Pytorch分布式训练,其他GPU进程占用GPU0的原因
问题
最近跑师兄21年的论文代码,代码里使用了Pytorch分布式训练,在单机8卡的情况下,运行代码,出现如下问题。
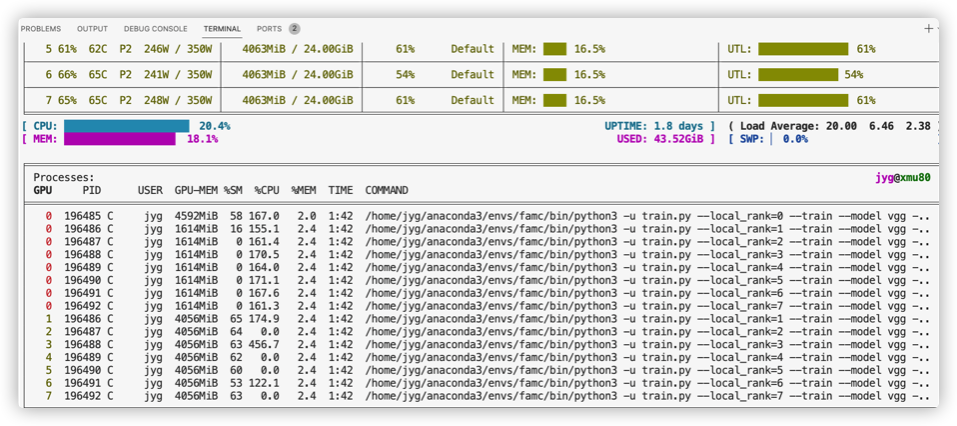
也就是说GPU(1..7)上的进程占用了GPU0,这导致GPU0占的显存太多,以至于我的batchsize不能和原论文保持一致。
解决方法
我一点一点进行debug。
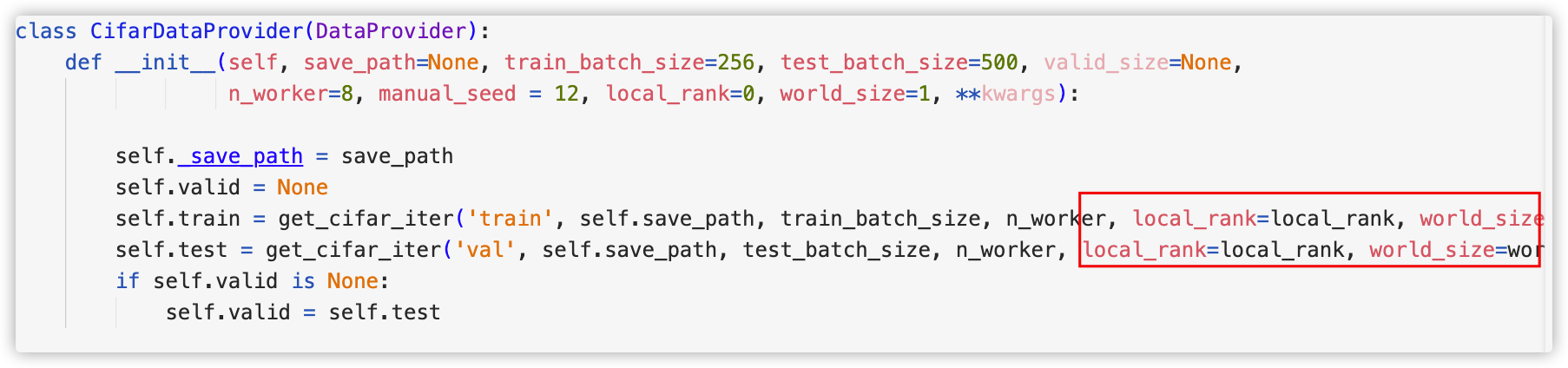
首先,在数据加载部分,由于没有将local_rank和world_size传入get_cifar_iter函数,导致后续使用DALI创建pipeline时使用了默认的local_rank=0,因此会在GPU0上多出该GPU下的进程
其次,在使用torch.load加载模型权重时,没有设置map_location,于是会默认加载到GPU0上,下图我选择将模型权重加载到cpu。虽然,这会使训练速度变慢,但为了和论文的batchsize保持一致也不得不这样做了。-.-

参考文献
Pytorch分布式训练,其他GPU进程占用GPU0的原因的更多相关文章
- [源码解析] PyTorch 分布式(7) ----- DistributedDataParallel 之进程组
[源码解析] PyTorch 分布式(7) ----- DistributedDataParallel 之进程组 目录 [源码解析] PyTorch 分布式(7) ----- DistributedD ...
- Pytorch分布式训练
用单机单卡训练模型的时代已经过去,单机多卡已经成为主流配置.如何最大化发挥多卡的作用呢?本文介绍Pytorch中的DistributedDataParallel方法. 1. DataParallel ...
- [源码解析] PyTorch 分布式之弹性训练(1) --- 总体思路
[源码解析] PyTorch 分布式之弹性训练(1) --- 总体思路 目录 [源码解析] PyTorch 分布式之弹性训练(1) --- 总体思路 0x00 摘要 0x01 痛点 0x02 难点 0 ...
