【Treatment-Rec 论文阅读】Data-driven Automatic Treatment Regimen Development and Recommendation
Data-driven Automatic Treatment Regimen Development and Recommendation
Authors: Leilei Sun, Chuanren Liu, Chonghui Guo, Hui Xiong, Yanming Xie
Keywords: Treatment Regimen; Treatment Recommendation, Electronic Medical Records; Temporal Sets.
KDD’16 大连理工大学 (Dalian University of Technology),卓克索大学 (Drexel University),中国中医科学院 (China Academy of China Medical Sciences)
论文链接:https://dl.acm.org/doi/pdf/10.1145/2939672.2939866
0. 总结
本文方法比较清晰,专注于脑梗塞这一种疾病,给新进入系统的病人推荐治疗方案。但假设比较强,是治疗方案推荐的很好的初步尝试。
数据是在中国收集的,不知道相关数据集和代码是否已经公开?
1.研究目标
根据历史病历数据,对患者和治疗方案分别进行分类,并提取出一些典型的治疗方案。对新患者,根据患者基本信息和诊断信息,推荐相应的治疗方案,辅助医疗决策,提高治愈率和治疗有效性。
2.问题背景
电子病历信息没有被充分利用,医疗资源分布不均,大数据手段可以提高医疗效率,提高整体医疗水平。
3. 问题定义-EMR 的内容
本文用到的电子医疗记录(Electronic Medical Records, EMRs)主要包含以下五种信息:
3.1 人口统计信息 Demographic Information
包含患者的基本信息,如性别、年龄、家庭住址、种族、受教育程度等信息。
3.2 诊断信息 Diagnostic Information
包含疾病名称和严重程度
3.3 医嘱 Doctor Order
包含药物名称、使用方式、剂量、频率、开始日期和结束日期。
3.4 治疗方案 Treatment
治疗方案是在医嘱之上整理出来的,记录患者每天接受了哪些治疗。
进一步,可以将患者的病程分为几个阶段,每个阶段都有几个治疗方案,其中记录了患者接受了哪些治疗,分别接受了几次(这里就不记录这几次治疗具体发生的日期,而是只记录次数)。
3.5 结果 Outcome
结果指患者出院时医生对患者的状态评估,可以分为“治愈(cured)“,“改善(improved)”,“无效(ineffective)”,“死亡(dead)”。
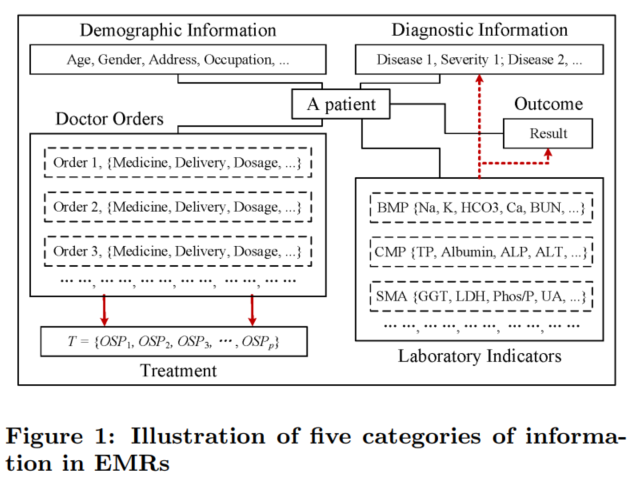
上面五种信息中,前两个(基本信息和诊断信息)可以视为条件,第四个(治疗方案)可以视为干预变量,最后一个(结果)可以视为目标。
4. 方法
