Oracle中的substr()函数和INSTR()函数和mysql中substring_index函数字符截取函数用法:计算BOM系数用量拼接字符串*计算值方法
最近一直在研究计算产品BOM的成本系数,将拼接的元件用量拼接后拆分计算是个问题,后来受到大佬在mysql中截取字符串的启发在oracle中以substr和instr实现了
1.以下是我在mysql中重写的代码
mysql中使用substring_index
SUBSTRING_INDEX(str, delimiter, count)
返回一个 str 的子字符串,在 delimiter 出现 count 次的位置截取。
如果 count > 0,从则左边数起,且返回位置前的子串;
如果 count < 0,从则右边数起,且返回位置后的子串。
delimiter 是大小写敏感,且是多字节安全的。
取头字符串方法substring_index(gs, '*', 1)
取尾字符串方法substring_index(gs, '*', -1)
取中间字符串方法substring_index(substring_index(gs, '*', 3), '*', -1)
#1.创建测试数据
create table testgs3 as
select '1.1*4.52*1.1' gs
union all
select '2.5*4.5*1.5*2.2' x1
union all
select '1.0' x1
union ALL
select '2*.5*2.5';
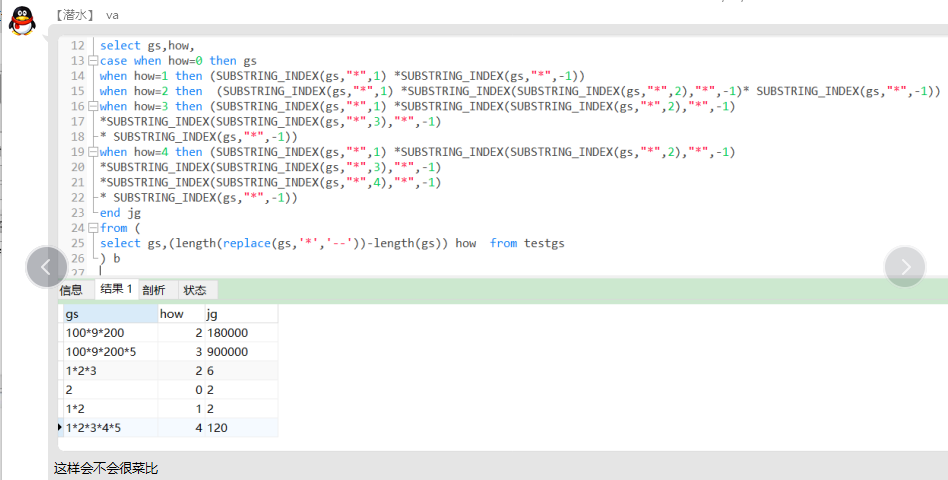
#2.按测试数据进行截取计算
select gs,
how,
case
when how = 0 then gs
when how = 1 then substring_index(gs,'*', 1) *substring_index(gs,'*', -1)
when how = 2 then
substring_index(gs, '*', 1) * substring_index(substring_index(gs, '*', 2), '*', -1) *substring_index(gs, '*', -1)
when how = 3 then
substring_index(gs, '*', 1) *substring_index(substring_index(gs, '*', 2), '*', -1) * substring_index(substring_index(gs, '*', 3),'*', -1) * substring_index(gs, '*' ,- 1)
when how = 4 then
substring_index(gs, '*', 1) *substring_index(substring_index(gs, '*', 2), '*', -1) *substring_index(substring_index(gs, '*', 3), '*', -1) *substring_index(substring_index(gs, '*', 4), '*', -1) * substring_index(gs, '*', -1)
when how = 5 then
substring_index(gs, '*', 1) *substring_index(substring_index(gs, '*', 2), '*', -1) *substring_index(substring_index(gs, '*', 3), '*', -1) *substring_index(substring_index(gs, '*', 4), '*', -1)
*substring_index(substring_index(gs, '*', 5), '*', -1)* substring_index(gs, '*', -1)
when how = 6 then
substring_index(gs, '*', 1) *substring_index(substring_index(gs, '*', 2), '*', -1) *substring_index(substring_index(gs, '*', 3), '*', -1) *substring_index(substring_index(gs, '*', 4), '*', -1)
*substring_index(substring_index(gs, '*', 5), '*', -1)*substring_index(substring_index(gs, '*', 6), '*', -1)* substring_index(gs, '*', -1)
when how = 7 then
substring_index(gs, '*', 1) *substring_index(substring_index(gs, '*', 2), '*', -1) *substring_index(substring_index(gs, '*', 3), '*', -1) *substring_index(substring_index(gs, '*', 4), '*', -1)
*substring_index(substring_index(gs, '*', 5), '*', -1)*substring_index(substring_index(gs, '*', 6), '*', -1)* substring_index(substring_index(gs, '*', 7), '*', -1)*substring_index(gs, '*', -1)
when how = 8 then
substring_index(gs, '*', 1) *substring_index(substring_index(gs, '*', 2), '*', -1) *substring_index(substring_index(gs, '*', 3), '*', -1) *substring_index(substring_index(gs, '*', 4), '*', -1)
