【大语言模型基础】-详解Transformer原理
一、Transformer
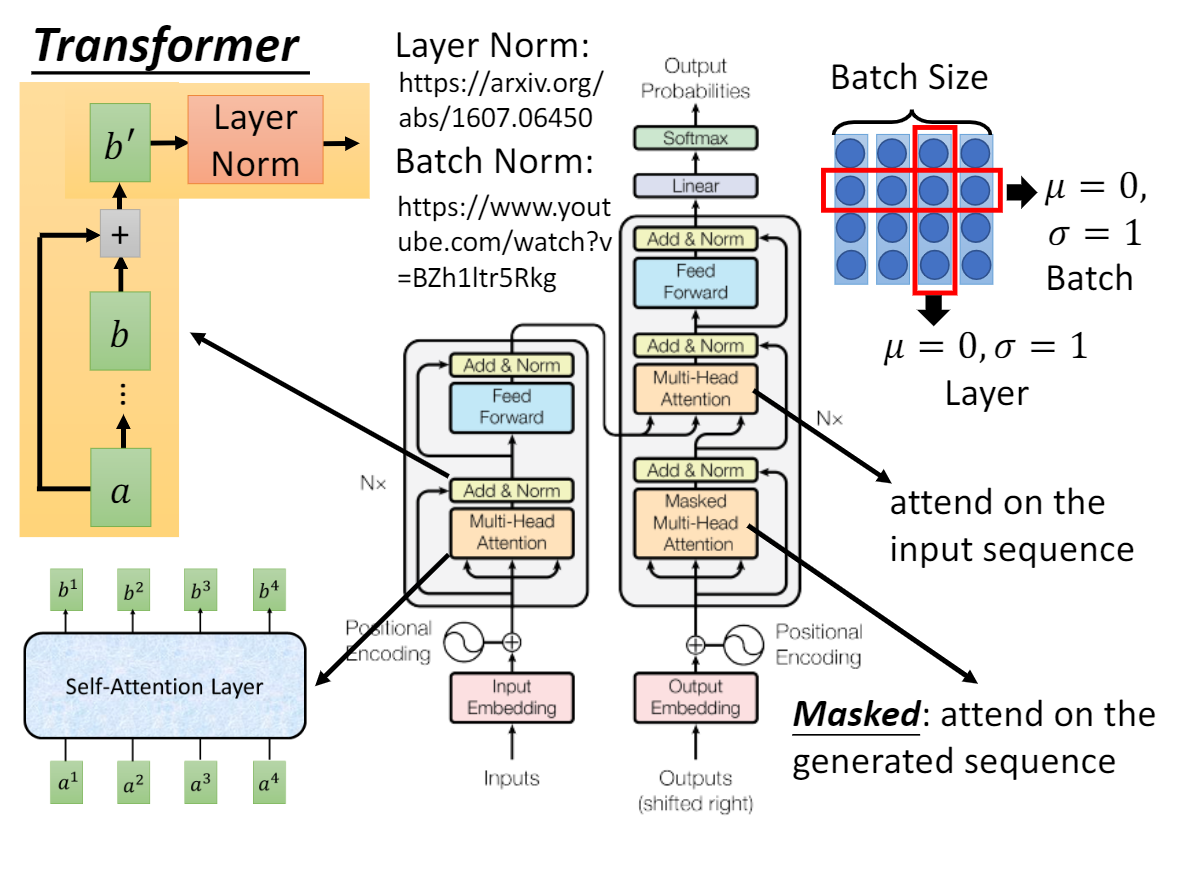
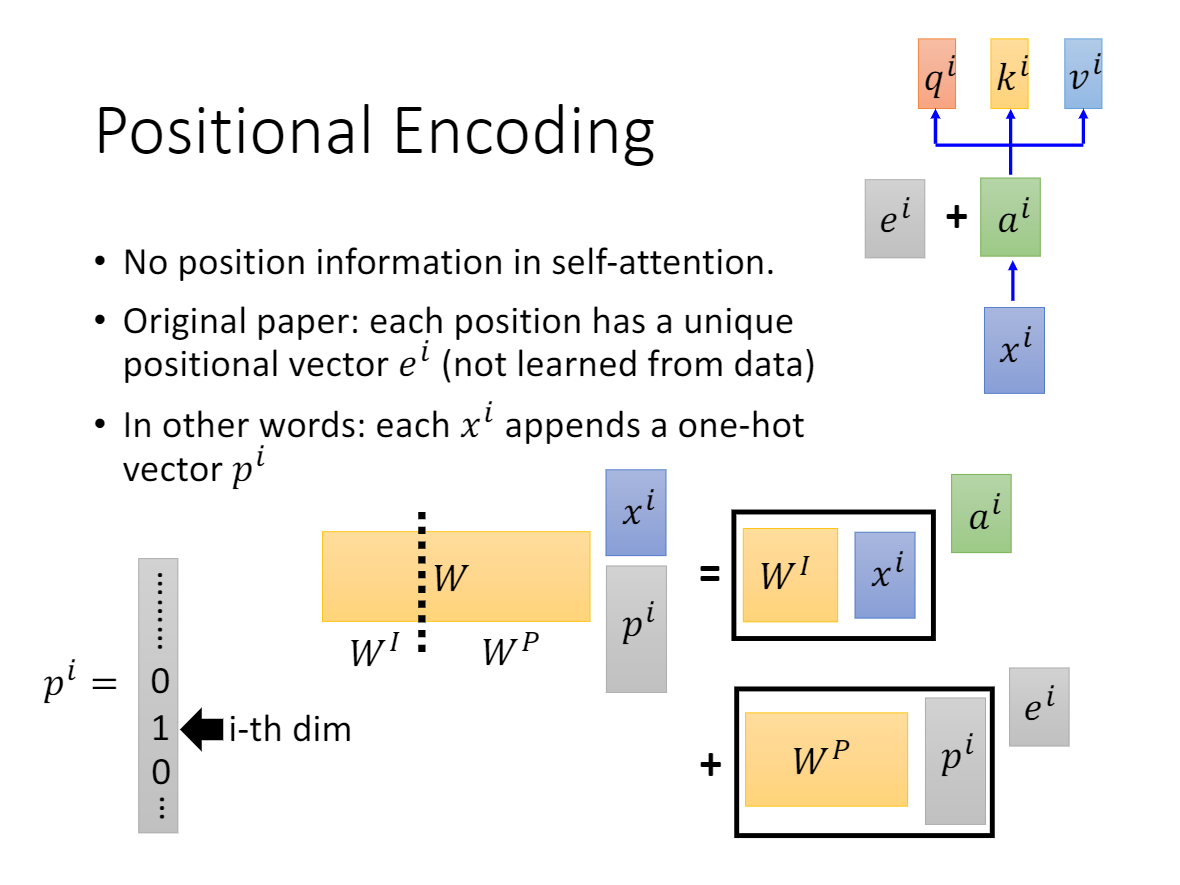
1.1 自注意力
分解式
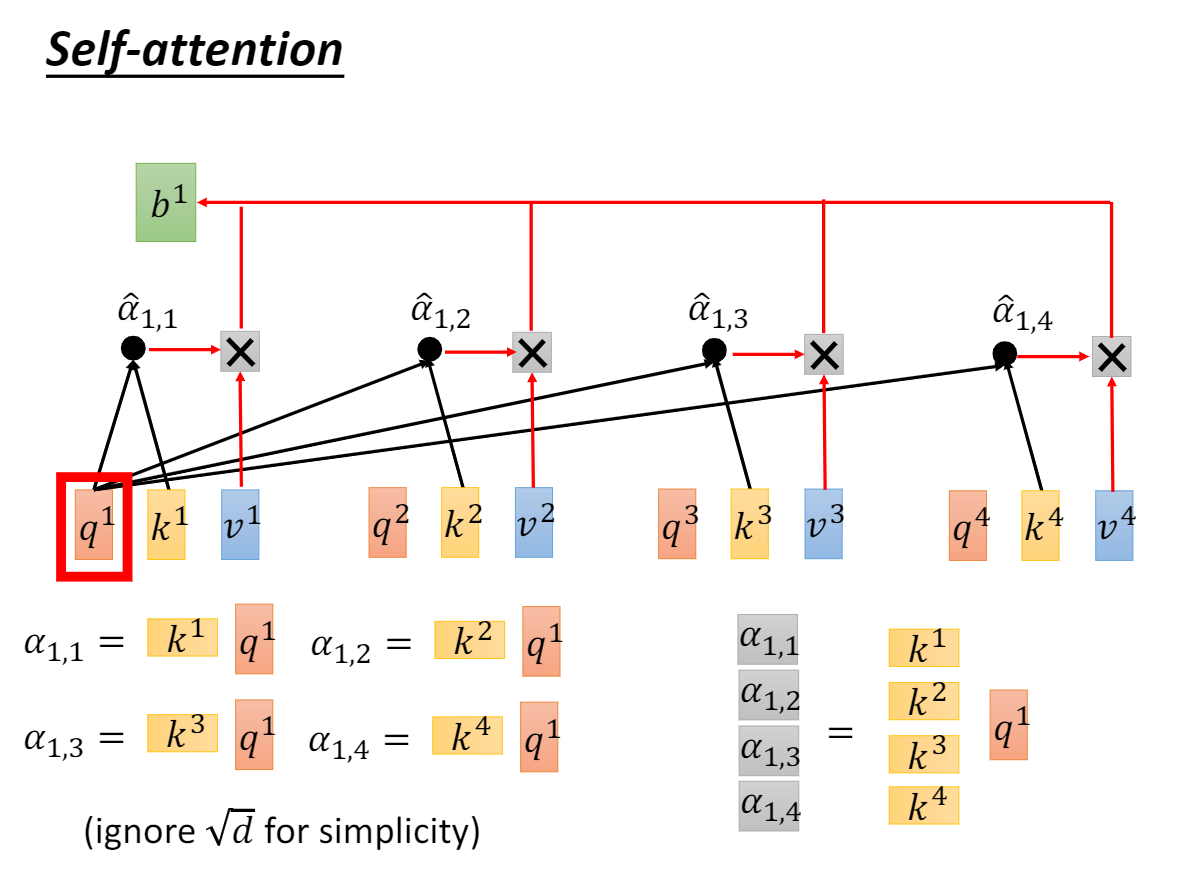
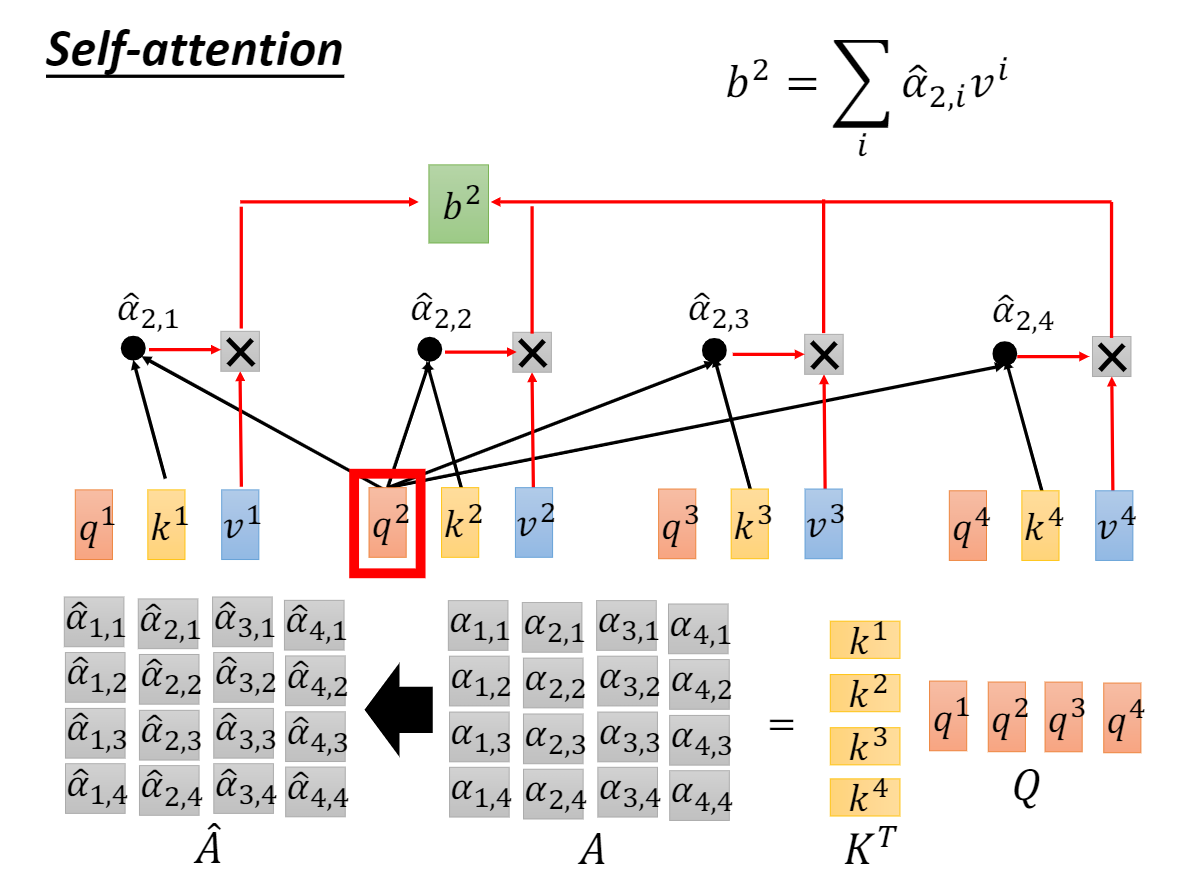
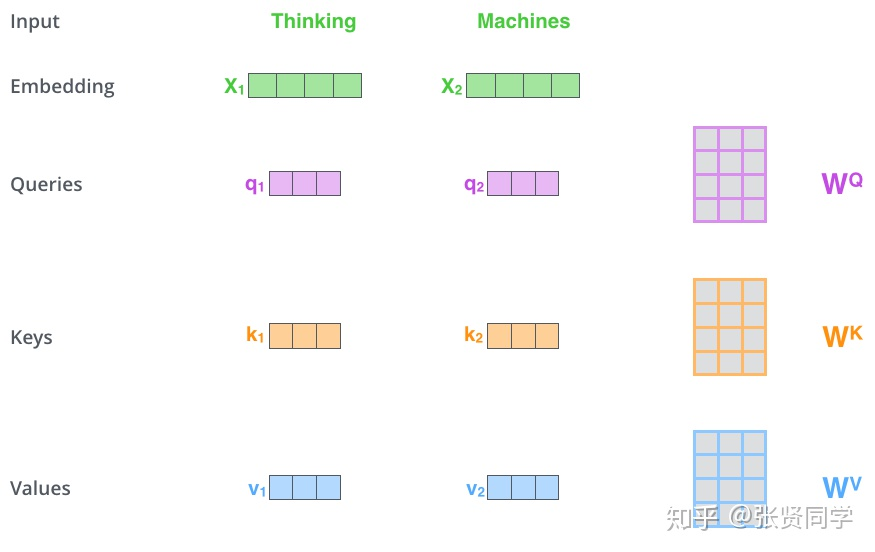
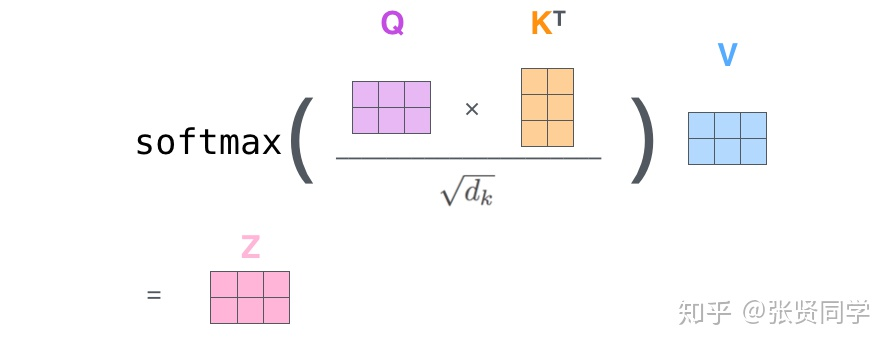
We suspect that for large values