【Python3 爬虫】01_简单页面抓取
运行平台:Winodows 10
Python版本:Python 3.4.2
IDE:Sublime text3
网络爬虫
网络爬虫,也叫网络蜘蛛(Web Spider),如果把互联网比喻成一个蜘蛛网,Spider就是一只在网上爬来爬去的蜘蛛。网络爬虫就是根据网页的地址来寻找网页的,也就是URL。举一个简单的例子,我们在浏览器的地址栏中输入的字符串就是URL,例如:https://www.baidu.com/
URL就是统一资源定位符(Uniform Resource Locator),遵守以下语法规则:
scheme://host.domain:port/path/filename
解释:
- scheme - 定义因特网服务的类型。最常见的类型是 http
- host - 定义域主机(http 的默认主机是 www)
- domain - 定义因特网域名,比如 baidu.com
- :port - 定义主机上的端口号(http 的默认端口号是 80)
- path - 定义服务器上的路径(如果省略,则文档必须位于网站的根目录中)。
- filename - 定义文档/资源的名称
第一个爬虫
爬虫例子
我们以爬取163首页为例子(网址:http://www.163.com/)
#-*- coding:utf-8 -*-
"""
Author :OLIVER
Date :2018-03-22
Describe:简单爬虫
"""
from urllib import request if __name__=="__main__":
response = request.urlopen("http://www.163.com/")
html = response.read()
print(html)
urllib使用使用request.urlopen()打开和读取URLs信息,返回的对象response如同一个文本对象,我们可以调用read(),进行读取。再通过print(),将读到的信息打印出来。
运行程序ctrl+B,可以在Sublime中查看运行结果,如下:
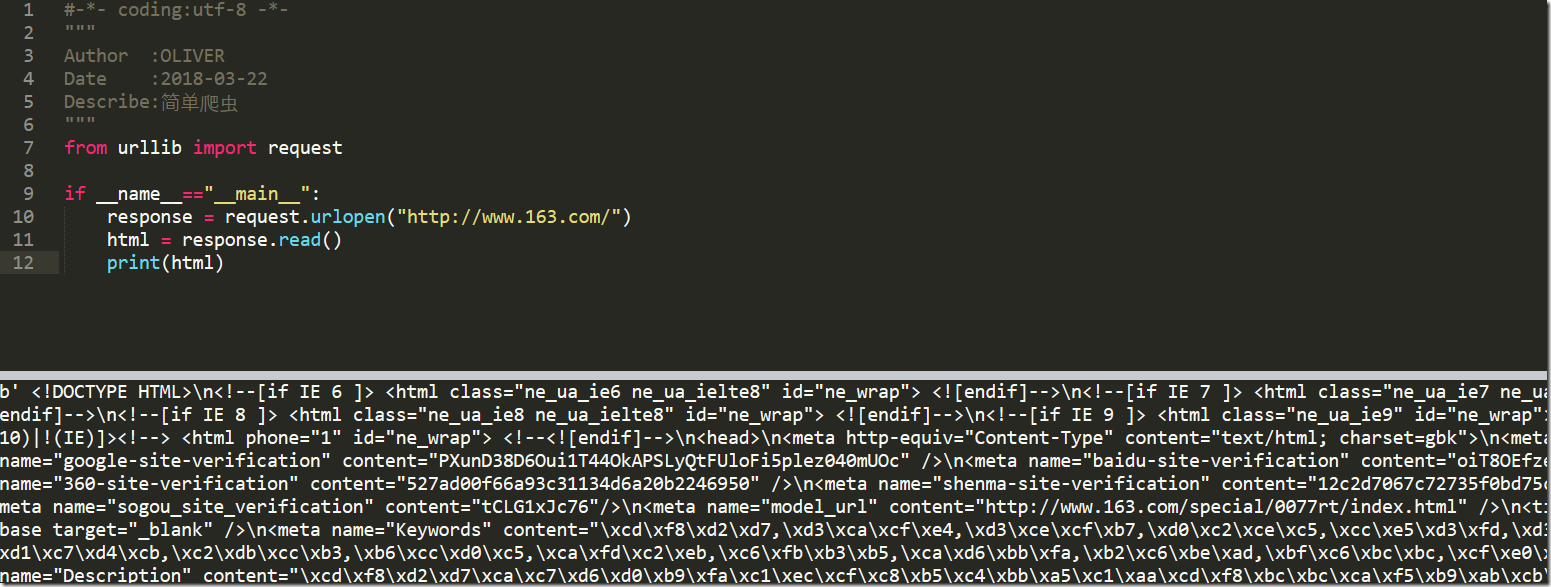
这些信息就是浏览器接受到的信息,只不过我们在看浏览器内容的时候,浏览器对这些内容进行了转换,让我们看着更舒服
或许你从上面可以看出,虽然我们已经成功获取了信息,但是这些信息都是二进制的,看起来很不方便,那么我们如何处理呢?
