Linux下的物理CPU和逻辑CPU
1、物理CPU
(1)物理CPU是指:机器中插槽上的实际CPU个数。
(2)物理CPU的数量:可以通过不重复的physical id来查询。
(3)命令:
cat /proc/cpuinfo | grep "physical id" | sort | uniq | wc -l
2、每个物理CPU上的核数
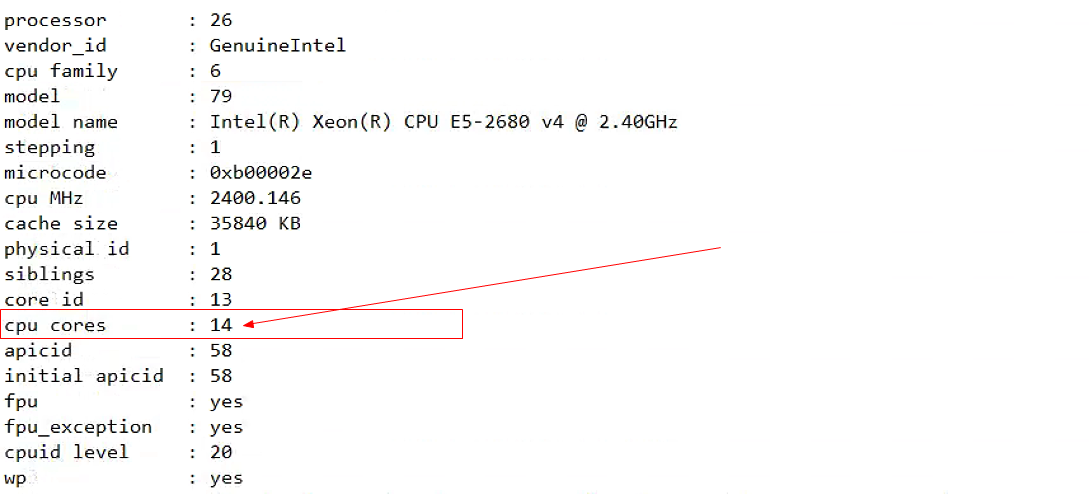
cat /proc/cpuinfo |grep "processor"|wc -l #processor从0开始,表示逻辑CPU
(3)通过对比cpu cores和siblings参数可以看出来,此机器开了HT技术,slibings是cpu cors的2倍,因此逻辑CPU个数=物理CPU的个数 × 每颗物理CPU上的核数 x 2

Linux下的物理CPU和逻辑CPU的更多相关文章
- linux下查看物理CPU个数、核数、逻辑CPU个数
cat /proc/cpuinfo中的信息 processor 逻辑处理器的id.physical id 物理封装的处理器的id.core id 每个核心的id.cpu cores 位于相同物理封装的 ...
- CPU | 物理 CPU vs 逻辑 CPU vs 核心 vs 线程 vs Socket
当我们试着通过 Linux 命令 nproc 和 lscpu 了解一台计算机 CPU 级的架构和性能时,我们总会发现无法正确地理解相应的结果,因为我们会被好几个术语搞混淆:物理 CPU.逻辑 CPU. ...
- 物理cpu与逻辑cpu概述
物理cpu与逻辑cpu概述(本博客属于转载部分内容:主要学习目的用于大数据平台Hadoop之yarn资源调度的配置) 一.yarn资源调度器中主要的资源分类 1.memory(内存) 2. ...
- Linux下区分物理CPU、逻辑CPU和CPU核数
㈠ 概念 ① 物理CPU 实际Server中插槽上的CPU个数 物理cpu数量,可以数不重复的 p ...
- 转://Linux下区分物理CPU、逻辑CPU和CPU核数
㈠ 概念 ① 物理CPU 实际Server中插槽上的CPU个数 物理cpu数量,可以数不重复的 p ...
- linux判断物理CPU,逻辑CPU和CPU核数
① 物理CPU 实际Server中插槽上的CPU个数 物理cpu数量,可以数不重复的 physical id 有几个 ② 逻辑CPU Linux用户对 /proc/cpuinfo 这个文件肯定不陌生. ...