d_k, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients.To counteract this effect, we scale the dot products by sqrt(d_k)
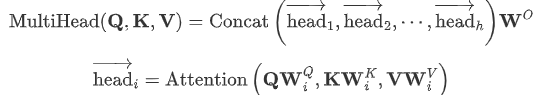
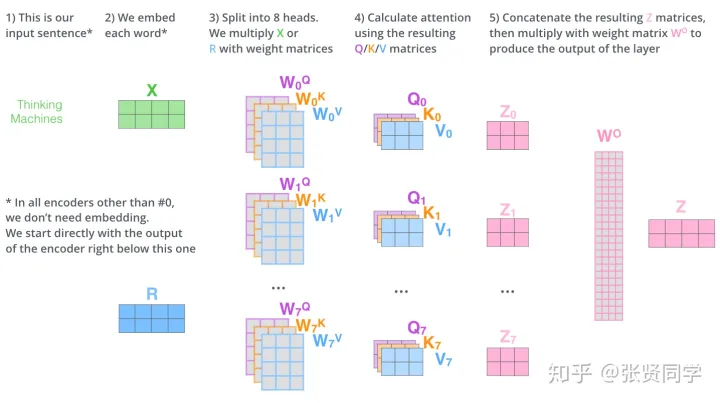
- 它扩展了模型关注不同位置的能力。不同注意力头,关注不同的位置。长距离依赖
- 多头注意力机制赋予 attention 层多个“子表示空间(训练之后,每组注意力可以看作是把输入的向量映射到一个”子表示空间“)
torch.nn.MultiheadAttention(embed_dim, num_heads, dropout=0.0, bias=True, add_bias