通过Ambari2.2.2部署HDP大数据服务
| node1 | amari-server | |
| node2 | amari-agent | namenode1,datanode,resourcemanager,zk |
| node3 | amari-agent | namenode2,datanode,zk |
官方安装文档:https://cwiki.apache.org/confluence/display/AMBARI/Install+Ambari+2.2.2+from+Public+Repositories
1.关闭防火墙和selinux,配置hosts,配置ssh免密码登录,时间同步,安装好jdk和ntp服务并启动
2.安装yum源和相关软件(在线安装很慢,可以把文件下载下来配置本地yum)
cd /etc/yum.repos.d/
wget http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.2.2.0/ambari.repo
yum install ambari-server postgresql-server #node1执行
3.运行ambari-server setup命令设置Ambari
其他默认
设置JDK时候选择3,然后输入jdk的路径
选择数据库类型时候选择1(可根据自己需求安装其他数据库)
3.1启动Amabri
ambari-server start
成功启动后在浏览器输入nod1:8080,用户名和密码admin
3.2安装jdbc驱动
在 ambari-server 上停止 ambari-server 服务,然后在命令行使用
ambari-server setup --jdbc-db=mysql --jdbc-driver=/root/mysql-connector-java-5.1./mysql-connector-java-5.1.-bin.jar #开始配置 jdbc-driver 连接器