- 物理CPU,物理核,逻辑CPU,虚拟CPU(vCPU)区别 (转)
在做虚拟化时候,遇到划分CPU的问题,因此考虑到CPU不知道具体怎么划分,查询一些资料后就写成本文. a. 物理CPU:物理CPU是相对于虚拟CPU而言的概念,指实际存在的处理器,就是我们可以看的见, ...
- linux下查看内存频率,内核函数,cpu频率
查看CPU: cat /proc/cpuinfo # 总核数 = 物理CPU个数 X 每颗物理CPU的核数 # 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数 # 查看物理 ...
- 物理cpu和逻辑cpu
1 物理cpu 插槽里面实际插入的cpu的个数. 通过不重复的physical id可以获取实际的物理cpu的个数. 2 逻辑cpu cat /proc/info processor 1 proces ...
- Linux下查看哪些进程占用的CPU、内存资源
1.CPU占用最多的前10个进程: ps auxw|head -1;ps auxw|sort -rn -k3|head -10 2.内存消耗最多的前10个进程 ps auxw|head -1;ps a ...
随机推荐
- Mogdb - 安装报错Failed to encrypt the password for databaseError
Mogdb - 安装报错 Failed to encrypt the password for databaseError 本文出处:https://www.modb.pro/db/418363 版本 ...
- 【译】宣布在 Visual Studio 17.10 预览2中为 ARM64 架构提供 SSDT
我们很高兴地宣布在 ARM64 中为 Visual Studio 推出 SQL Server Data Tools(SSDT).这个增强是在令人兴奋的17.10预览版2中发布的.arm64 上 Vis ...
- sql 语句系列(计算的进阶)[八百章之第十六章]
前言 介绍两个实用的sql查询语句. 1.计算平均数时候,去除最大值和最小值. 2.修改累计值. 计算平均数时候,去除最大值和最小值 sql server: select AVG(sal) from( ...
- 重新整理 mysql 基础篇————— 索引模型[五]
前言 简单整理一下索引模型. 正文 对我们开发人员来说,索引感觉非常的重要. 因为索引好用,但是不能多建,因为这影响插入,不能少建,因为这影响读取. 有些为了能够多建索引,通过从多个从库中读取数据,再 ...
- ElasticSearch 7.7 + Kibana的部署
ElasticSearch目前最新版是7.7.0,其中部署的细节和之前的6.x有很多的不同,所以这里单独拉出来写一下,希望对用7.x的童鞋有一些帮助,然后部署完ES后配套的kibana也是7.7.0, ...
- textfsm 案例分享
由于安全需要,需要定期对接入层交换机配置进行合规检查,避免不规范配置存在的漏洞给公司网络带来安全风险. 如下案例是通过textfsm 提取交换机接口的配置信息,进一步进行检查准入配置是否开启: 1.首 ...
- PolarDB-X 源码解读系列:DML 之 INSERT IGNORE 流程
简介: 本文将进一步介绍 PolarDB-X 中 INSERT IGNORE 的执行流程,其根据插入的表是否有 GSI 也有所变化. 作者:潜璟 在上一篇源码阅读中,我们介绍了 INSERT 的执行流 ...
- 一不小心,它成为了 GitHub Alibaba Group 下 Star 最多的开源项目
简介: 随着微服务的流行,应用更加轻量和高效,但是带来的困境是线上问题排查越来越复杂困难.传统的 Java 排查问题,需要重启应用再进行调试,但是重启应用之后现场会丢失,问题难以复现. 来源 | 阿里 ...
- 阿里云RDS深度定制-XA Crash Safe
简介: 近几年,随着分布式数据库系统的兴起,特别是基于MySQL分布式数据库系统,会用到XA来保证全局事务的一致性.众所周知,MySQL对XA事务的支持是比较弱的,存在很多问题.为了满足分布式数据库 ...
- PyFlink 开发环境利器:Zeppelin Notebook
简介: 在 Zeppelin notebook 里利用 Conda 来创建 Python env 自动部署到 Yarn 集群中. PyFlink 作为 Flink 的 Python 语言入口,其 Py ...