4.1 治疗方案相似度度量
总体思路:每个患者的治疗方案可以被分为多个阶段的治疗方案,每个阶段的治疗方案包含用了哪些药物,以及服用方式、剂量和使用次数。在相似度度量时,首先度量各个对应阶段之间的相似度(如果阶段数量不一样怎么办?),然后再整合得到整体相似度。
- 治疗方案相似度首先被拆分为药物之间的相似度——相同名称的药物会有非零相似度,再根据服用方式、剂量和频率来计算一个0到1之间的相似度数值。
- 两个分阶段治疗方案之间的相似度变为两个集合之间的相似度度量,其中集合元素之间的相似度已知。
- 本文提出一种矩阵,将元素之间的相似度加权组合为集合之间的相似度。
- 得到各个阶段治疗方案的相似度之后,再加权平均得到两个治疗方案的整体相似度
4.2 治疗方案聚类
基于治疗方案之间的相似度,本文提出一种基于密度峰值的聚类算法,可以得到治疗方案的聚类中心。
4.3 提取典型治疗方案
由于本场景的特殊性,聚类中心的治疗方案也无法完全代表这类每个类别,仍需进一步处理。
具体来说,就是看一下哪些药物用的比较多,再提取一下典型的使用剂量、使用方式和持续时间等信息。
4.4 治疗方案推荐
对病人也进行分类(决策树),每个叶子节点认为是一个类型的患者,然后看一下这些患者使用哪个典型治疗方案比较多,就作为这个叶子节点的推荐方案。
5. 实验
5.1 数据
数据来自中国14家三甲医院,分布在北京,石家庄,深圳,济南,长春,福州和西安。
实验专注于脑梗塞的药物推荐。
收集了2.7万的患者数据,医嘱数量100万。
5.2 提取典型治疗方案
其中使用了1090种药物,但大多数药物都是用于治疗其他疾病的。本文选取了138种最相关的药物,有36万医嘱包含这些药物,平均每个患者13个。
治疗过程分为四个阶段:前24小时、2-3天、4-7天、8-14天。
最终提取出四种典型的治疗方案
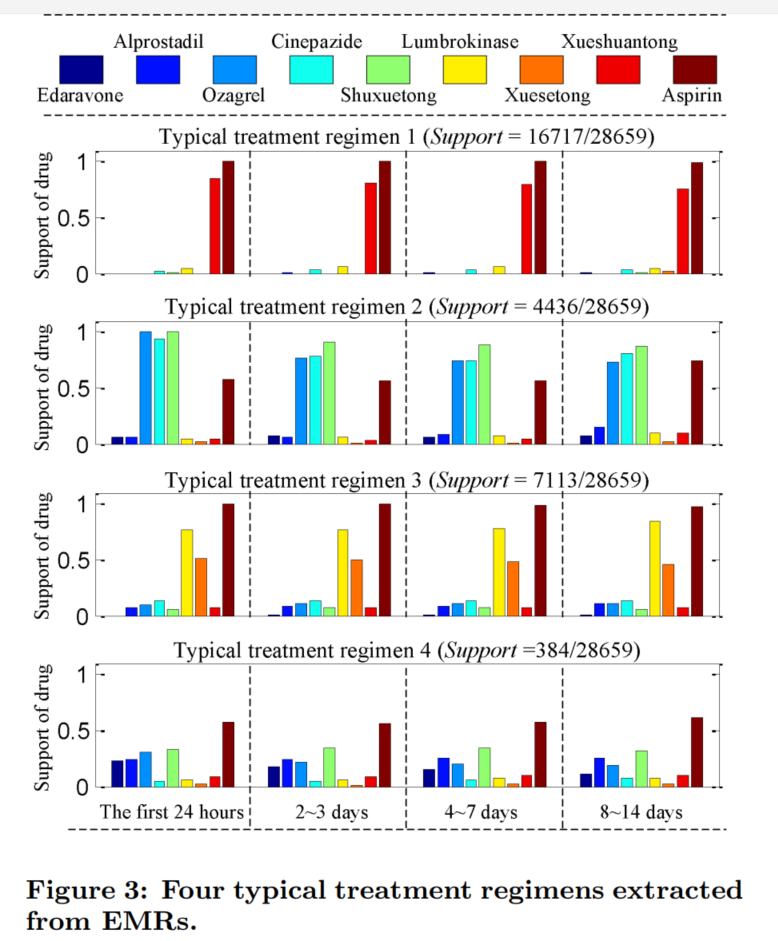
5.3 治疗方案推荐
对病人进行分类,分了17个类别。每个类别找一个治疗效果最好的(不一定是使用最多的)作为推荐结果。
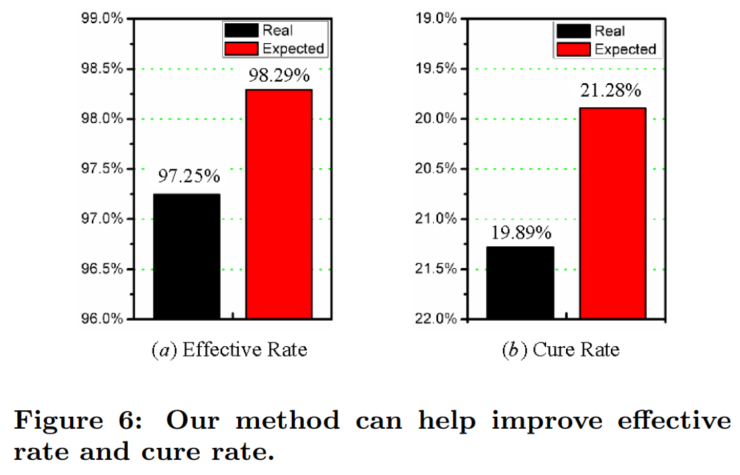
5.4 推荐效果评估
由于每个类别都找到了统计上治疗效果最好的治疗方案,假设这些治疗方案推广到这个类别上的所有患者,再假设推广到其他患者身上之后仍然有这么好的治疗效果,计算一下推广之后,总体的治疗有效率和治愈率能提升多少。
【Treatment-Rec 论文阅读】Data-driven Automatic Treatment Regimen Development and Recommendation的更多相关文章
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- 【医学图像】3D Deep Leaky Noisy-or Network 论文阅读(转)
文章来源:https://blog.csdn.net/u013058162/article/details/80470426 3D Deep Leaky Noisy-or Network 论文阅读 原 ...