此步操作会完成以下几个步骤:
- 在server本机,会将目标连接器拷贝到 /usr/lib/ambari-server/resources/ 目录中。
- 在集群内的所有成员机中,配置连接器信息。
配置完成后,再启动 ambari-server 服务,即可。
4.开始安装大数据
4.1点击上面登录成功页面的Launch Install Wizard 按钮进行集群配置
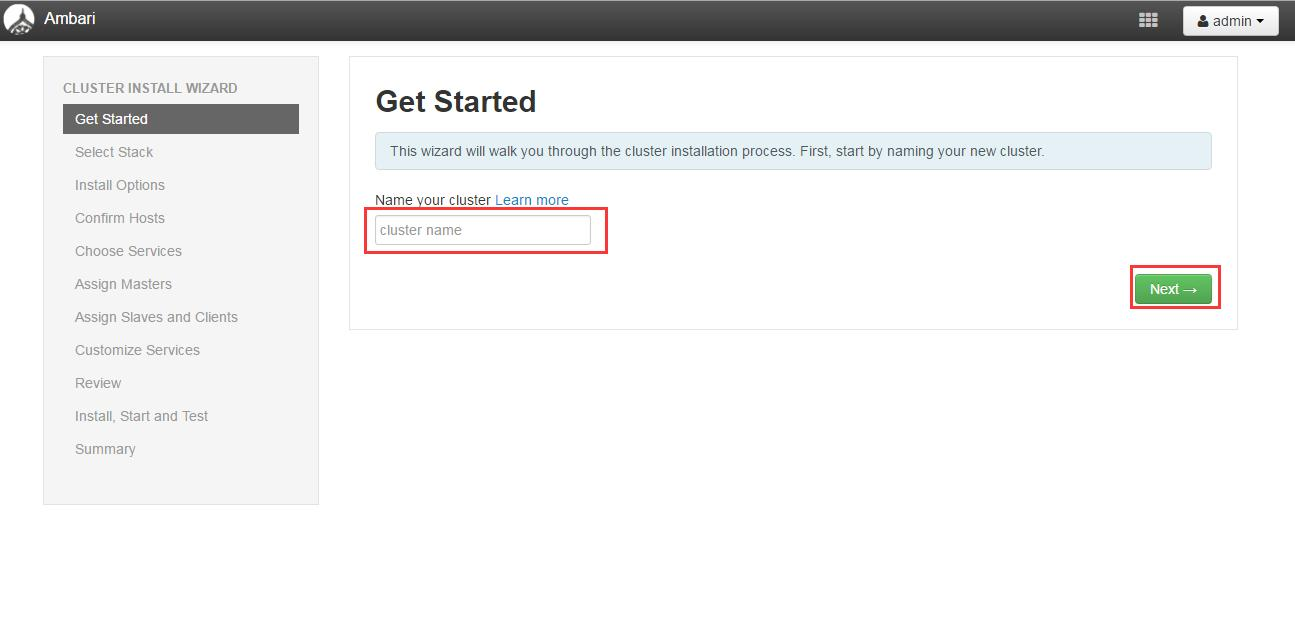
4.2版本号选择和操作系统
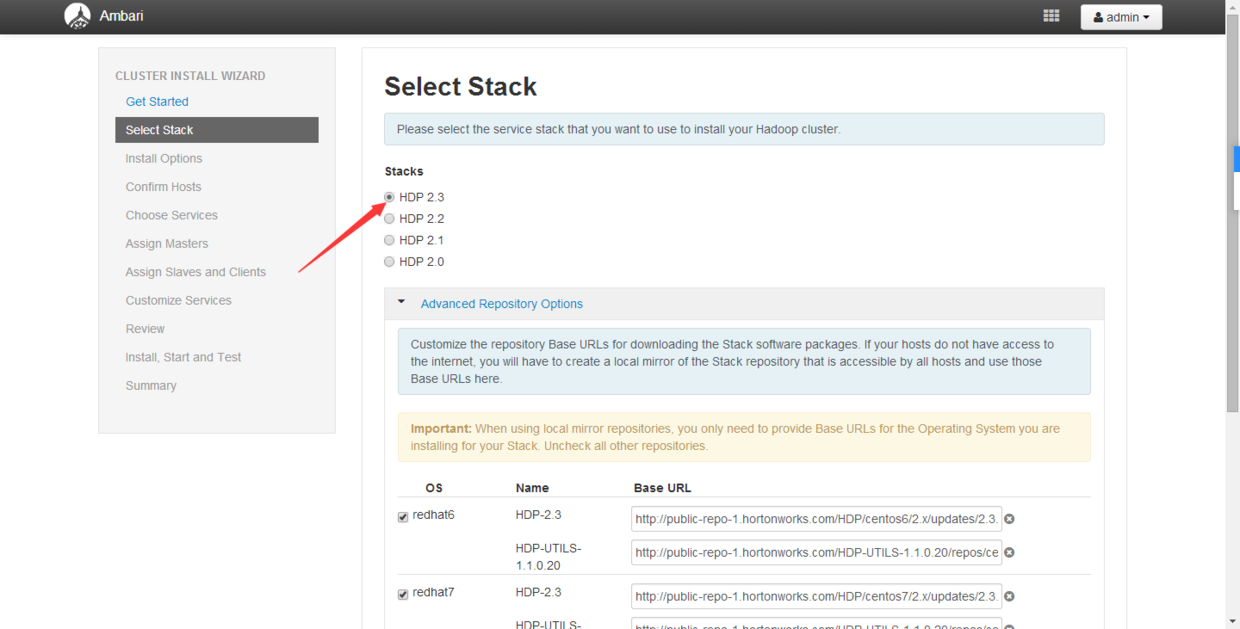
如果是使用本地yum源:
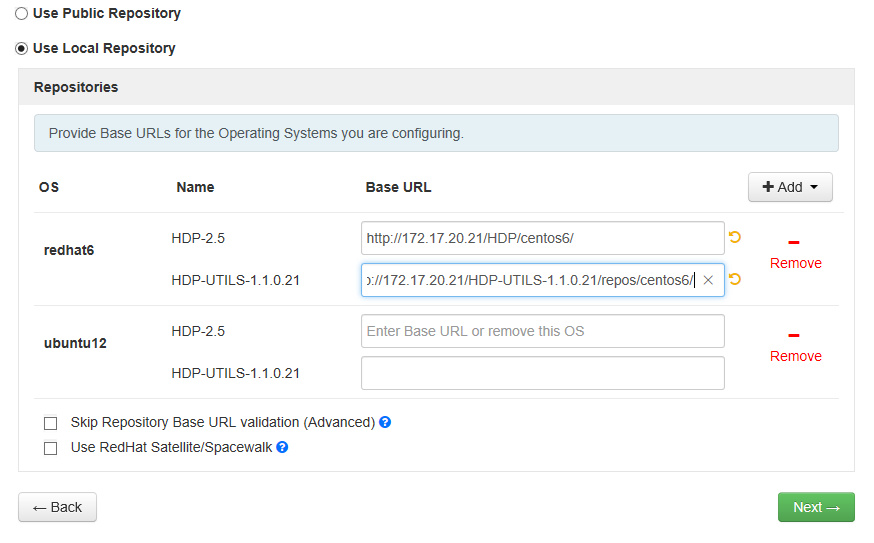
4.3输入节点名称和选择私钥
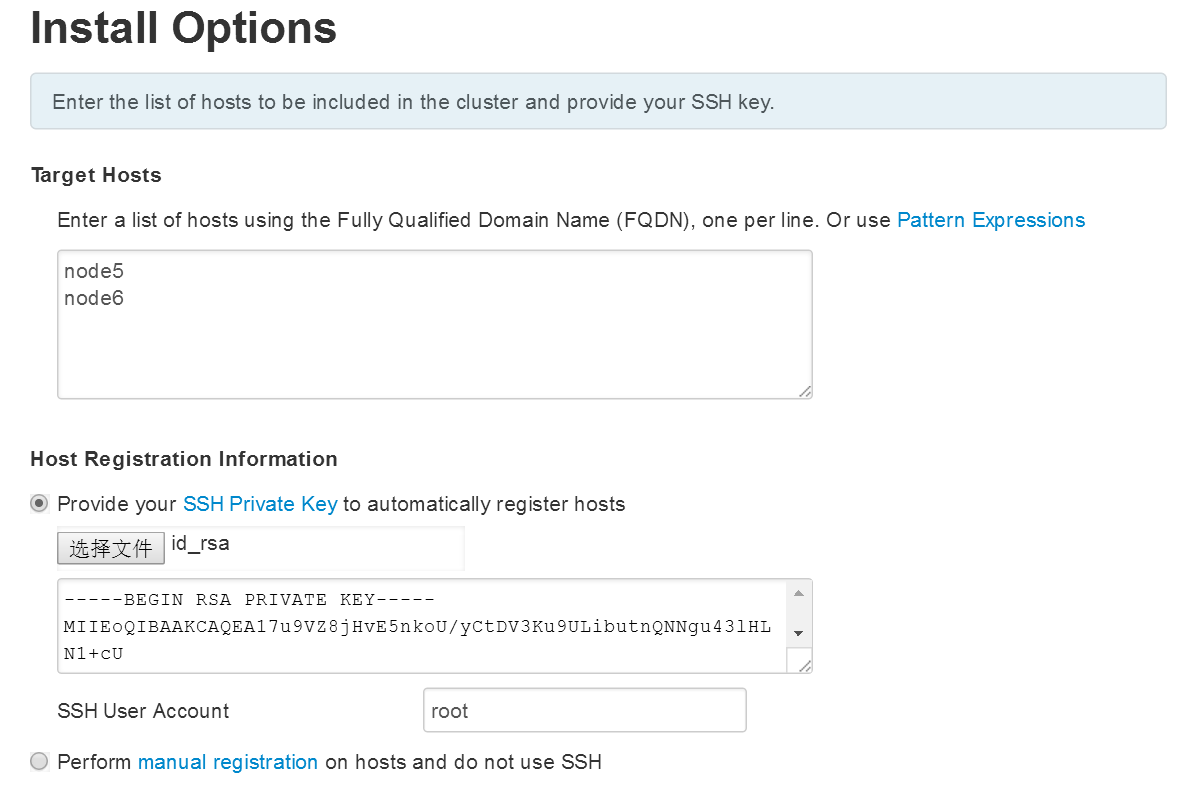
4.4会自动安装ambari-agent,然后进行注册,这里可能比较慢