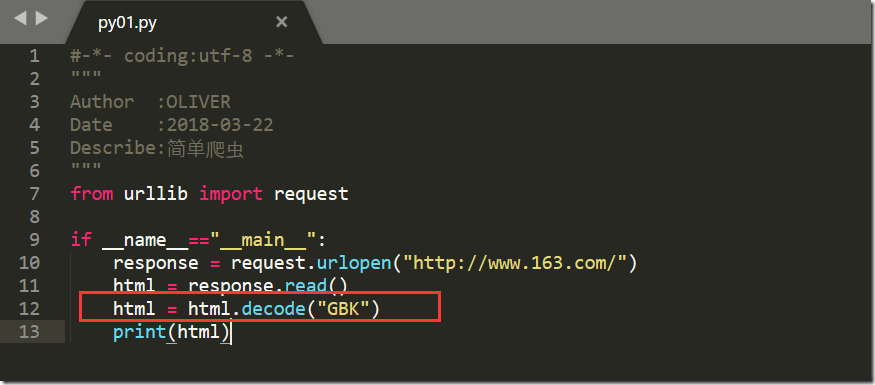
我们可以通过decode()命令将网页的信息进行解码,并显示出来
首先,我们查看网页的源码,查看原本网页编码格式
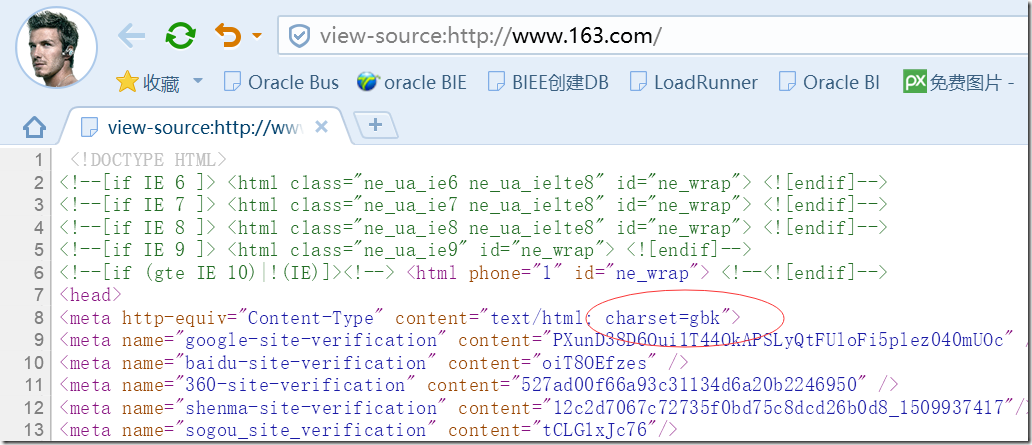
我们看到是GBK,那接下来我们开始转码
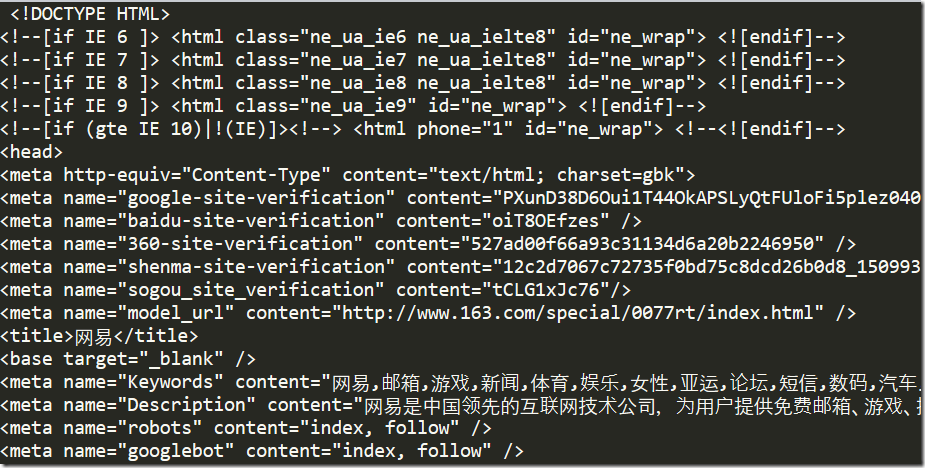
转码后,我们看到得到的结果跟我们查看源码的结果是一致的
自动获取编码格式
获取有人觉得上述获取编码格式的方法太麻烦了,那么如何自动获取编码格式呢?