_kv=False, add_zero_attn=False, kdim=None, vdim=None)
- embed_dim:最终输出的 K、Q、V 矩阵的维度,这个维度需要和词向量的维度一样
- num_heads:设置多头注意力的数量。如果设置为 1,那么只使用一组注意力。如果设置为其他数值,那么 num_heads 的值需要能够被 embed_dim 整除
- dropout:这个 dropout 加在 attention score 后面
forward(query, key, value, key_padding_mask=None, need_weights=True, attn_mask=None)
- query:对应于 Query 矩阵,形状是 (L,N,E) 。其中 L 是输出序列长度,N 是 batch size,E 是词向量的维度
- key:对应于 Key 矩阵,形状是 (S,N,E) 。其中 S 是输入序列长度,N 是 batch size,E 是词向量的维度
- value:对应于 Value 矩阵,形状是 (S,N,E) 。其中 S 是输入序列长度,N 是 batch size,E 是词向量的维度
- key_padding_mask:如果提供了这个参数,那么计算 attention score 时,忽略 Key 矩阵中某些 padding 元素,不参与计算 attention(序列长度不同)。形状是 (N,S)。其中 N 是 batch size,S 是输入序列长度。
- 如果 key_padding_mask 是 ByteTensor,那么非 0 元素对应的位置会被忽略
