MySQL进阶篇:详解SQL性能分析
MySQL进阶篇:第三章_SQL性能分析
SQL执行频率
MySQL 客户端连接成功后,通过 show [session|global] status 命令可以提供服务器状态信息。通过如下指令,可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次:
-- session 是查看当前会话 ;
-- global 是查询全局数据 ;
SHOW GLOBAL STATUS LIKE 'Com_______';
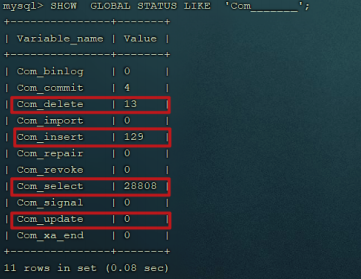
Com_delete: 删除次数
Com_insert: 插入次数
Com_select: 查询次数
Com_update: 更新次数
我们可以在当前数据库再执行几次查询操作,然后再次查看执行频次,看看 Com_select 参数会不会变化。

通过上述指令,我们可以查看到当前数据库到底是以查询为主,还是以增删改为主,从而为数据
库优化提供参考依据。 如果是以增删改为主,我们可以考虑不对其进行索引的优化。 如果是以
查询为主,那么就要考虑对数据库的索引进行优化了。
那么通过查询SQL的执行频次,我们就能够知道当前数据库到底是增删改为主,还是查询为主。 那假如说是以查询为主,我们又该如何定位针对于那些查询语句进行优化呢? 次数我们可以借助于慢查询日志。
慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。
MySQL的慢查询日志默认没有开启,我们可以查看一下系统变量 slow_query_log。

如果要开启慢查询日志,需要在MySQL的配置文件(/etc/my.cnf)中配置如下信息:
# 开启MySQL慢日志查询开关
slow_query_log=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2
配置完毕之后,通过以下指令重新启动MySQL服务器进行测试,查看慢日志文件中记录的信息/var/lib/mysql/localhost-slow.log。
systemctl restart mysqld
然后,再次查看开关情况,慢查询日志就已经打开了。

注:在慢查询日志中,只会记录执行时间超多我们预设时间(2s)的SQL,执行较快的SQL
是不会记录的。
通过慢查询日志,就可以定位出执行效率比较低的SQL,从而有针对性的进行优化。
profile详情
show profiles 能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。通have_profiling