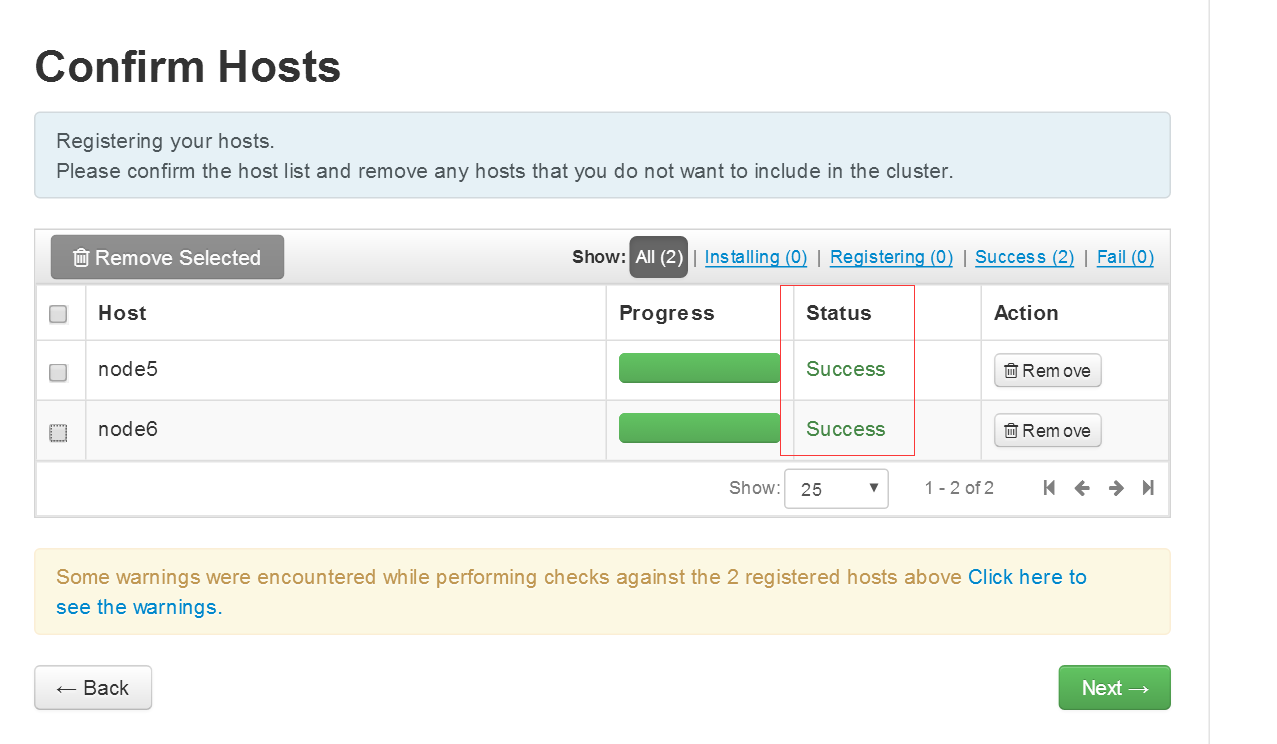
如果遇到错误,按照要求排查
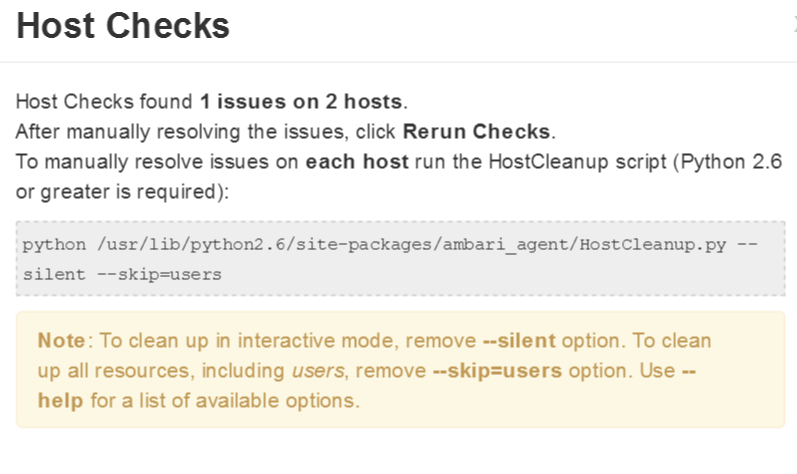
4.5选择要安装的服务

4.6服务的master配置和slave配置,可按需修改
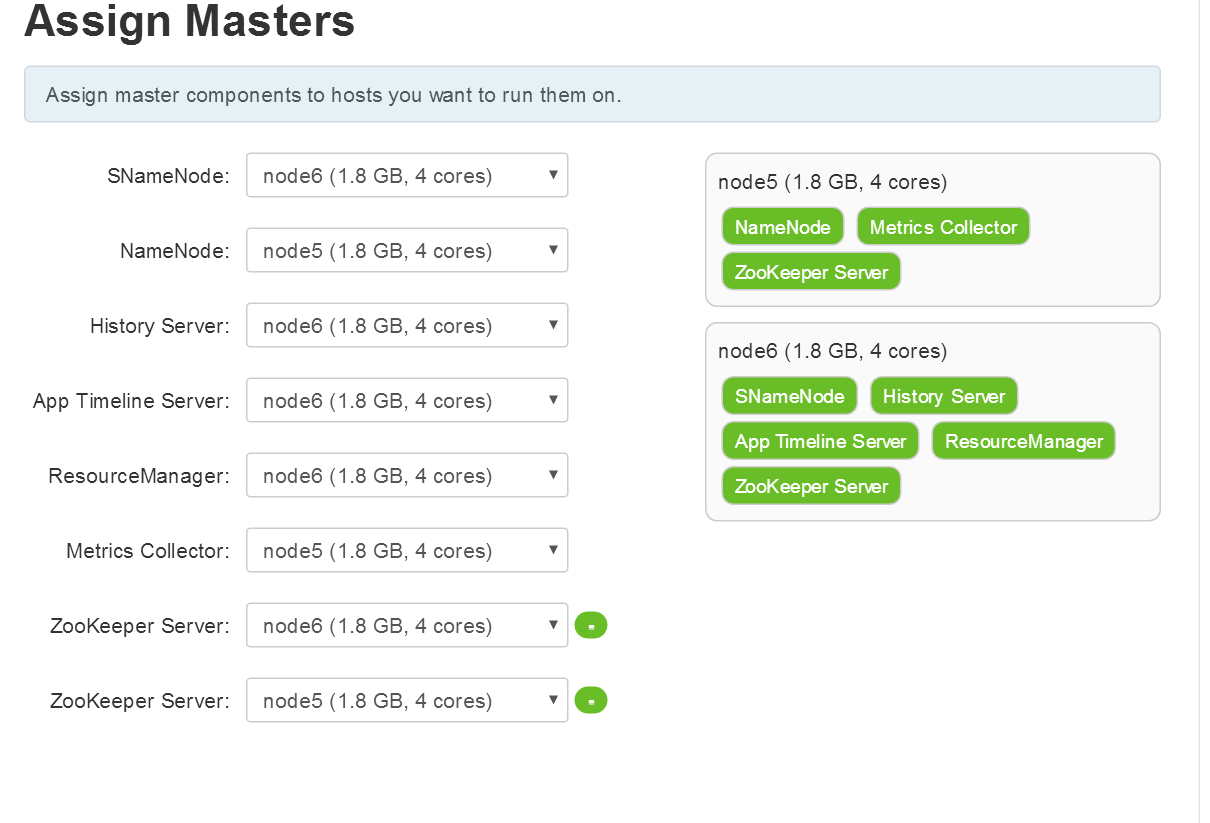
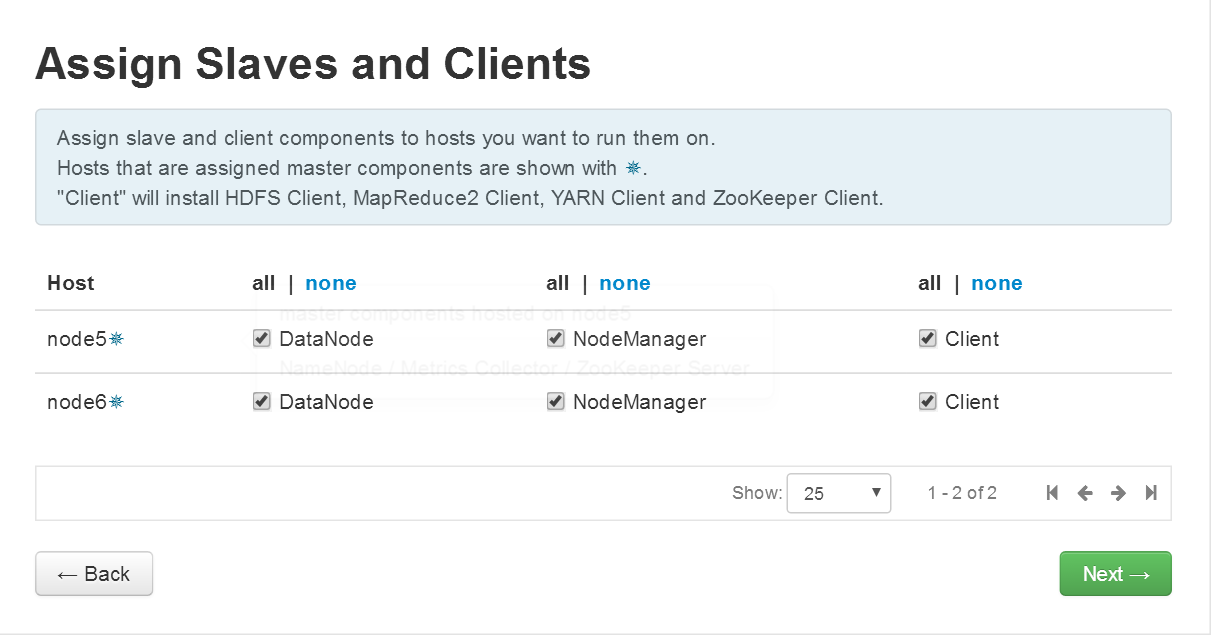
4.7服务的客户化配置,可以根据需求修改

HDP配置lzo
yum -y install lzo lzo-devel hadooplzo hadooplzo-native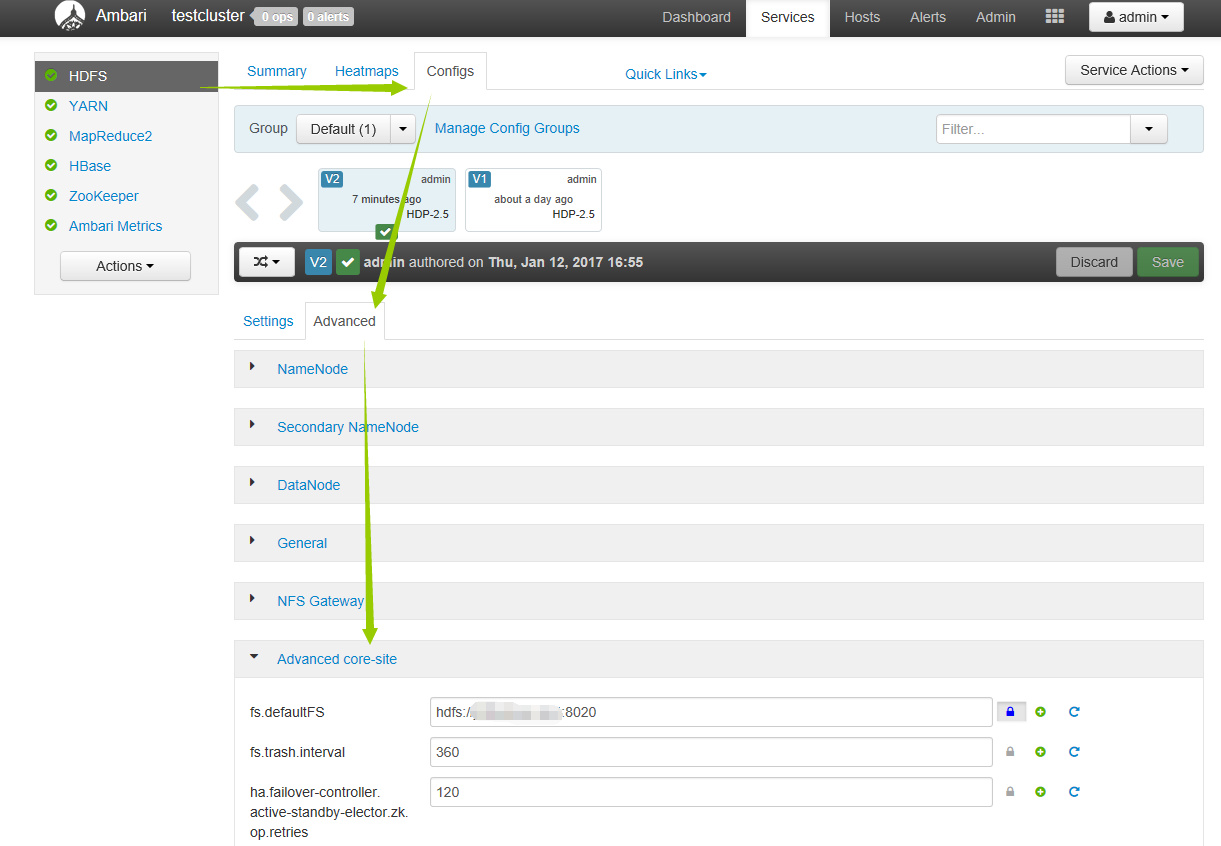
找到 Advanced core-site 项,在 io.compression.codecs 的原有value值中添加 com.hadoop.compression.lzo.LzoCodec