使用chardet类库即可

也可以直接在DOS窗口输入命令在线安装

自动获取编码格式代码示例
from urllib import request
import chardet if __name__=="__main__":
response = request.urlopen("http://www.163.com/")
html = response.read()
charset = chardet.detect(html)
print(charset)
运行程序,输结果:

同时呢,加入我们现在有很多网页,那么我们不可能一一去看,我们在这就可以想到把这个第三方库封装为一个函数,然后遍历多个网页即可
下面是我封装遍历的一个例子:
# -*- coding:UTF-8 -*- from urllib import request
import chardet def auto_GetCharset(url):
response = request.urlopen(url)
html = response.read()
charset = chardet.detect(html)
value = charset['encoding']
return value """
定义一个列表,然后依次查看列表元素的编码格式
"""
Web_list = ["http://www.baidu.com/",
"http://www.163.com/",
"https://www.jd.com/",
"https://www.youku.com/"]
for url in Web_list:
charset = auto_GetCharset(url)
print(url,charset)
运行结果

盲点
程序中我新增了__name__=="__main__"这段代码
解释:
__name__ 是当前模块名,当模块被直接运行时模块名为 __main__ 。这句话的意思就是,当模块被直接运行时,以下代码块将被运行,当模块是被导入时,代码块不被运行
例如:
我们现在有文件const.py
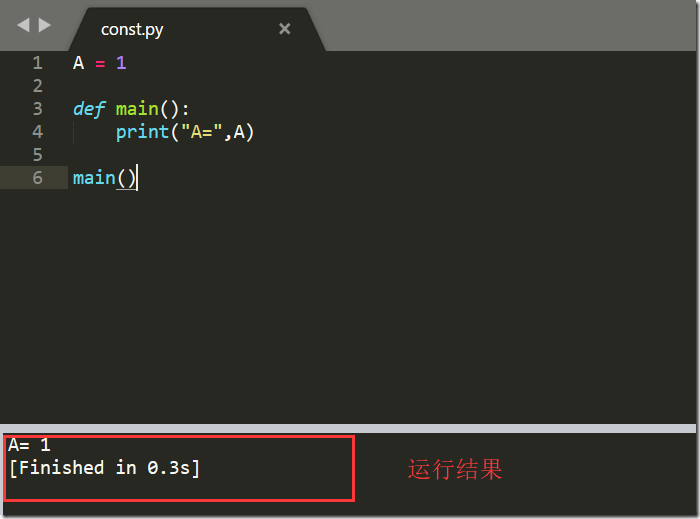
另外还存在一个计算和sm.py的文件
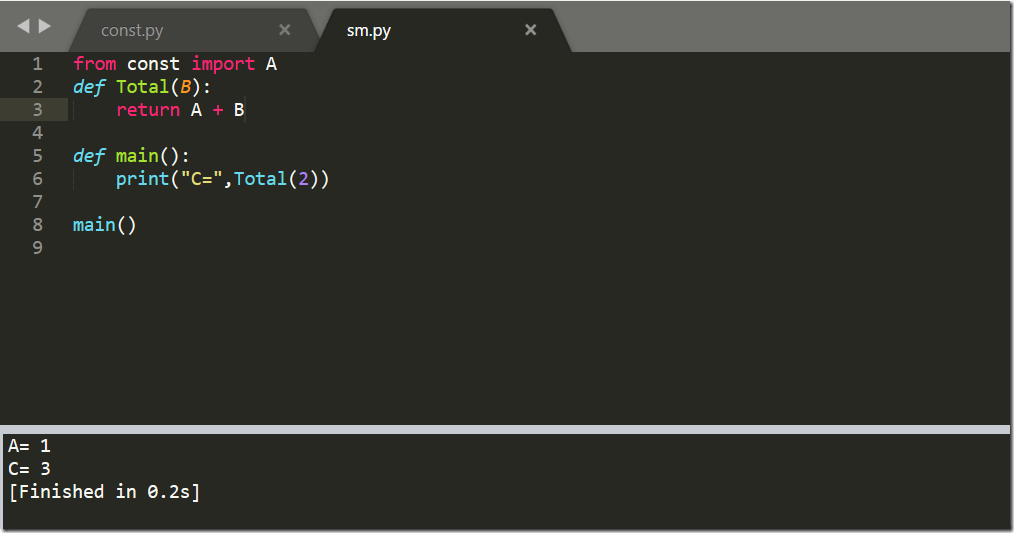
现在他导入模块const,并且也运行了const中的print语句了,我们在const中添加__name__=="__main__"
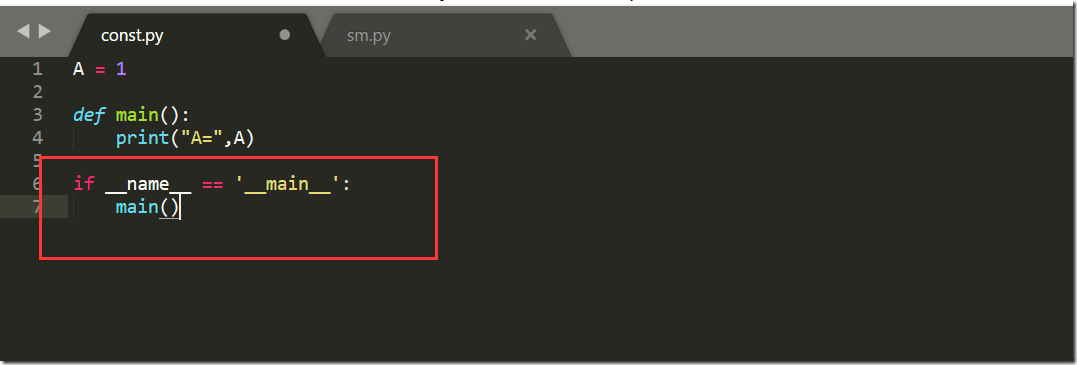
再次运行sm.py
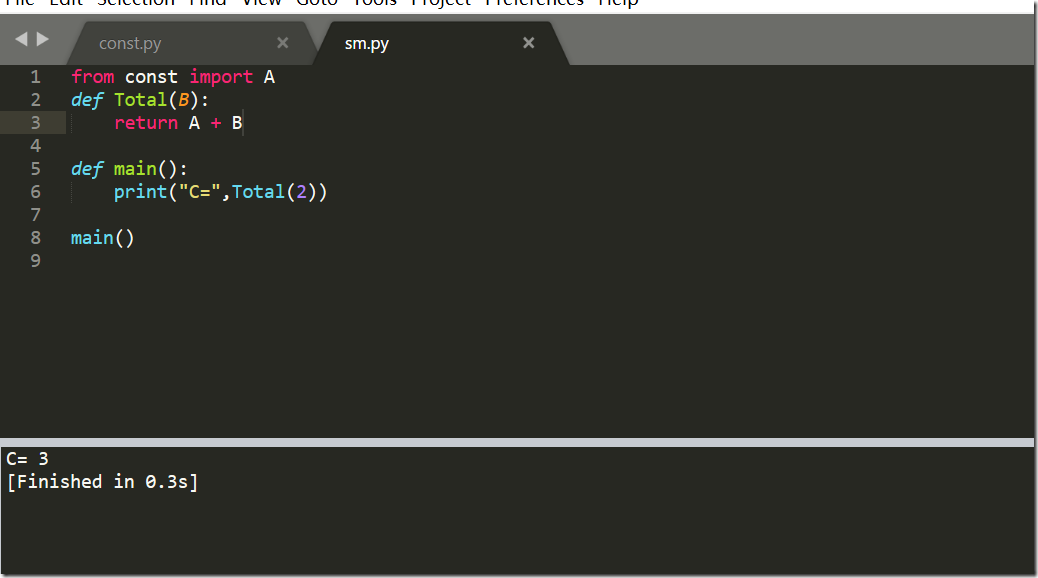
已经不打印了
【Python3 爬虫】01_简单页面抓取的更多相关文章
- Python3爬虫:利用Fidder抓取手机APP的数据
1.什么是Fiddler? Fiddler是一个http协议调试代理工具,它能够记录并检查所有你的电脑和互联网之间的http通讯,设置断点,查看所有的“进出”Fiddler的数据(指cookie,ht ...