- windows下使用pytorch进行单机多卡分布式训练
现在有四张卡,但是部署在windows10系统上,想尝试下在windows上使用单机多卡进行分布式训练,网上找了一圈硬是没找到相关的文章.以下是踩坑过程. 首先,pytorch的版本必须是大于1.7, ...
- [源码解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化
[源码解析] PyTorch 分布式(9) ----- DistributedDataParallel 之初始化 目录 [源码解析] PyTorch 分布式(9) ----- DistributedD ...
- [源码解析] PyTorch分布式优化器(2)----数据并行优化器
[源码解析] PyTorch分布式优化器(2)----数据并行优化器 目录 [源码解析] PyTorch分布式优化器(2)----数据并行优化器 0x00 摘要 0x01 前文回顾 0x02 DP 之 ...
- [源码解析] 深度学习分布式训练框架 Horovod (1) --- 基础知识
[源码解析] 深度学习分布式训练框架 Horovod --- (1) 基础知识 目录 [源码解析] 深度学习分布式训练框架 Horovod --- (1) 基础知识 0x00 摘要 0x01 分布式并 ...
- [源码解析] 深度学习分布式训练框架 horovod (2) --- 从使用者角度切入
[源码解析] 深度学习分布式训练框架 horovod (2) --- 从使用者角度切入 目录 [源码解析] 深度学习分布式训练框架 horovod (2) --- 从使用者角度切入 0x00 摘要 0 ...
- [源码解析] 深度学习分布式训练框架 horovod (5) --- 融合框架
[源码解析] 深度学习分布式训练框架 horovod (5) --- 融合框架 目录 [源码解析] 深度学习分布式训练框架 horovod (5) --- 融合框架 0x00 摘要 0x01 架构图 ...
- [源码解析] 深度学习分布式训练框架 horovod (6) --- 后台线程架构
[源码解析] 深度学习分布式训练框架 horovod (6) --- 后台线程架构 目录 [源码解析] 深度学习分布式训练框架 horovod (6) --- 后台线程架构 0x00 摘要 0x01 ...
随机推荐
- Buffer 缓冲区操作
1.缓冲区分片在 NIO 中,除了可以分配或者包装一个缓冲区对象外,还可以根据现有的缓冲区对象来创建一个子缓冲区,即在现有缓冲区上切出一片来作为一个新的缓冲区,但现有的缓冲区与创建的子缓冲区在底层数组 ...
- 基于Kresling折纸结构双稳态空间的无人机着陆系统新结构
摘要:本文利用动捕技术对无人机着陆系统模型进行动力学分析,对折纸结构双稳态着陆系统性能进行测试,为无人机着陆系统结构设计提供创新方法. 近期,一篇关于无人机着陆系统的研究论文"Evoluti ...
- Python数据预处理:彻底理解标准化和归一化
数据预处理 数据中不同特征的量纲可能不一致,数值间的差别可能很大,不进行处理可能会影响到数据分析的结果,因此,需要对数据按照一定比例进行缩放,使之落在一个特定的区域,便于进行综合分析. 常用的方法有两 ...
- 【Docker】docker介绍 什么是虚拟化 容器与虚拟机比较 Docker 概念 docker安装
目录 docker介绍 什么是虚拟化 docker是什么 容器与虚拟机比较 Docker 概念 docker安装 docker介绍 什么是虚拟化 在计算机中,虚拟化(英语:Virtualization ...
- vue-echarts之折线图以及双Y轴折线,柱状混合图,部分属性记录
https://blog.csdn.net/qq_41139348/article/details/106870005 https://segmentfault.com/a/1190000021898 ...
- JS上下文和作用域链
开发中我们可能会不小心将写多个相同名称的变量,也经常会写一个递归调用的方法, 上述示例中程序执行顺序如下图,程序会按照顺序执行第一个子元素内部所有的程序,当最底层执行结束后,会逐渐抛出返回值,然后执行 ...
- C#排序算法3:插入排序
插入排序是一种最简单的排序方法,它的基本思想是将一个记录插入到已经排好序的有序表中,从而一个新的.记录数增1的有序表. 原理: ⒈ 从第一个元素开始,该元素可以认为已经被排序 ⒉ 取出下一个元素,在已 ...
- Bash 常用命令总结
基础常用命令 某个命令 --h,对这个命令进行解释 某个命令 --help,解释这个命令(更详细) man某个命令,文档式解释这个命令(更更详细)(执行该命令后,还可以按/+关键字进行查询结果的搜索) ...
- 小白学标准库之反射 reflect
1. 反射简介 反射是 元编程 概念下的一种形式,它在运行时操作不同类型的对象,检查对象的类型,大小等信息,对于没有源代码的包反射尤其有用. 设想一个场景,读取一个包中变量 a 的类型,并打印该类型的 ...
- CentOS下PHP7安装mysqlnd模块
单独安装mysqlnd驱动 如果是centos下的yum安装方式,那么可以参考后续操作. 因为mysqlnd是mysql原生的驱动,如果已经安装了php-mysql,则需要先卸载,否则会遇到冲突. 先 ...