- 如果 key_padding_mask 是 BoolTensor,那么 True 对应的位置会被忽略
- attn_mask:计算输出时,忽略某些位置。形状可以是 2D (L,S),或者 3D (N∗numheads,L,S)。其中 L 是输出序列长度,S 是输入序列长度,N 是 batch size。
- 如果 attn_mask 是 ByteTensor,那么非 0 元素对应的位置会被忽略
- 如果 attn_mask 是 BoolTensor,那么 True 对应的位置会被忽略
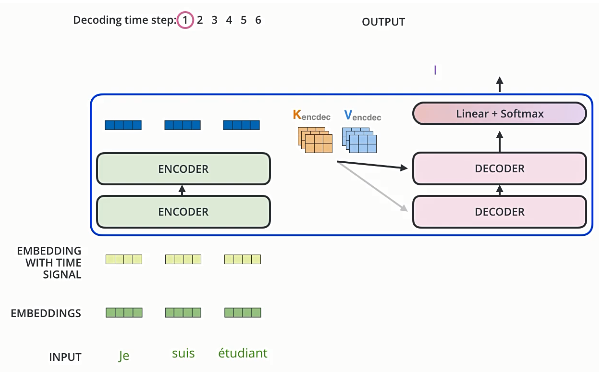
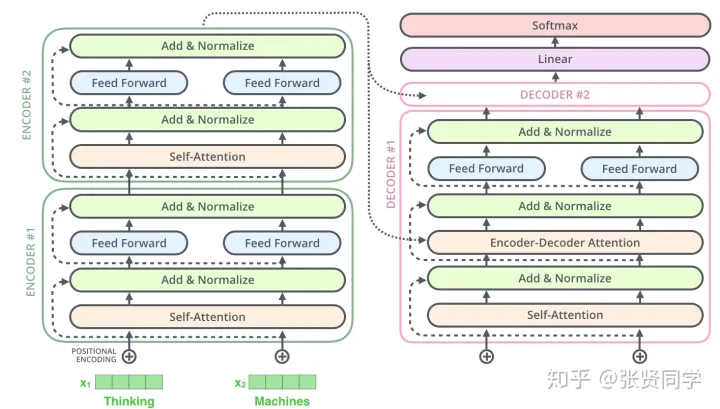
2. Encoder 和 Decoder
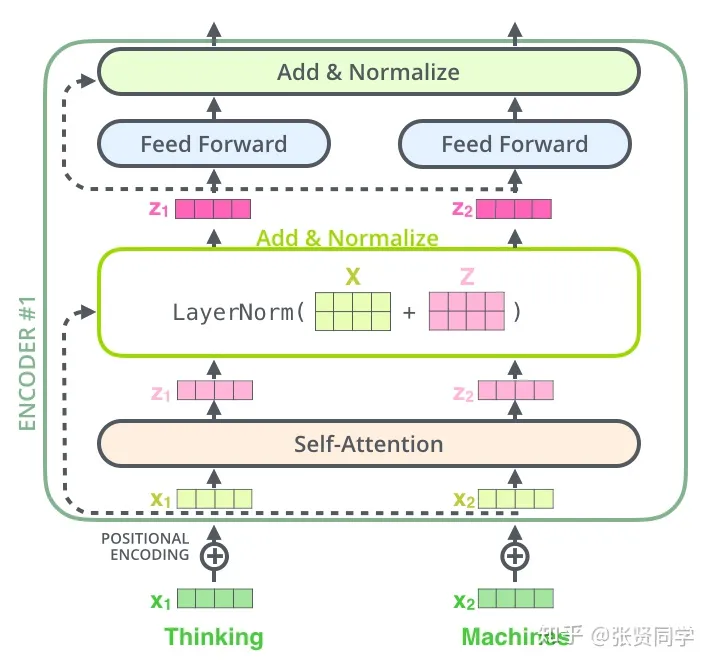
Self-attention layers in the decoder allow each position in the decoder to attend to all positions in the decoder up to and including that position.We need to prevent leftward information flow in the decoder to preserve the auto-regressive property.We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax which correspond to illegal connections.