找到 Custom core-site 项,添加key为 io.compression.codec.lzo.class 且值为 com.hadoop.compression.lzo.LzoCodec 。
保存配置。 重启集群服务即可。
测试lzo:执行
hbase org.apache.hadoop.hbase.util.CompressionTest hdfs://mycluster/test_lzo lzo4.8检查配置信息
4.9开始安装
安装各个服务,并且完成安装后会启动相关服务,安装过程比较长,如果中途出现错误,请根据具体提示或者log进行修改
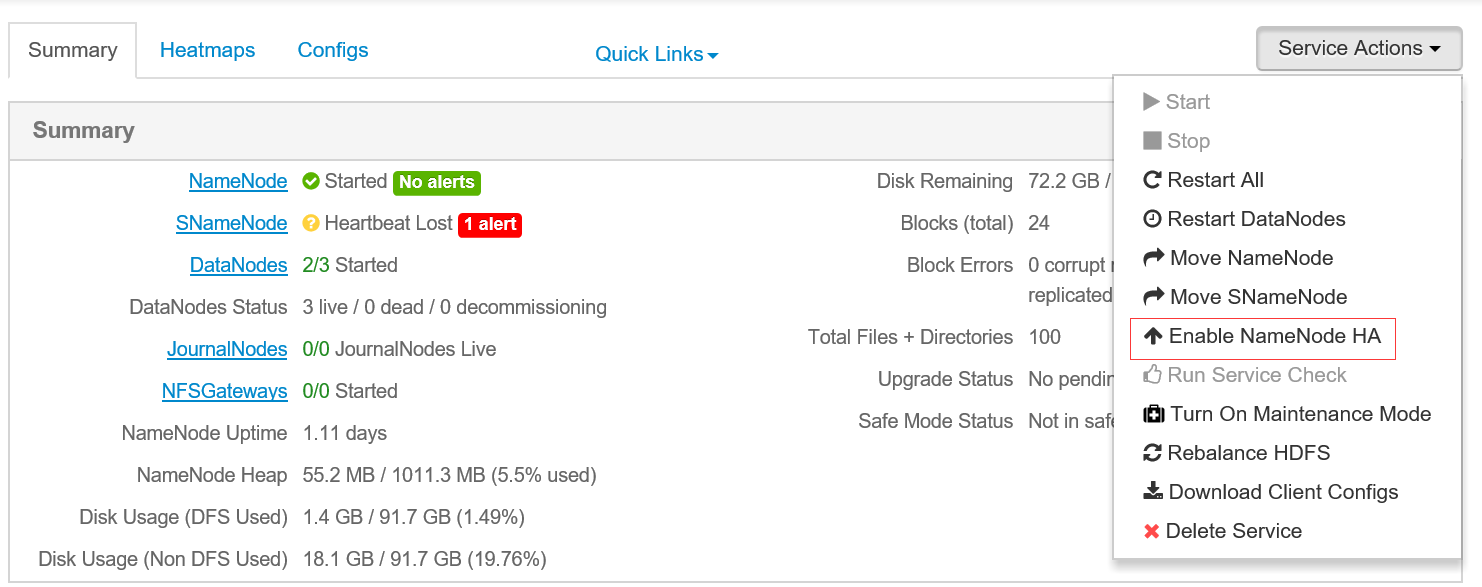
NameNode HA配置
In Ambari Web, select
Services > HDFS > Summary.Select Service Actions and choose Enable NameNode HA
ResourceManager HA配置
