使用Stable Diffusion制作AI数字人视频的简明教程
基本方法
搞一张照片,搞一段语音,合成照片和语音,同时让照片中的人物动起来,特别是头、眼睛和嘴。
语音合成
语音合成的方法很多,也比较成熟了,大家可以选择自己方便的,直接录音也可以,只要能生成一个语音文件就行了。
这里分享一个文字转语音的工具:https://ttsmaker.cn/,不用注册不用花钱,使用起来很简单。(广告时间:目前国内的AI资源也很丰富了,我做了一个汇总:萤火AI大全,不用特殊网络设置,快速找到想用的AI工具)
如下图所示 :输入你的文字,选择播音员,填写验证码,点击转换按钮。
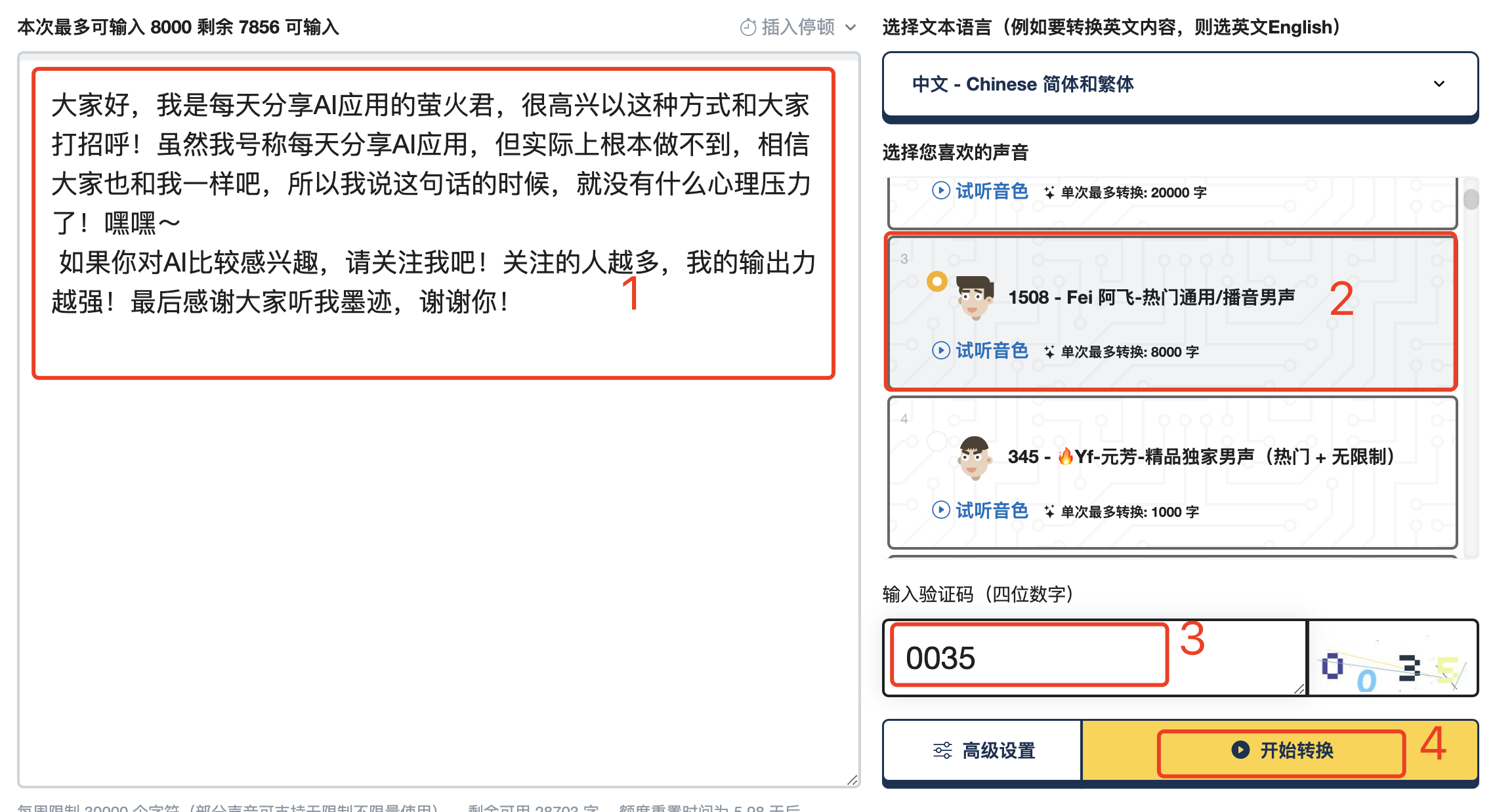
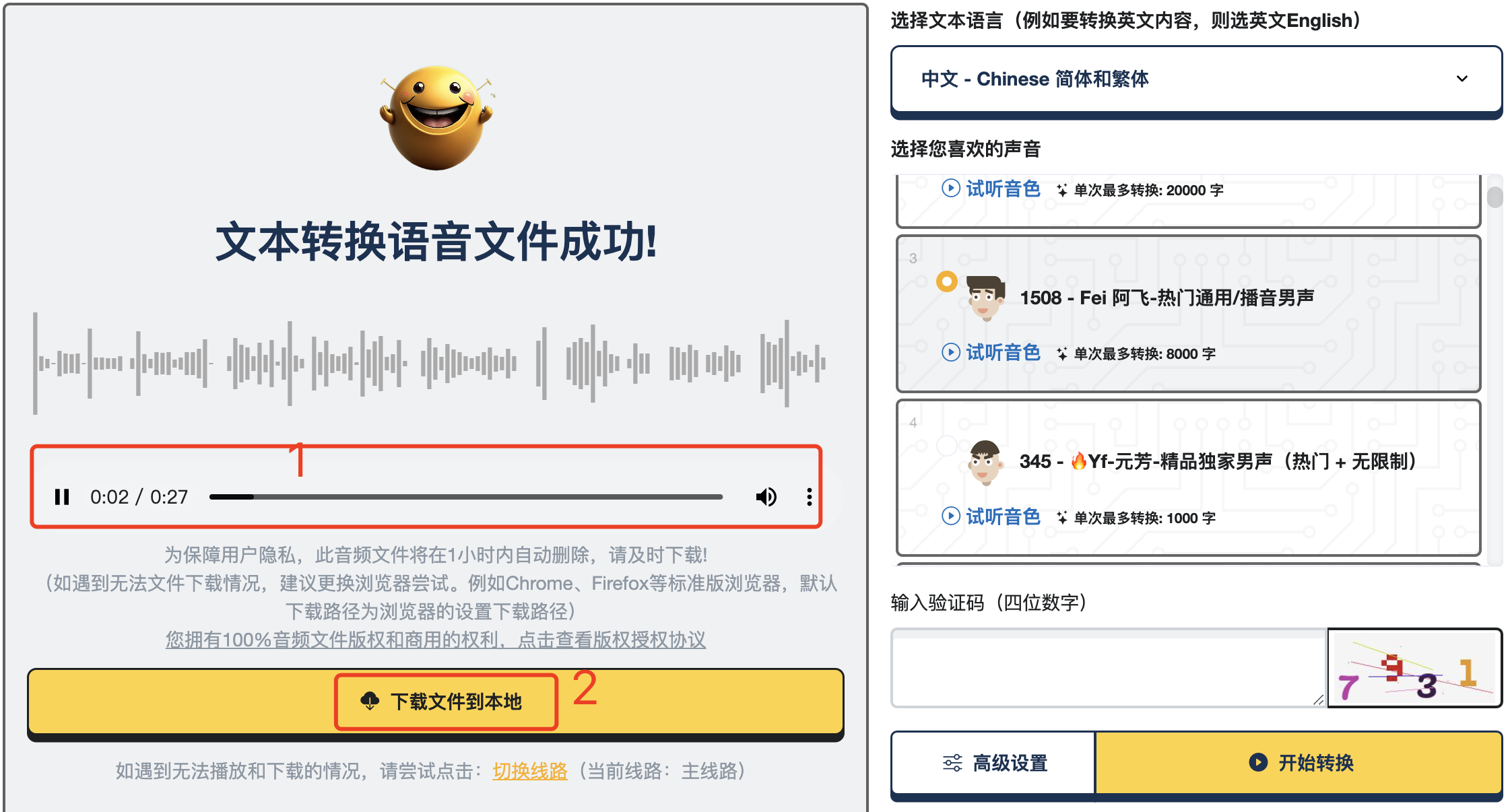
生成速度挺快的,然后在左边这里可以试听和下载。
照片生成
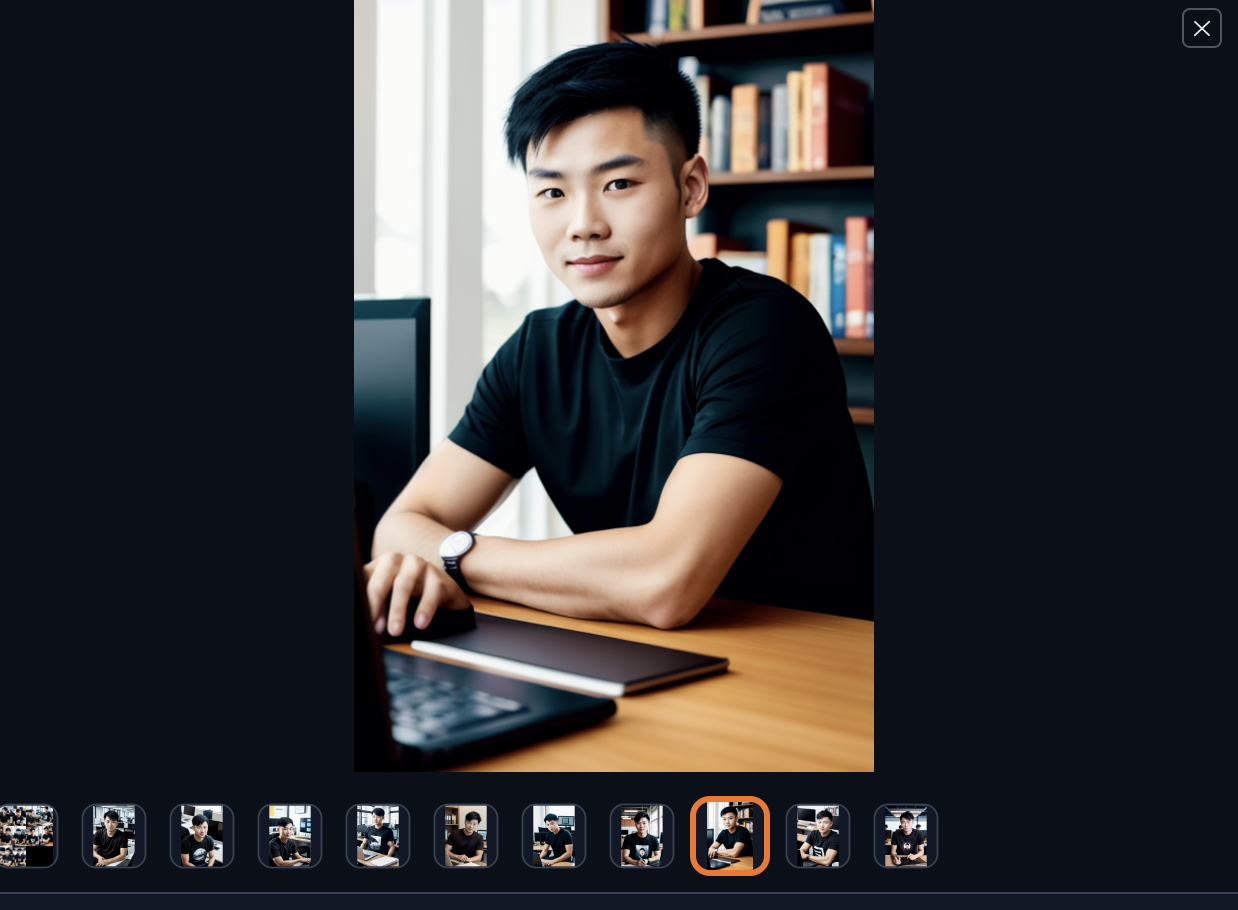
这里介绍的方法需要使用比较真实的照片,如果太二次元了,视频人脸的效果会比较差。大家可以使用自己真实的照片,也可以使用Stable Diffusion生成一张,也可以使用图生图稍微改造下自己的照片,总之要尽量真实一些。
另外这张照片尽量正面一些,侧脸生成的视频可能会出现头和身体拼接不太好的情况,所以如果有证件照是最好的。
我这里演示生成一张真实照片,看AI生成的美女都有些厌倦了,今天我们生成个帅哥。
(1)生成工具使用 Stable Diffusion WebUI,模型选择 realisticVisionV20,这个模型生成的图片看起来比较真实。
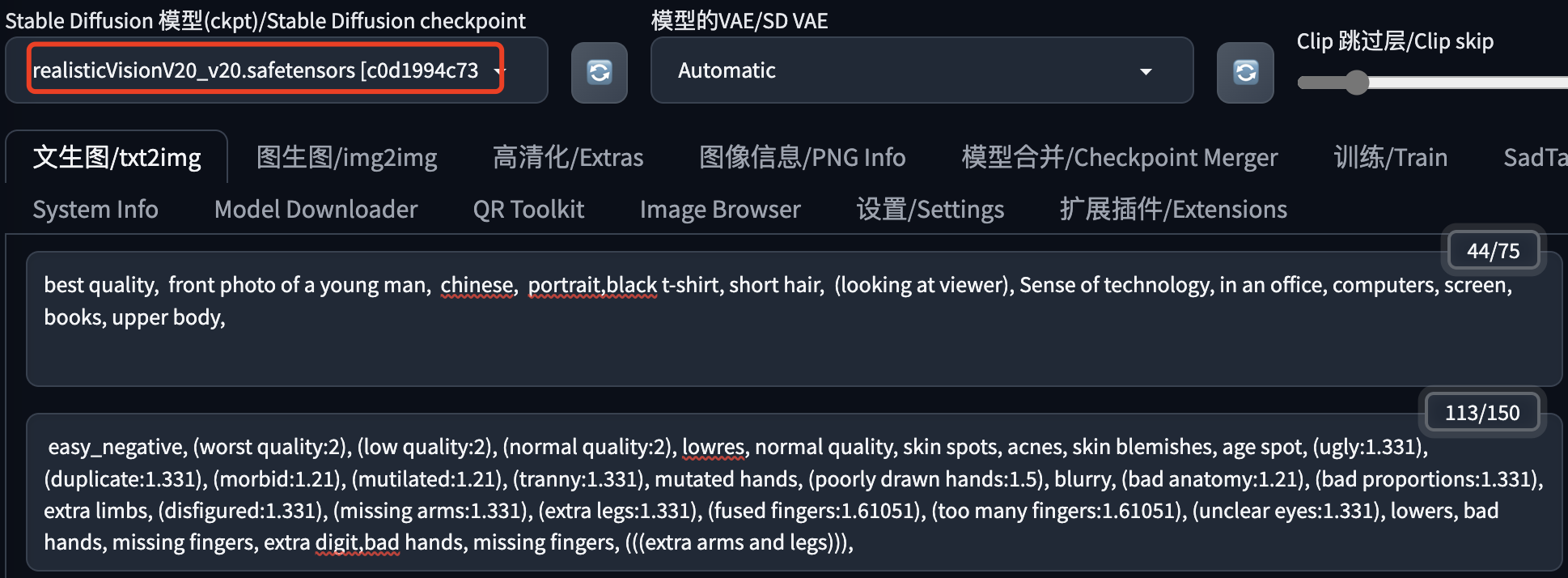