避免信息泄露,在解码器中使用mask:
attention = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale
if mask is not None:
attention = attention.masked_fill(mask == 0, -1e10)
attention = self.do(torch.softmax(attention, dim=-1))
x = torch.matmul(attention, V)
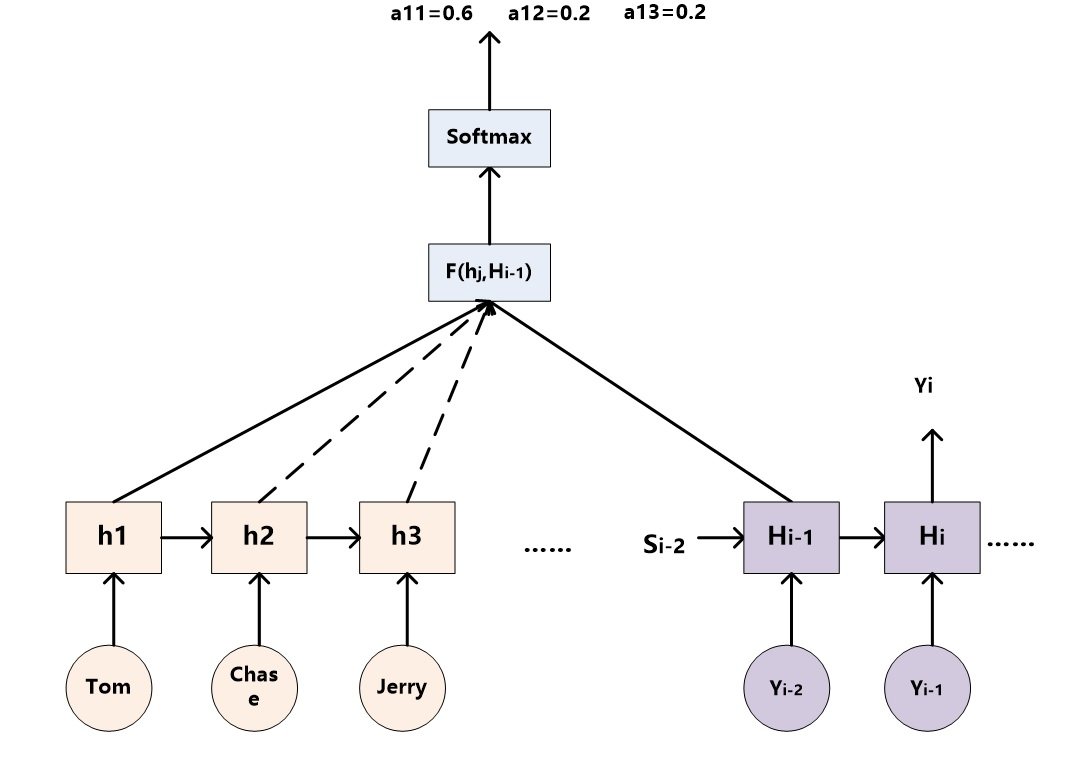

【大语言模型基础】-详解Transformer原理的更多相关文章
- 学习《深度学习与计算机视觉算法原理框架应用》《大数据架构详解从数据获取到深度学习》PDF代码
<深度学习与计算机视觉 算法原理.框架应用>全书共13章,分为2篇,第1篇基础知识,第2篇实例精讲.用通俗易懂的文字表达公式背后的原理,实例部分提供了一些工具,很实用. <大数据架构 ...
- Java基础学习总结(33)——Java8 十大新特性详解
Java8 十大新特性详解 本教程将Java8的新特新逐一列出,并将使用简单的代码示例来指导你如何使用默认接口方法,lambda表达式,方法引用以及多重Annotation,之后你将会学到最新的API ...
- 深入浅出DOM基础——《DOM探索之基础详解篇》学习笔记
来源于:https://github.com/jawil/blog/issues/9 之前通过深入学习DOM的相关知识,看了慕课网DOM探索之基础详解篇这个视频(在最近看第三遍的时候,准备记录一点东西 ...
- Android中Canvas绘图基础详解(附源码下载) (转)
Android中Canvas绘图基础详解(附源码下载) 原文链接 http://blog.csdn.net/iispring/article/details/49770651 AndroidCa ...