- 可参考 https://docs.hortonworks.com/HDPDocuments/Ambari-2.2.1.1/bk_Ambari_Users_Guide/content/_how_to_configure_resourcemanager_high_availability.html
- In Ambari Web, browse to
Services > YARN > Summary. SelectService Actionsand chooseEnable ResourceManager HA.
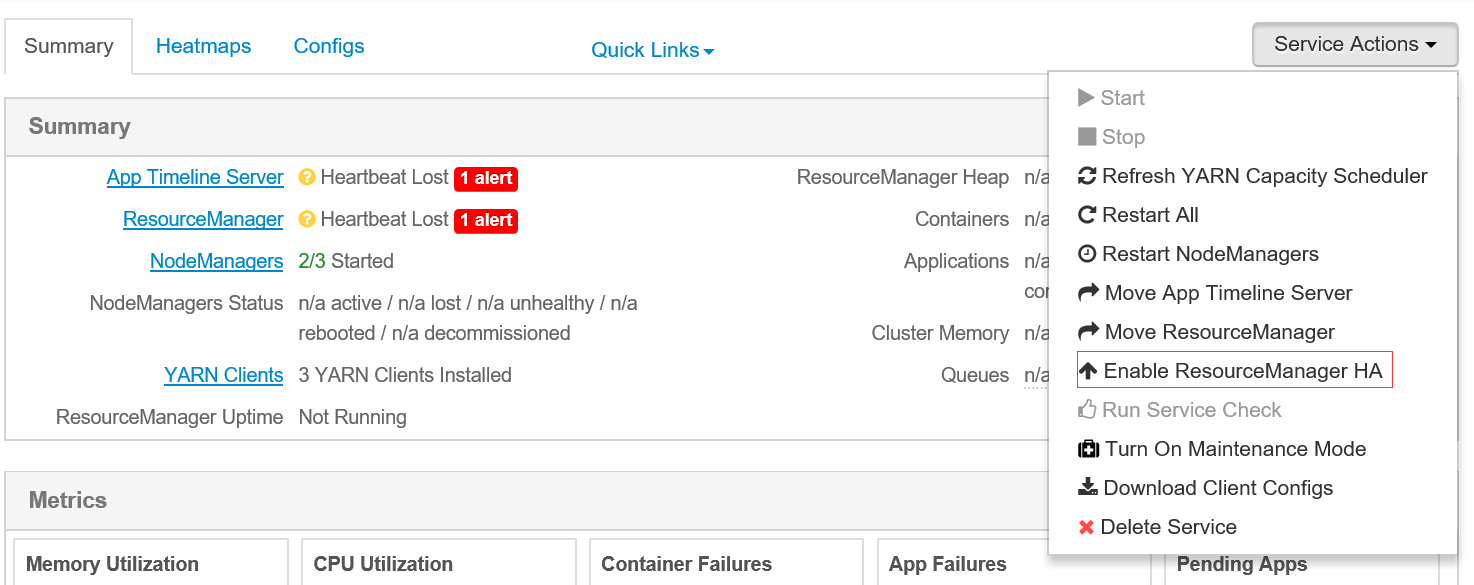
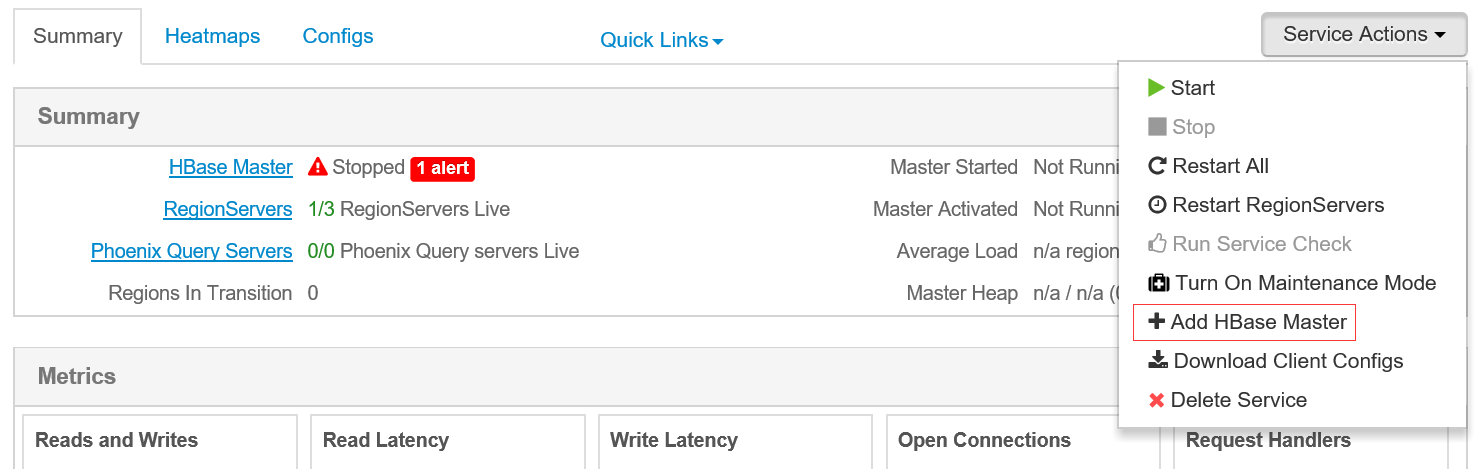
Hbase HA配置
In Ambari Web, browse to
Services > HBase.In Service Actions, select the