提示词:best quality, front photo of a young man, chinese, portrait,black t-shirt, short hair, (looking at viewer), Sense of technology, in an office, computers, screen, books, upper body,
反向提示词: easy_negative, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, skin spots, acnes, skin blemishes, age spot, (ugly:1.331), (duplicate:1.331), (morbid:1.21), (mutilated:1.21), (tranny:1.331), mutated hands, (poorly drawn hands:1.5), blurry, (bad anatomy:1.21), (bad proportions:1.331), extra limbs, (disfigured:1.331), (missing arms:1.331), (extra legs:1.331), (fused fingers:1.61051), (too many fingers:1.61051), (unclear eyes:1.331), lowers, bad hands, missing fingers, extra digit,bad hands, missing fingers, (((extra arms and legs))),
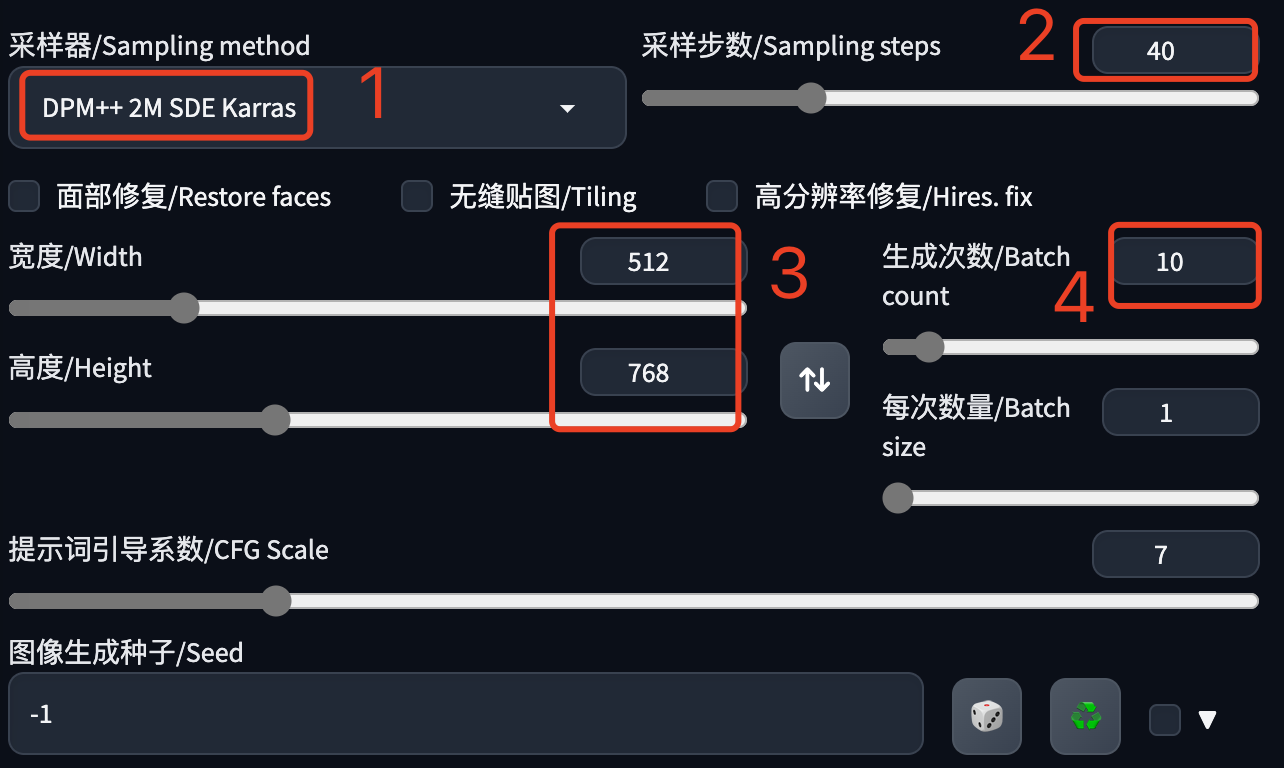
(2)采样器这里选择DPM++ 2M SDE Karras,选择别的也没问题,只要生成一张人物照片就可以了。