- Python学习二:词典基础详解
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/7862377.html 邮箱:moyi@moyib ...
- 三剑客基础详解(grep、sed、awk)
目录 三剑客基础详解 三剑客之grep详解 1.通配符 2.基础正则 3.grep 讲解 4.拓展正则 5.POSIX字符类 三剑客之sed讲解 1.sed的执行流程 2.语法格式 三剑客之Awk 1 ...
- Dom探索之基础详解
认识DOM DOM级别 注::DOM 0级标准实际并不存在,只是历史坐标系的一个参照点而已,具体的说,它指IE4.0和Netscape Navigator4.0最初支持的DHTML. 节点类型 注:1 ...
- javaScript基础详解(1)
javaScript基础详解 首先讲javaScript的摆放位置:<script> 与 </script> 可以放在head和body之间,也可以body中或者head中 J ...
- Python学习一:序列基础详解
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/7858473.html 邮箱:moyi@moyib ...
- java继承基础详解
java继承基础详解 继承是一种由已存在的类型创建一个或多个子类的机制,即在现有类的基础上构建子类. 在java中使用关键字extends表示继承关系. 基本语法结构: 访问控制符 class 子类名 ...
随机推荐
- 集成Unity3D到iOS应用程序中
如果想让原生平台(例如 Java/Android.Objective C/iOS 或 Windows Win32/UWP)包含 Unity 功能,可以通过Unity 生成UnityFramework静 ...
- PVE上启用Intel核显的SR-IOV vGPU
介绍 Intel SR-IOV vGPU是一种硬件虚拟化技术,它允许多个虚拟机共享单个物理GPU,而不会降低性能.SR-IOV定义了一种标准方法,通过将设备分区为多个虚拟功能来共享物理设备功能.每个虚 ...
- Java并发(六)----线程start、run、state方法
1.start 与 run 调用 run public static void main(String[] args) { Thread t1 = new Thread("t1&quo ...
- Spring boot 的定时任务。
@Scheduled(fixedRate=2000):上一次开始执行时间点后2秒再次执行: @Scheduled(fixedDelay=2000):上一次执行完毕时间点后2秒再次执行: @Schedu ...
- [Ngbatis源码学习][SpringBoot] ApplicationContextInitializer接口类的使用和原理解读
ApplicationContextInitializer接口类的使用和原理解读 在看Ngbatis源码的过程中,看到了自定义的ApplicationContextInitializer实现类,对Ap ...
- JS Leetcode 213. 打家劫舍 II 题解分析,在动态规划基础上感受分治算法的魅力
壹 ❀ 引 本题来自LeetCode 213. 打家劫舍 II,难度中等,属于前面我们做过的198. 打家劫舍的升级版,难度同样为中等,题目描述如下: 你是一个专业的小偷,计划偷窃沿街的房屋,每间房内 ...
- CentOS 7 SSH连接超时自动断开解决方案
用SSH登录到Linux的时候,由于默认的连接超时时间很短,经常断开! 1.修改文件 # vi /etc/ssh/sshd_config # vi /etc/ssh/sshd_config 找到 #C ...
- python课本学习-第一章
chapter 1 python开发入门 1.python之父:Guido van Rossum 2.python语言的特征: 简单 易学 免费&开源 可移植性 解释性 面向对象 在面向对象的 ...
- 一键部署Home Assistant ubuntu 20.4.3 树莓派3b+脚本
树莓派3b+安装好 Ubuntu Server 20.04.3 LTS 32bit 后即可适用此脚本,其他版本树莓派/系统可能需要微调脚本*为方便一些未知/已知错误排查 脚本存在冗余部分,足够了解 ...
- C++ 多线程的错误和如何避免(12)
std::async 在简单的 IO 上比 std::thread 更有优势 前提:如果我们只需要一些异步执行的代码,这样不会阻塞主线程的执行,最好的办法是使用 std::async 来执行这些代码. ...