+ Add HBase Masteroption.Choose the host to install the additional HBase Master, then choose Confirm Add.
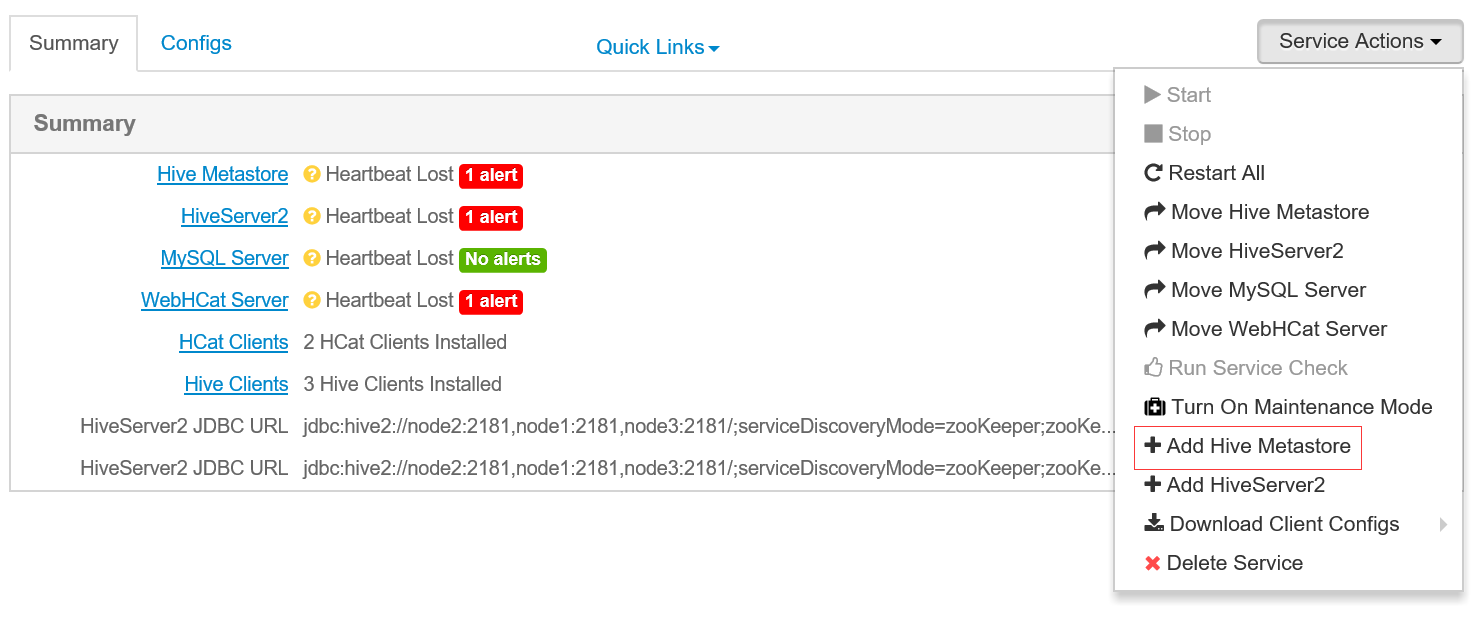
Hive HA配置
In Ambari Web, browse to
Services > Hive.In Service Actions, select the
+ Add Hive Metastoreoption.Choose the host to install the additional Hive Metastore, then choose Confirm Add.
- Ambari installs the component and reconfigures Hive to handle multiple Hive Metastore instances.