采样步数根据采样器选择,这里是40,建议20-40,以实际出图效果为准。
尺寸这里选择竖版,放到手机里会比较合适。
生成次数:建议先把提示词写好了,然后一次多生成几张,从里边选择最好的,节省时间。
(3)这里我选择一张自认为看起来还不错的图片,把这张图下载下来备用。
视频合成
这是最关键的一步,这里还是使用Stable Diffusion WebUI,不过只是使用其中的一个插件,这个插件的名字就是SadTalker。
SadTalker是Github上开源的,主要成员也都是国内的技术大佬,地址:https://github.com/OpenTalker/SadTalker.git
这里默认大家都安装好Stable Diffusion WebUI了,如果还没安装过的朋友,建议去AutoDL上租一个服务器体验下,方便不贵,选择A5000规格的就差不多了,安装教程网上应该挺多的,这里就不啰嗦了,还不会的可以联系我。
关于SadTalker插件的安装方法我这里介绍两种。
安装方法一
适合访问Github或者外网比较顺畅的用户,因为需要自动下载很多东西。
在SD WebUI中通过扩展插件页面安装,如下图所示:
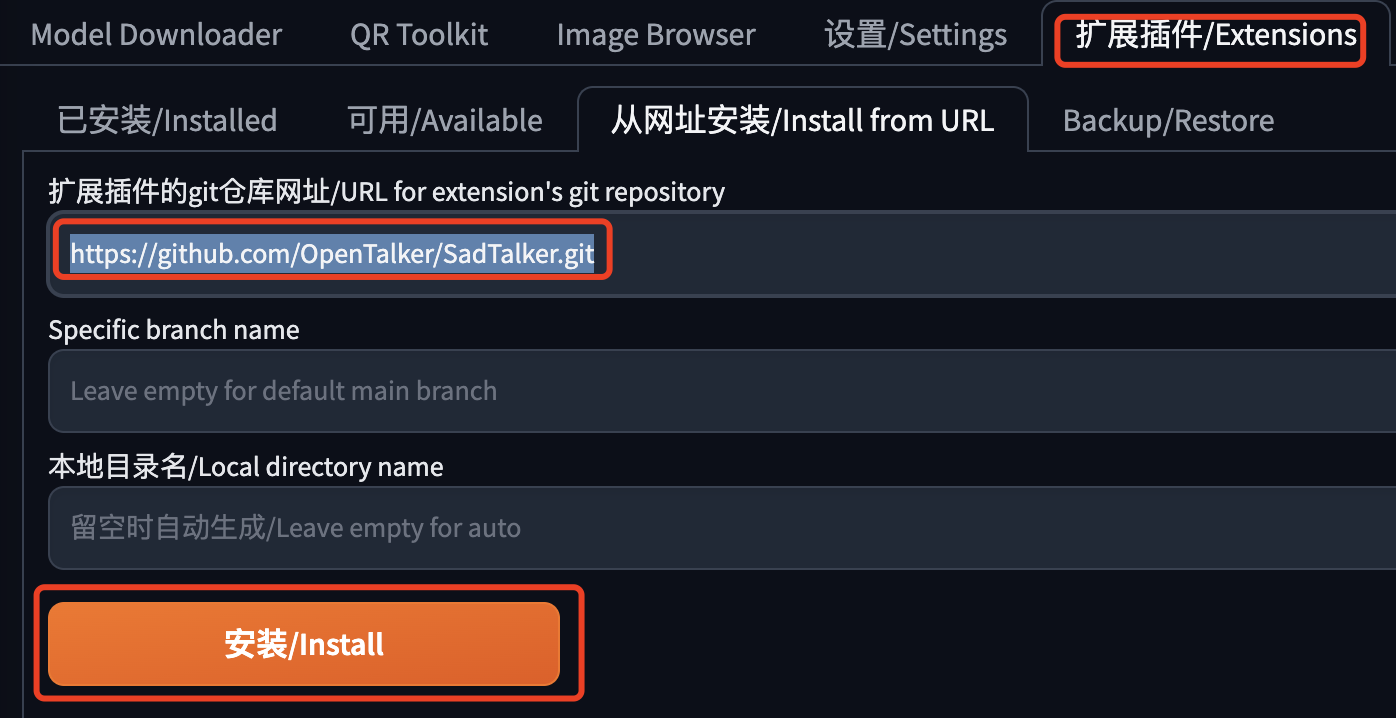
这个插件需要下载的文件很多,有的文件还比较大,请耐心等待。如果不确定是不是出问题了,可以看看控制台输出的内容,有没有错误。
安装完了,不要忘了重启Stable Diffusion,要整个重启,不要只重启WebUI。
安装方法二
适合访问外网不太方便的用户,把这个插件需要的文件通过别的方式提前下载好,比如迅雷下载,只要上传到指定的目录就行了。
- 主程序:
放到 stable-diffusion-webui/extensions/SadTalker