- Event StoryLine Corpus 论文阅读
Event StoryLine Corpus 论文阅读 本文是对 Caselli T, Vossen P. The event storyline corpus: A new benchmark fo ...
- Nature/Science 论文阅读笔记
Nature/Science 论文阅读笔记 Unsupervised word embeddings capture latent knowledge from materials science l ...
- YOLO 论文阅读
YOLO(You Only Look Once)是一个流行的目标检测方法,和Faster RCNN等state of the art方法比起来,主打检测速度快.截止到目前为止(2017年2月初),YO ...
- [论文阅读]阿里DIN深度兴趣网络之总体解读
[论文阅读]阿里DIN深度兴趣网络之总体解读 目录 [论文阅读]阿里DIN深度兴趣网络之总体解读 0x00 摘要 0x01 论文概要 1.1 概括 1.2 文章信息 1.3 核心观点 1.4 名词解释 ...
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- [论文阅读笔记] node2vec Scalable Feature Learning for Networks
[论文阅读笔记] node2vec:Scalable Feature Learning for Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问题 由于DeepWal ...
随机推荐
- nvidia 机器人仿真环境Isaac Sim
- 大语言模型(LLM)运行报错:module ‘streamlit‘ has no attribute ‘chat_message‘
参考: https://blog.csdn.net/weixin_45748921/article/details/134645308 问题在于版本不匹配,深究一下为什么各个版本软件不匹配,发现原因是 ...
- (计算机类)人工智能方向会议的截止时间表 —— AI Conference Deadlines —— 会议投稿截止时间
由 https://paperswithcode.com/ 提供的时间表. 做AI方向的research,经常需要关注的就是conference的deadline,之前往往都是需要手动的去挨个搜索,下 ...
- 朋友吐槽我为什么这么傻不在源生成器中用string.GetHashCode, 而要用一个不够优化的hash方法
明明有更好的hash方法 有位朋友对我吐槽前几天我列举的在源生成器的生成db映射实体的优化点 提前生成部分 hashcode 进行比较 所示代码 public static void Generate ...
- rk3568 | 瑞芯微平台GPIO引脚驱动编写
最近在玩瑞芯微平台的产品,移植了几个设备的驱动,遇到了一些问题,总结后发现大部分问题都出在了GPIO配置的问题上,写下本篇文章,用来分享一下调试的心得. 有喜欢瑞芯微的朋友,可以加我好友,拉你进群,一 ...
- 【测试平台开发】——06Flask后端api开发实战(三)——API接口关联数据库
本章节演示如何创建接口服务,用接口关联数据库数据,包括get请求和post请求. 一.Flask-RESTful插件 restful api是用于在前端与后台进行通信的一套规范.使用这个规范可以让前后 ...
- 通过 maven 命令来查看 jar 包的引用关系
通过 maven 命令来查看 jar 包的引用关系 1.可以通过maven命令来查看jar包的引用关系 mvn dependency:tree -Dverbose -Dincludes=org.cod ...
- 鸿蒙(HarmonyOS)实现隐私政策弹窗
在实现用户协议弹窗时,通常我们会想到使用系统自定义弹窗,并在弹窗中点击跳转到Web页面.但在HarmonyOS中,由于系统弹窗的显示优先级高于其他组件,即使跳转到Web页面,弹窗依然会显示在最上层. ...
- A4纸尺寸
A4纸尺寸 A4纸尺寸:210×297: A3纸尺寸:297×420: A2纸尺寸:420×594: A1纸尺寸:594×841: A0纸尺寸:841×1189: 备注:长(mm)×宽(mm) 单位: ...
- Go runtime 调度器精讲(四):运行 main goroutine
原创文章,欢迎转载,转载请注明出处,谢谢. 0. 前言 皇天不负有心人,终于我们到了运行 main goroutine 环节了.让我们走起来,看看一个 goroutine 到底是怎么运行的. 1. 运 ...