参考:
http://www.jianshu.com/p/6e59df5f2461
http://blog.csdn.net/daiyutage/article/details/52210830
https://my.oschina.net/wstone/blog/521987
http://www.ibm.com/developerworks/cn/opensource/os-cn-bigdata-ambari/
http://www.linuxidc.com/Linux/2014-12/110824.htm
离线安装:
http://www.itweet.cn/2015/08/31/hdp-install/
通过Ambari2.2.2部署HDP大数据服务的更多相关文章
- 大数据服务大比拼:AWS VS. AzureVS.谷歌
[TechTarget中国原创] 对于企业用户来说,大数据服务是一项较具吸引力的云服务.三大巨头AWS.Azure以及谷歌都在力争夺得头把交椅,但是最后到底是哪一家能够取得王座之战的胜利呢? 云市场正 ...
- MaxCompute,基于Serverless的高可用大数据服务
摘要:2019年1月18日,由阿里巴巴MaxCompute开发者社区和阿里云栖社区联合主办的“阿里云栖开发者沙龙大数据技术专场”走近北京联合大学,本次技术沙龙上,阿里巴巴高级技术专家吴永明为大家分享了 ...
- InfoQ —— 腾讯游戏大数据服务场景与应用
简介 周东祥,本人从2010年毕业进入腾讯互动娱乐部门工作,一直致力在腾讯游戏运营开发工作.先后负责SAP业务受理系统,盗号自助系统,元数据系统以及近2年在腾讯游戏大数据运营开发中积累大量的大数据开发 ...
- HDP 大数据平台搭建
一.概述 Apache Ambari是一个基于Web的支持Apache Hadoop集群的供应.管理和监控的开源工具,Ambari已支持大多数Hadoop组件,包括HDFS.MapReduce.Hiv ...
- 我的ElasticSearch集群部署总结--大数据搜索引擎你不得不知
摘要:世上有三类书籍:1.介绍知识,2.阐述理论,3.工具书:世间也存在两类知识:1.技术,2.思想.以下是我在部署ElasticSearch集群时的经验总结,它们大体属于第一类知识“techknow ...
- 三分钟部署Laxcus大数据管理系统
Laxcus是Laxcus大数据实验室历时五年,全体系自主设计研发的国内首套大数据管理系统.能够支撑百万台级计算机节点,提供EB量级存储和计算能力,兼容SQL和关系数据库.最新的2.x版本已经实现对当 ...
- IT大数据服务管理高级课程(IT服务,大数据,云计算,智能城市)
个人简历 金石先生是马克思主义中国化的研究学者,上海财经大学经济学和管理学硕士,中国民主建国会成员,中国特色社会主义人文科技管理哲学的理论奠基人之一.金石先生博学多才,对问题有独到见解.专于工作且乐于 ...
- Windows Azure上的大数据服务: HDInsight的介绍
这个视频介绍了目前非常流行的大数据处理框架Hadoop的Windows Azure上的实现:HDInsight,以及利用MapReduce来对大数据进行分析,利用Hive进行查询,利用客户端Power ...
- 卸载HDP大数据平台
使用以下说明卸载HDP: 停止所有已安装的HDP服务.请参阅HDP参考指南中的停止HDP服务. 如果安装了Knox,请在所有群集节点上运行以下命令: 对于RHEL / CentOS / Oracle ...
随机推荐
- 前端之CSS——盒子模型和浮动
一.CSS盒子模型 HTML文档中的每个元素都被描绘成矩形盒子,这些矩形盒子通过一个模型来描述其占用空间,这个模型称为盒子模型. 盒子模型通过四个边界来描述:margin(外边距),border(边框 ...
- 从零开始的全栈工程师——ajax
AJAX AJAX 是一种在无需重新加载整个网页的情况下,能够更新部分网页的技术. AJAX = Asynchronous JavaScript and XML. AJAX 是一种用于创建快速动态网页 ...
- mui使用技巧
1.document.addEventListener('plusready', function(){ //console.log("所有plus api都应该在此事件发生后调用,否则会出 ...
- 如何设置树莓派的VNC开机时启动
转载:http://www.linuxidc.com/Linux/2016-12/138793.htm 下面正式开始配置 首先 sudo nano /etc/init.d/vncserver 然后 复 ...
- solidity语言6
映射 可以认为是哈希,格式 mapping(_KeyType => _ValueType) pragma solidity ^0.4.0; contract MappingExample { m ...
- MapReduce框架结构及代码示例
一个完整的 mapreduce 程序在分布式运行时有三类实例进程: 1.MRAppMaster:负责整个程序的过程调度及状态协调 2.MapTask:负责 map 阶段的整个数据处理流程 3.Redu ...
- Java IO 整理总结
read(byte b[], int off, int len) 方法的作用是从输入流中读取 len 个字节,并把数据写入到字节数组b中,并返回实际读取了多少数据.如果没有读取到任何数据,意味着文件已 ...
- 【Spring实战】—— 16 基于JDBC持久化的事务管理
前面讲解了基于JDBC驱动的Spring的持久化管理,本篇开始则着重介绍下与事务相关的操作. 通过本文你可以了解到: 1 Spring 事务管理的机制 2 基于JDBC持久化的事务管理 Spring的 ...
- IOS CoreData的(增删查改)
(1).CoreDataa>什么是CoreDatab>CoreData增删改查 "什么时候使用COredata 什么时候使用FMDatabases"CoreData 在 ...
- Android进阶笔记10:ListView篇之ListView显示多种类型的条目(item)
ListView可以显示多种类型的条目布局,这里写显示两种布局的情况,其他类似. 1. 这是MainActivity,MainActivity的布局就是一个ListView,太简单了这里就不写了,直接 ...