https://github.com/OpenTalker/SadTalker/archive/refs/heads/main.zip
- 视频模型:
放到 stable-diffusion-webui/extensions/SadTalker/checkpoints
https://github.com/OpenTalker/SadTalker/releases/download/v0.0.2-rc/mapping_00109-model.pth.tar
https://github.com/OpenTalker/SadTalker/releases/download/v0.0.2-rc/mapping_00229-model.pth.tar
https://github.com/OpenTalker/SadTalker/releases/download/v0.0.2-rc/SadTalker_V0.0.2_256.safetensors
https://github.com/OpenTalker/SadTalker/releases/download/v0.0.2-rc/SadTalker_V0.0.2_512.safetensors
- 修脸模型:
放到 stable-diffusion-webui/extensions/SadTalker/gfpgan/weights 和 stable-diffusion-webui/models/GFPGAN
https://github.com/xinntao/facexlib/releases/download/v0.1.0/alignment_WFLW_4HG.pth
https://github.com/xinntao/facexlib/releases/download/v0.1.0/detection_Resnet50_Final.pth
https://github.com/TencentARC/GFPGAN/releases/download/v1.3.0/GFPGANv1.4.pth
https://github.com/xinntao/facexlib/releases/download/v0.2.2/parsing_parsenet.pth
为了方便使用这种方式部署,我也把相关的文件做了一个打包,大家不用一个一个下载。关注公众号:萤火遛AI,发消息:数字人,即可获得下载地址。
(1)首先把文件下载到本地或者你的云环境,这里以AutoDL为例,我把它放到 /root 目录中。
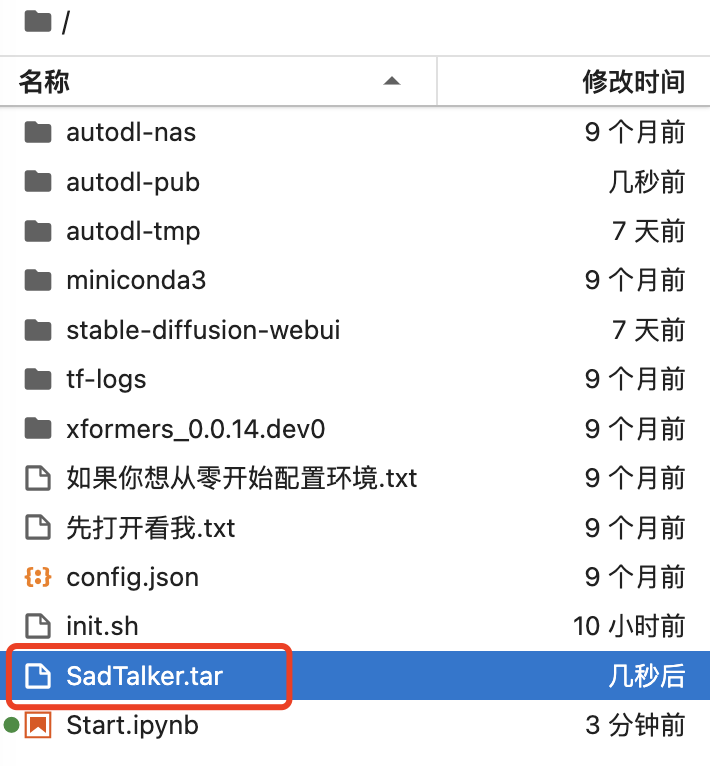
(2)然后解压文件到 stable diffusion webui的扩展目录,并拷贝几个文件到SD模型目录:
tar -xvf /root/SadTalker.tar -C /root/stable-diffusion-webui/extensions
cp -r /root/stable-diffusion-webui/extensions/SadTalker/gfpgan/weights/* /root/stable-diffusion-webui/models/GFPGAN/看到下边的结果,就基本上差不多了。
扩展目录下边有这个文件夹:
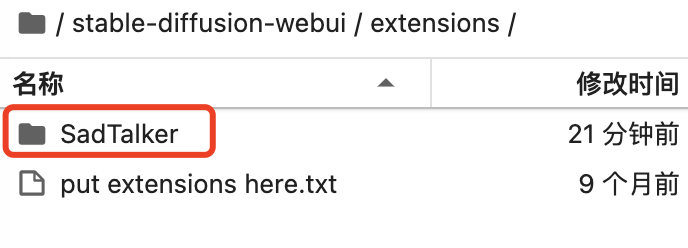
SD models 目录下有这几个文件:
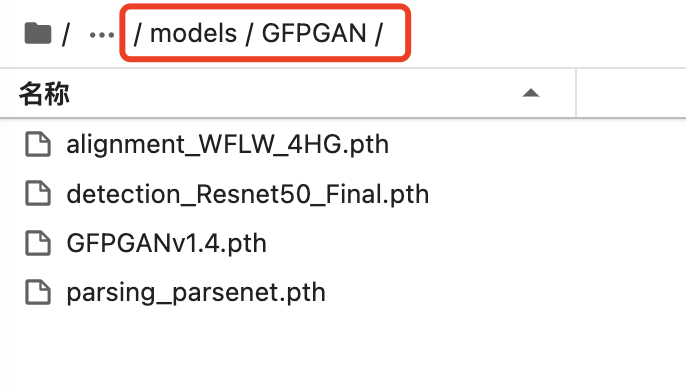
部署完毕,不要忘了重启。
使用方法
在SD WebUI的Tab菜单中找到SadTalker,按照下边的顺序进行设置。
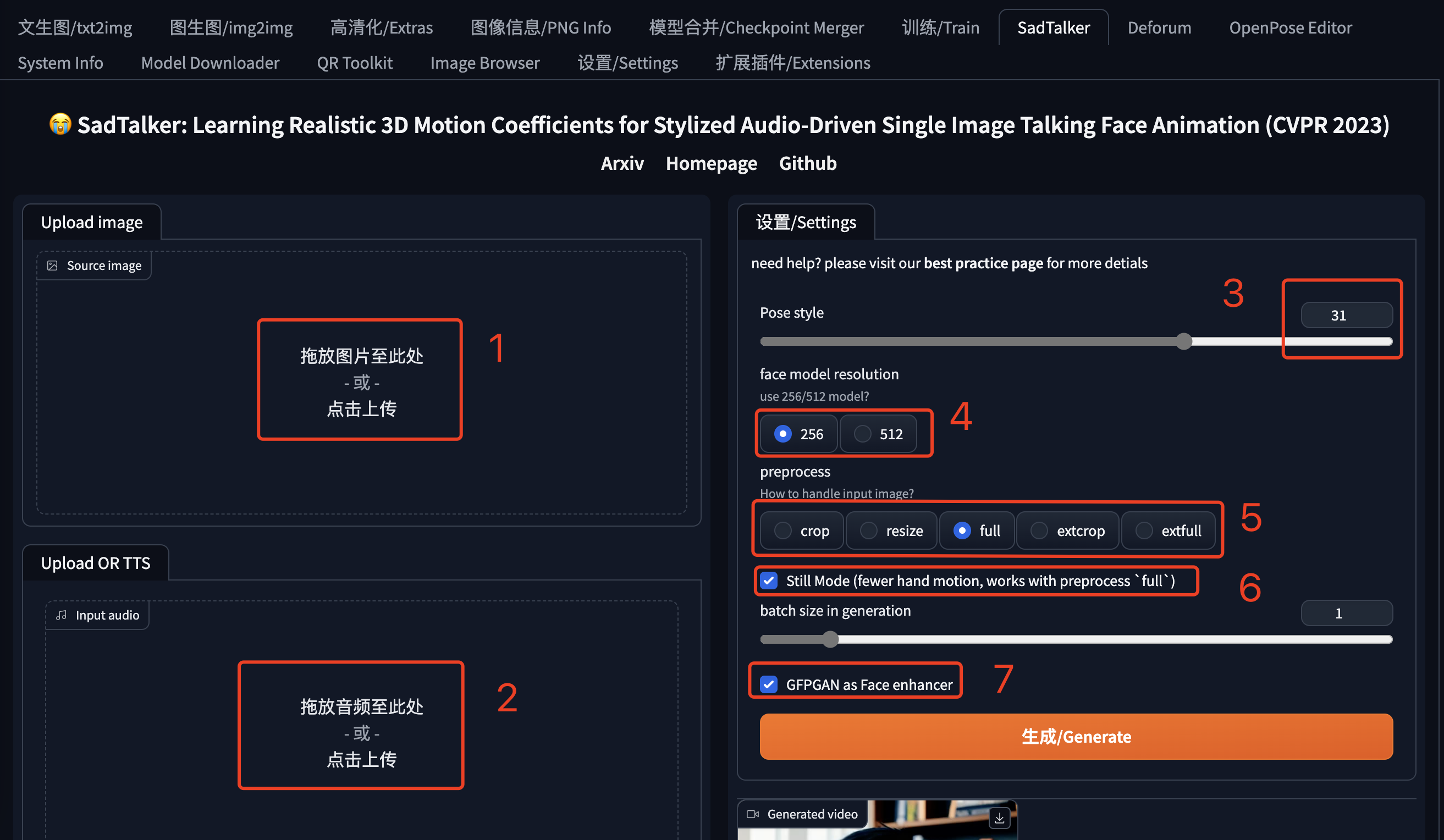