- python3爬虫-分析Ajax,抓取今日头条街拍美图
# coding=utf-8 from urllib.parse import urlencode import requests from requests.exceptions import Re ...
- python爬虫beta版之抓取知乎单页面回答(low 逼版)
闲着无聊,逛知乎.发现想找点有意思的回答也不容易,就想说要不写个爬虫帮我把点赞数最多的给我搞下来方便阅读,也许还能做做数据分析(意淫中--) 鉴于之前用python写爬虫,帮运营人员抓取过京东的商品品 ...
- python3.4学习笔记(十四) 网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例
python3.4学习笔记(十四) 网络爬虫实例代码,抓取新浪爱彩双色球开奖数据实例 新浪爱彩双色球开奖数据URL:http://zst.aicai.com/ssq/openInfo/ 最终输出结果格 ...
- iOS开发——网络实用技术OC篇&网络爬虫-使用青花瓷抓取网络数据
网络爬虫-使用青花瓷抓取网络数据 由于最近在研究网络爬虫相关技术,刚好看到一篇的的搬了过来! 望谅解..... 写本文的契机主要是前段时间有次用青花瓷抓包有一步忘了,在网上查了半天也没找到写的完整的教 ...
- python爬虫(一)_爬虫原理和数据抓取
本篇将开始介绍Python原理,更多内容请参考:Python学习指南 为什么要做爬虫 著名的革命家.思想家.政治家.战略家.社会改革的主要领导人物马云曾经在2015年提到由IT转到DT,何谓DT,DT ...
- Python爬虫实战六之抓取爱问知识人问题并保存至数据库
大家好,本次为大家带来的是抓取爱问知识人的问题并将问题和答案保存到数据库的方法,涉及的内容包括: Urllib的用法及异常处理 Beautiful Soup的简单应用 MySQLdb的基础用法 正则表 ...
- 分布式爬虫:使用Scrapy抓取数据
分布式爬虫:使用Scrapy抓取数据 Scrapy是Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据.Scrapy用途广泛,可以用于数据挖掘. ...
- 一次Python爬虫的修改,抓取淘宝MM照片
这篇文章是2016-3-2写的,时隔一年了,淘宝的验证机制也有了改变.代码不一定有效,保留着作为一种代码学习. 崔大哥这有篇>>小白爬虫第一弹之抓取妹子图 不失为学python爬虫的绝佳教 ...
随机推荐
- hdu 5185(动态规划)
Equation Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Su ...
- centos 命令行修改主机名
# vi /etc/sysconfig/network # 把localhost.localdomain 修改为 localhost.com # 保存退出 # vi /etc/hosts # 把loc ...
- HDU 5935 Car【贪心,枚举,精度】
Problem Description Ruins is driving a car to participating in a programming contest. As on a very t ...
- uva11168
uva11168 题意 给出一些点坐标,选定一条直线,所有点在直线一侧(或直线上),使得所有点到直线的距离平均值最小. 分析 显然直线一定会经过某两点(或一点),又要求点在直线某一侧,可以直接求出凸包 ...
- 加快Vue项目的开发速度
巧用Webpack Webpack是实现我们前端项目工程化的基础,但其实她的用处远不仅仅如此,我们可以通过Webpack来帮我们做一些自动化的事情.首先我们要了解require.context()这个 ...
- 【博弈论】【SG函数】【枚举】bzoj1188 [HNOI2007]分裂游戏
因为第i个瓶子里的所有豆子都是等价的,设sg(i)表示第i个瓶子的sg值,可以转移到sg(j)^sg(k)(i<j<n,j<=k<n)的状态. 只需要考虑豆子数是奇数的瓶子啦, ...
- 【计算几何】bzoj2338 [HNOI2011]数矩形
对于两条线段,若其中点重合,且长度相等,那么它们一定是某个矩形的对角线. N*N地处理出所有线段,排序,对每一部分中点重合.长度相等的线段进行暴力枚举,更新答案. 用 long double 注意EP ...
- Java高级架构师(一)第03节:多模块多Web应用合并War包
多模块.多Web应用合并war包 在日常的系统开发中,如果担心各个系统的资源同名覆盖,可以在总的War模块下放置一份最终的资源. 将版本号改成9.1.0.v20131115,ok 在Idea中的Mav ...
- Asp.Net MVC part3 路由Route
路由Route路由规则Route:可以查看源代码了解一下构造方法,需要指定路由格式.默认值.处理器三个值路由数据RouteData:当前请求上下文匹配路由规则而得到的一个对象,可以在Action中通过 ...
- 使用Python的turtle模块画出最简单的五角星
代码如下: import turtle def main(): t = turtle.Turtle() t.hideturtle() lengthOfSize = 200 drawFivePointS ...