参数,能够看到当前MySQL是否支持profile操作:
SELECT @@have_profiling ;

可以看到,当前MySQL是支持 profile操作的,但是开关是关闭的。可以通过set语句在session/global级别开启profiling:
SET profiling = 1;
开关已经打开了,接下来,我们所执行的SQL语句,都会被MySQL记录,并记录执行时间消耗到哪儿去了。 我们直接执行如下的SQL语句:
select * from tb_user;
select * from tb_user where id = 1;
select * from tb_user where name = '白起';
select count(*) from tb_sku;
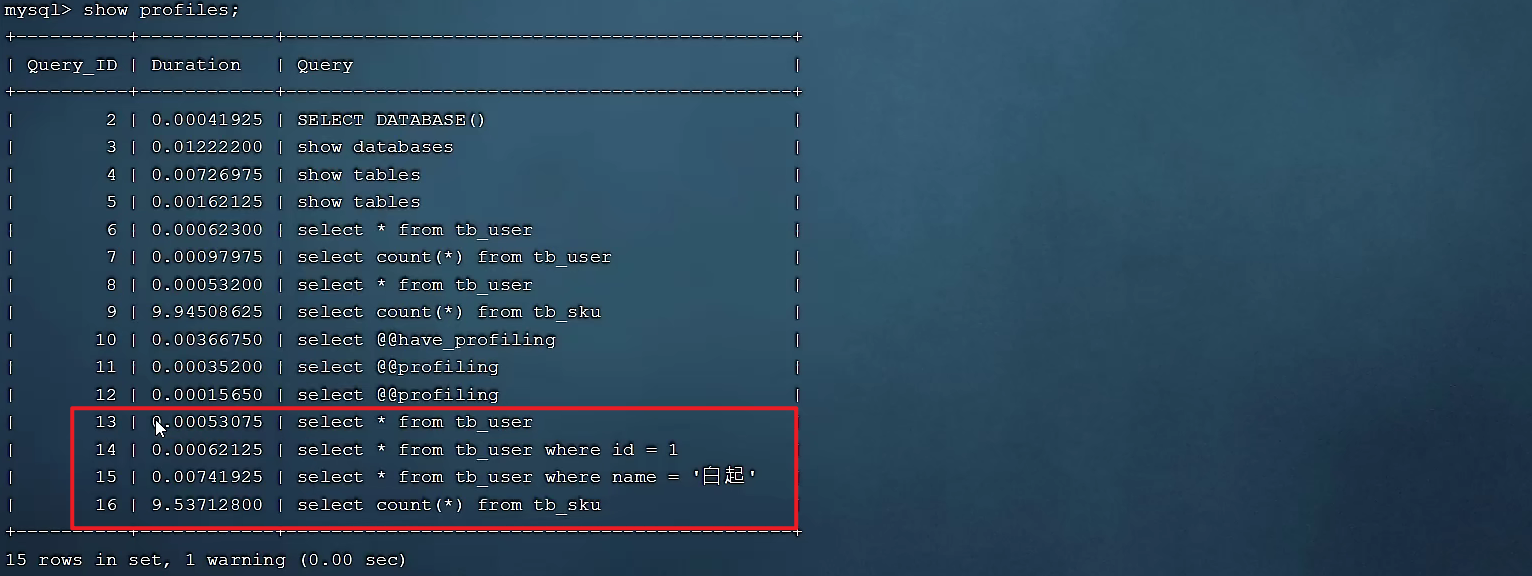
执行一系列的业务SQL的操作,然后通过如下指令查看指令的执行耗时:
-- 查看每一条SQL的耗时基本情况
show profiles;
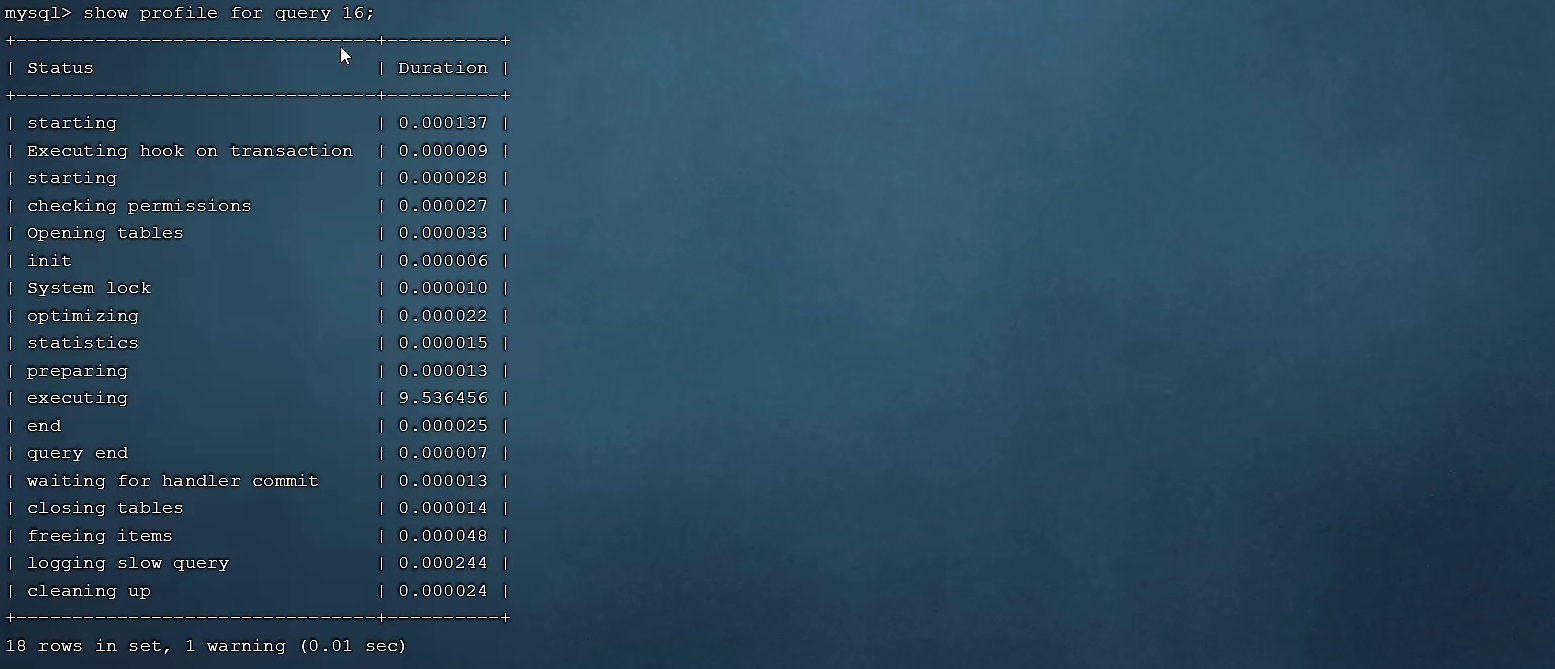
-- 查看指定query_id的SQL语句各个阶段的耗时情况
show profile for query query_id;
-- 查看指定query_id的SQL语句CPU的使用情况
show profile cpu for query query_id;
查看每一条SQL的耗时情况:
查看指定SQL各个阶段的耗时情况 :
explain
EXPLAIN 或者 DESC命令获取 MySQL 如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。
语法:
-- 直接在select语句之前加上关键字 explain / desc
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件 ;

Explain 执行计划中各个字段的含义:
| 字段 | 含义 |
|---|---|
| id | select查询的序列号,表示查询中执行select子句或者是操作表的顺序(id相同,执行顺序从上到下;id不同,值越大,越先执行)。 |
| select_type | 表示 SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接或者子查询)、PRIMARY(主查询,即外层的查询)、UNION(UNION 中的第二个或者后面的查询语句)、SUBQUERY(SELECT/WHERE之后包含了子查询)等 |
| type | 表示连接类型,性能由好到差的连接类型为NULL、system、const、eq_ref、ref、range、 index、all 。 |