1、上传人物照片。
2、上传语音文件。
3、选择视频人物的姿势:实际就是人说话时头部的动作,个人感觉有点摇头晃脑,可以使用不同的数字看看。
4、分辨率:512的视频分辨率比256大。
5、图片处理方法:corp是从图片截取头部做视频,resize适合大头照或者证件照,full就是全身照做视频,extcorp和extfull没做细致研究,大家自己对比下。
6、Still Model:让头部不要动作太大,以致偏离身体,负面效果是头不怎么动了。
7、GFPGAN:修脸,说话时嘴和眼的动作可能让脸有些变形,选上他让脸部好看一些。
最后点击“生成”,根据硬件的运行速度和你的勾选设置,可能需要几分钟的时间,耐心等待。
我这里生成的视频:
可能遇到的问题
(1) 启动的时候报错:SadTalker will not support download...

这个错误就是模型下载不下来,告诉我们要去手动下载。
这里有两个方法:
- 执行下边的命令触发下载,注意 cd 之后的路径替换成你自己的SadTalker安装路径:
cd stable-diffusion-webui/extensions/SadTalker
chmod 755 scripts/download_models.sh
scripts/download_models.sh- 下载所有的模版,然后手工上传到相关目录,上边安装方法二中已经介绍过,可以使用我打包好的文件包。
(2) 合成视频时报错:No module named 'xxx'
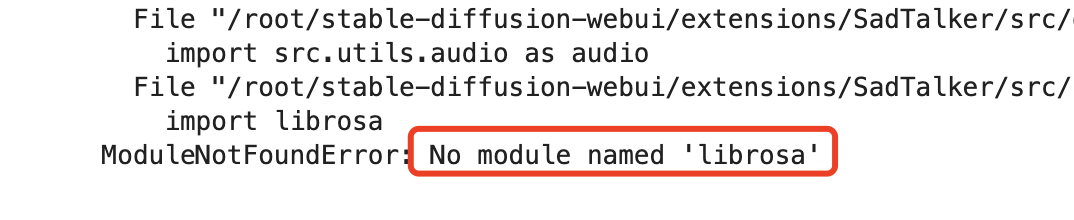
使用 pip install xxx 就可以了,注意如果使用了python虚拟环境,需要先激活它,比如这里要先执行source xxx。
