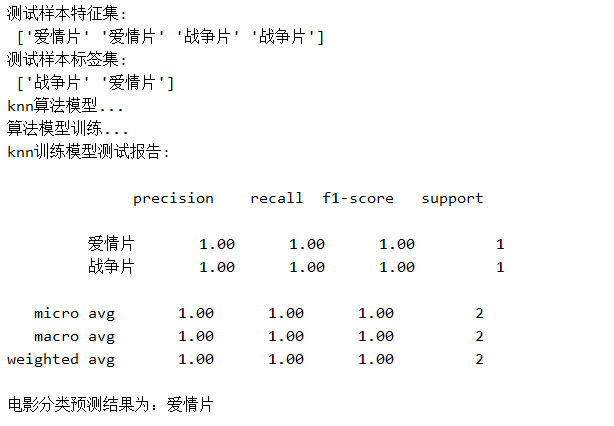
print('训练样本特征集:\n', X_train.values)
print('训练样本标签集:\n', X_test.values)
print('测试样本特征集:\n', y_train.values)
print('测试样本标签集:\n', y_test.values) # 返回数据
return X_train, X_test, y_train, y_test def ModelTraing(X_train,X_test,y_train,y_yest):
#先创建knn算法模型
print('knn算法模型...')
knn=KNeighborsClassifier(n_neighbors=3) #训练算法模型
print('算法模型训练...')
knn.fit(X_train,y_train) #训练模型评估
result=knn.predict(X_test)
print('knn训练模型测试报告:\n')
print(classification_report(y_test,result,target_names=data['movietype'].unique())) return knn if __name__=='__main__':
# 设置数据文件的地址
filePath = os.getcwd() + '\data' + os.sep + 'movies.csv'
print(filePath)
# 加载数据文件
data = loaddata(filePath)
# 数据划分
X_train, X_test, y_train, y_test = splitdata(data)
# 模型训练
knn = ModelTraing(X_train, X_test, y_train, y_test)
# 模型应用
movietype = knn.predict([[20, 94]])
print('电影分类预测结果为:{0}'.format(movietype[0]))
代码运行结果:
附上GitHub地址 tyutltf/knn_basic: knn的简单例子 https://github.com/tyutltf/knn_basic
机器学习基础之knn的简单例子的更多相关文章
- 通过Redux源码学习基础概念一:简单例子入门
最近公司有个项目使用react+redux来做前端部分的实现,正好有机会学习一下redux,也和小伙伴们分享一下学习的经验. 首先声明一下,这篇文章讲的是Redux的基本概念和实现,不包括react- ...
- Python机器学习基础教程-第1章-鸢尾花的例子KNN
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- Python机器学习基础教程-第2章-监督学习之K近邻
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- Python机器学习基础教程-第2章-监督学习之决策树集成
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- Python机器学习基础教程-第2章-监督学习之决策树
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- Python机器学习基础教程-第2章-监督学习之线性模型
前言 本系列教程基本就是摘抄<Python机器学习基础教程>中的例子内容. 为了便于跟踪和学习,本系列教程在Github上提供了jupyter notebook 版本: Github仓库: ...
- 机器学习(1) - TensorflowSharp 简单使用与KNN识别MNIST流程
机器学习是时下非常流行的话题,而Tensorflow是机器学习中最有名的工具包.TensorflowSharp是Tensorflow的C#语言表述.本文会对TensorflowSharp的使用进行一个 ...
- Python3实现机器学习经典算法(二)KNN实现简单OCR
一.前言 1.ocr概述 OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗.亮的模式确定其形状,然 ...
- 数据分析之Matplotlib和机器学习基础
一.Matplotlib基础知识 Matplotlib 是一个 Python 的 2D绘图库,它以各种硬拷贝格式和跨平台的交互式环境生成出版质量级别的图形. 通过 Matplotlib,开发者可以仅需 ...
随机推荐
- C# 中关于radiobutton控件的使用
在一个Form窗口中定义了3个radiobutton,radioButton1.radioButton2和radioButton3,以及button1和button2(这里可以是其他控件) 为了实现单 ...
- vue-cli项目接口地址可配置化(多环境部署)一处修改多处适用
本文档目的在于帮助对vue了解比较少的同学,能够快速配置vue应用中的接口地址.方便项目切换服务环境后,重新修改多组件的http请求地址. 一.前言 我们在上一篇文章分享了vue-cli项目基本搭建( ...
- Exchange 2016的MAPI over HTTP简介
一.MAPI over HTTP的简介 MAPI(消息处理应用程序编程接口)over HTTP是传输协议,可将传输层移到行业标准HTTP模型中,从而提升Outlook 和 Exchange连接的可靠性 ...
- python操作oracle小测试
首先使用python操作数据库需要导入cx_Oracle包import cx_Oracle这个包需要单独下载,下载地址:https://pypi.python.org/pypi/cx_Oracle使用 ...
- 设计模式——简单工厂模式(SimpleFactory Pattern)
最近做项目总是遇到这样或者那样的问题,代码不够简洁,代码可扩展性不够好,耦合度又太高了,导致经常有种想去重构又无从下手的感觉. 无意间翻出了之前买的一本书<大话设计模式>读了一遍,受益匪浅 ...
- Android开发经验01:31个Android开发实战经验
1. 在Android library中不能使用switch-case语句访问资源ID:在Android library中不能使用switch-case语句访问资源ID的原因分析及解决方案 2. 不能 ...
- Android(java)学习笔记48:通过反射获得带参构造方法并且使用
1. 反射获得带参构造方法并且使用: (1)获取字节码文件对象 Class c = Class.forName("cn.itcast_01.Person"); (2)获 ...
- 关于Unix哲学
http://www.ruanyifeng.com/blog/2009/06/unix_philosophy.html 这几天,我在看Unix,发现很多人在谈"Unix哲学",也就 ...
- BZOJ1718:[USACO]Redundant Paths 分离的路径(双连通分量)
Description In order to get from one of the F (1 <= F <= 5,000) grazing fields (which are numb ...
- 【转】eclipse 错误信息 "File Search" has encounter a problem 解决
在eclipse中使用搜索功能,发生错误: "File Search" has encounter a problem 仔细看了一下自动跳出的错误日志(Error Log),发现: ...