| possible_key | 显示可能应用在这张表上的索引,一个或多个。 |
| key | 实际使用的索引,如果为NULL,则没有使用索引。 |
| key_len | 表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长度,在不损失精确性的前提下, 长度越短越好 。 |
| rows | MySQL认为必须要执行查询的行数,在innodb引擎的表中,是一个估计值,可能并不总是准确的。 |
| filtered | 表示返回结果的行数占需读取行数的百分比, filtered 的值越大越好。 |
MySQL进阶篇:详解SQL性能分析的更多相关文章
- Java性能分析之线程栈详解与性能分析
Java性能分析之线程栈详解 Java性能分析迈不过去的一个关键点是线程栈,新的性能班级也讲到了JVM这一块,所以本篇文章对线程栈进行基础知识普及以及如何对线程栈进行性能分析. 基本概念 线程堆栈也称 ...
- 高手详解SQL性能优化十条经验
1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE '%parm1%'—— 红色标识位置的百分号会导致相关列的索引无法使用,最好不要用. 解决办法: 其实只需要对该脚本略做改进,查询速度便会 ...
- 高手详解SQL性能优化十条建议
1.查询的模糊匹配 尽量避免在一个复杂查询里面使用 LIKE '%parm1%'—— 红色标识位置的百分号会导致相关列的索引无法使用,最好不要用. 解决办法: 其实只需要对该脚本略做改进,查询速度便 ...
- MYSQL ini 配置文件详解及性能优化方案
my.ini分为两块:Client Section和Server Section. Client Section用来配置MySQL客户端参数. 要查看配置参数可以用下面的命令: show va ...
- iostat命令详解 IO性能分析
简介 iostat主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息.用户可以通过指定统计的次数和时间 ...
- UIWebView、WKWebView使用详解及性能分析
http://www.cnblogs.com/junhuawang/p/5759224.html
- (6)MySQL进阶篇SQL优化(MyISAM表锁)
1.MySQL锁概述 锁是计算机协调多个进程或线程并发访问某一资源的机制.在数据库中,除传统的计算资源 (如 CPU.RAM.I/O 等)的抢占以外,数据也是一种供许多用户共享的资源.如何保证数 据并 ...