source /root/stable-diffusion-webui/venv/bin/activate
pip install librosa(3)合成视频时报错:No such file or directory: '/tmp/gradio/xxx',创建目录就可以了:
mkdir -p /tmp/gradio(4)如果提示找不到 ffmpeg,我这里没遇到,如果出现请先下载安装:http://ffmpeg.org/download.html
以上就是本文的主要内容了,使用这种方法就可以无限制作自己的AI专属数字人,想要什么样的风格都可以,想做多少个都可以,有兴趣的快去试试吧。当然要遵纪守法,不要搞出事情来。
如果你有任何问题,欢迎与我交流。
使用Stable Diffusion制作AI数字人视频的简明教程的更多相关文章
- 最新版本 Stable Diffusion 开源 AI 绘画工具之汉化篇
目录 汉化预览 下载汉化插件一 下载汉化插件二 下载汉化插件三 开启汉化 汉化预览 在上一篇文章中,我们安装好了 Stable Diffusion 开源 AI 绘画工具 但是整个页面都是英文版的,对于 ...
- 最新版本 Stable Diffusion 开源 AI 绘画工具之使用篇
目录 界面参数 采样器 文生图(txt2img) 图生图(img2img) 模型下载 界面参数 在使用 Stable Diffusion 开源 AI 绘画之前,需要了解一下绘画的界面和一些参数的意义 ...
- 最新版本 Stable Diffusion 开源AI绘画工具之部署篇
目录 AI绘画 本地环境要求 下载 Stable Diffusion 运行启动 AI绘画 关于 AI 绘画最近有多火,既然你有缘能看到这篇文章,那么相信也不需要我过多赘述了吧? 随着 AI 绘画技术的 ...
- 最新版本 Stable Diffusion 开源 AI 绘画工具之图生图进阶篇
目录 图生图基本参数 图生图(img2img) 涂鸦绘制(Sketch) 局部绘制(Inpaint) 涂鸦蒙版(Inpaint sketch) 上传蒙版(Inpaint upload) 图生图基本参数 ...
- 最新版本 Stable Diffusion 开源 AI 绘画工具之中文自动提词篇
目录 标签生成器 提示词自动补全 标签生成器 由于输入正向提示词 prompt 和反向提示词 negative prompt 都是使用英文,所以对学习母语的我们非常不友好 使用网址:https://t ...
- 基于Docker安装的Stable Diffusion使用CPU进行AI绘画
基于Docker安装的Stable Diffusion使用CPU进行AI绘画 由于博主的电脑是为了敲代码考虑买的,所以专门买的高U低显,i9配核显,用Stable Diffusion进行AI绘画的话倒 ...
- AI绘画提示词创作指南:DALL·E 2、Midjourney和 Stable Diffusion最全大比拼 ⛵
作者:韩信子@ShowMeAI 深度学习实战系列:https://www.showmeai.tech/tutorials/42 自然语言处理实战系列:https://www.showmeai.tech ...
- AI 绘画咒语入门 - Stable Diffusion Prompt 语法指南 【成为初级魔导士吧!】
要用好 Stable Diffusion,最最重要的就是掌握 Prompt(提示词).由于提示词对于生成图的影响甚大,所以被称为魔法,用得好惊天动地,用不好魂飞魄散 . 因此本篇整理下提示词的语法(魔 ...
- Python制作AI贪吃蛇,很多很多细节、思路都写下来了!
前提:本文实现AI贪吃蛇自行对战,加上人机对战,读者可再次基础上自行添加电脑VS电脑和玩家VS玩家(其实把人机对战写完,这2个都没什么了,思路都一样) 实现效果: 很多人学习python,不知道从何学 ...
- 乘风破浪,遇见未来元宇宙(Metaverse)之进入元宇宙世界,虚拟数字人行业洞察报告
正值元宇宙热潮,虚拟数字人兴起 作为⼀个新兴领域,虚拟数字⼈已经引起市场和资本的⾼度关注,截⾄目前据不完全统计,全球范围已有500+虚拟数字人相关项目获得融资,融资总额超10亿美元,并且融资项目和总额 ...
随机推荐
- CSS实现段落首行缩进两个字符
段落前面空两个字的距离,不要再使用空格了,对于文字,需要使用4个 才会显示汉字2个字符空格的效果. 用CSS实现段落首缩进两个字符,应该使用首行缩进text-indent.text-indent可以使 ...
- Linux云计算运维工程师day28shell编程基础
一. 1.全局变量.环境变量 Export OLDOBY="I am a oldboy." Echo OLDOBY OLDOBY="I am a oldboy.&quo ...
- Node工程的依赖包管理方式
作者:京东零售 陈震 在前端工程化中,JavaScript 依赖包管理是非常重要的一环.依赖包通常是项目所依赖的第三方库.工具和框架等资源,它们能够帮助我们减少重复开发.提高效率并且确保项目可以正确的 ...
- Protobuf编码规则
支持类型 该表显示了在 .proto 文件中指定的类型,以及自动生成的类中的相应类型: .proto Type Notes C++ Type Java/Kotlin Type[1] Java/Kotl ...
- Azure DevOps(三)Azure Pipeline 自动化将程序包上传到 Azure Bolb Storage
一,引言 结合前几篇文章,我们了解到 Azure Pipeline 完美的解决了持续集成,自动编译.同时也兼顾了 Sonarqube 作为代码扫描工具.接下来另外一个问题出现了,Azure DevOp ...
- 【自用】无限级分类获取SQL语句
自定义函数: 1 USE [ExpenseCenter_Fibrogen] 2 GO 3 /****** Object: UserDefinedFunction [dbo].[GetSubordina ...
- Django transaction.atomic 事务的使用
函数 transaction.atomic 数据库的读写操作中,事务在保证数据的安全性和一致性方面起着关键的作用,而回滚正是这里面的核心操作. 遇到并发的时候常常会因为接口的访问顺序或者其他情况,导致 ...
- [OS/Linux] Linux核心参数:net.core.somaxconn(高并发场景核心参数)
0 序言 近期工作在搞压力测试,我负责开发维护的.基于sring-cloud-gateway的大数据网关微服务,其底层是基于spring-webflux-->reactor-netty--> ...
- 2023-01-13:joxit/docker-registry-ui是registry的web界面工具之一。请问部署在k3s中,yaml如何写?
2023-01-13:joxit/docker-registry-ui是registry的web界面工具之一.请问部署在k3s中,yaml如何写? 答案2023-01-13: yaml如下: apiV ...
- 2021-07-18:最高的广告牌。你正在安装一个广告牌,并希望它高度最大。这块广告牌将有两个钢制支架,两边各一个。每个钢支架的高度必须相等。你有一堆可以焊接在一起的钢筋 rods。举个例子,如果钢筋
2021-07-18:最高的广告牌.你正在安装一个广告牌,并希望它高度最大.这块广告牌将有两个钢制支架,两边各一个.每个钢支架的高度必须相等.你有一堆可以焊接在一起的钢筋 rods.举个例子,如果钢筋 ...