- Scala进阶之路-Scala函数篇详解
Scala进阶之路-Scala函数篇详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.传值调用和传名调用 /* @author :yinzhengjie Blog:http: ...
- Mysql高级操作学习笔记:索引结构、树的区别、索引优缺点、创建索引原则(我们对哪种数据创建索引)、索引分类、Sql性能分析、索引使用、索引失效、索引设计原则
Mysql高级操作 索引概述: 索引是高效获取数据的数据结构 索引结构: B+Tree() Hash(不支持范围查询,精准匹配效率极高) 树的区别: 二叉树:可能产生不平衡,顺序数据可能会出现链表结构 ...
- [Android新手区] SQLite 操作详解--SQL语法
该文章完全摘自转自:北大青鸟[Android新手区] SQLite 操作详解--SQL语法 :http://home.bdqn.cn/thread-49363-1-1.html SQLite库可以解 ...
随机推荐
- 【信创】 JED on 鲲鹏(ARM) 调优步骤与成果
项目背景 基于国家对信创项目的大力推进,为了自主可控的技术发展,基础组件将逐步由国产组件替代,因此从数据库入手,将弹性库JED部署在 国产华为鲲鹏机器上(基于ARM架构)进行调优,与Intel (X8 ...
- 若依vue分离版(ruoyi-vue)跳过token验证,设置白名单
找到SecurityConfig类的configure方法 如图所示 在设置白名单后还需要把接口上的权限标识符去掉.然后需要重启一下项目,热加载不行,会报错.
- 【PHP反序列化】速览
PHP反序列化 一.原理 序列化就是将对象转化成字符串,反序列化相反.数据的格式转换和对象的序列化有利于对象的保存 . 反序列化漏洞:就是php对数据进行反序列化时,没有进行过滤,导致用户可以控制反序 ...
- 计算机的数值转化与网络的IP地址分类与地址划分
数值转换 数字系统由来 远古时代是没有数字系统非位置化数字系统: 罗马数字 (I-1.II-2.III-3.IV-4.V-5.VI-6.VII-7.VIII-8.IX-9.X-10) 位置话数字化系统 ...
- 【matplotlib 实战】--箱型图
箱型图(Box Plot),也称为盒须图或盒式图,1977年由美国著名统计学家约翰·图基(John Tukey)发明.是一种用作显示一组数据分布情况的统计图,因型状如箱子而得名. 它能显示出一组数据的 ...
- [vue]精宏技术部试用期学习笔记 I
精宏技术部试用期学习笔记(vue) 什么是vue? 我个人对 vue 的理解 是把 html\css\js 三件套融合起来的结构,同时用组件化的思维把一个页面装填起来 同时让页面形成树状结构 优点是方 ...
- Web服务器及Web应用服务器
1. 如果仅需要展示html页面,而不要其他功能,apache:(nginx也是类似功能:它本身仅提供html静态页面的功能,不能支持jsp.java servlet.asp等功能,但通过同其他应用服 ...
- 文心一言 VS 讯飞星火 VS chatgpt (129)-- 算法导论11.1 4题
四.用go语言,我们希望在一个非常大的数组上,通过利用直接寻址的方式来实现一个字典.开始时该数组中可能包含一些无用信息,但要对整个数组进行初始化是不太实际的,因为该数组的规模太大.请给出在大数组上实现 ...
- DHorse(K8S的CICD平台)的实现原理
综述 首先,本篇文章所介绍的内容,已经有完整的实现,可以参考这里. 在微服务.DevOps和云平台流行的当下,使用一个高效的持续集成工具也是一个非常重要的事情.虽然市面上目前已经存在了比较成熟的自动化 ...
- Java实现两字符串相似度算法
1.编辑距离 编辑距离:是衡量两个字符串之间差异的度量,它表示将一个字符串转换为另一个字符串所需的最少编辑操作次数(插入.删除.替换). 2.相似度 计算方法可以有多种,其中一种常见的方法是将编辑距离 ...