*substring_index(substring_index(gs, '*', 5), '*', -1)*substring_index(substring_index(gs, '*', 6), '*', -1)* substring_index(substring_index(gs, '*', 7), '*', -1)
*substring_index(substring_index(gs, '*', 8), '*', -1)*substring_index(gs, '*', -1)
when how = 9 then
substring_index(gs, '*', 1) *substring_index(substring_index(gs, '*', 2), '*', -1) *substring_index(substring_index(gs, '*', 3), '*', -1) *substring_index(substring_index(gs, '*', 4), '*', -1)
*substring_index(substring_index(gs, '*', 5), '*', -1)*substring_index(substring_index(gs, '*', 6), '*', -1)* substring_index(substring_index(gs, '*', 7), '*', -1)
*substring_index(substring_index(gs, '*', 8), '*', -1)*substring_index(substring_index(gs, '*', 9), '*', -1)*substring_index(gs, '*', -1)
end jg
from (select gs, (length(replace(gs, '*', '--')) - length(gs)) how
from testgs3)b
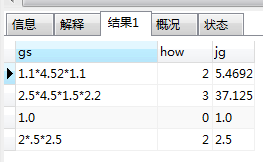
以下是运行后结果:
2.以下是我在ORACLE中实现字符串截取的方法:
ORACLE中使用SUBSTR和INSTR组合
1)substr函数格式 (俗称:字符截取函数)
格式1: substr(string string, int a, int b);
格式2:substr(string string, int a) ;
解释:
格式1:
1、string 需要截取的字符串
2、a 截取字符串的开始位置(注:当a等于0或1时,都是从第一位开始截取)
3、b 要截取的字符串的长度
格式2:
1、string 需要截取的字符串
2、a 可以理解为从第a个字符开始截取后面所有的字符串。
----创建测试数据
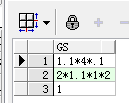
CREATE TABLE TESTGS AS
(SELECT '1.1*4*.1' GS FROM DUAL
UNION ALL
SELECT '2*1.1*1*2' X1 FROM DUAL
UNION ALL
SELECT '1' X1 FROM DUAL)
----拆分组成用量*的字符串lms220103

SELECT GS,
INSTR(GS, '*', 1, 1) N_FIRST,
INSTR(GS, '*', 1, 2) N_LAST,
INSTR(GS, '*', 1, 3) N_MIDDLE,
NVL(SUBSTR(GS, 0, INSTR(GS, '*', 1, 1) - 1), GS) N_FIRST_VALUE1,
NVL(SUBSTR(GS, -1, INSTR(GS, '*', -1, 1) + 1),1) N_LAST_VALUE,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 2) - 1), -1),1) N_MIDDLE_VALUE2,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 3) - 1), -1),1) N_MIDDLE_VALUE3,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 4) - 1), -1),1) N_MIDDLE_VALUE4,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 5) - 1), -1),1) N_MIDDLE_VALUE5,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 6) - 1), -1),1) N_MIDDLE_VALUE6,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 7) - 1), -1),1) N_MIDDLE_VALUE7,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 8) - 1), -1),1) N_MIDDLE_VALUE8,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 9) - 1), -1),1) N_MIDDLE_VALUE9,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 10) - 1), -1),1) N_MIDDLE_VALUE10
FROM (SELECT GS, (LENGTH(REPLACE(GS, '*', '00')) - LENGTH(GS)) HOW
FROM TESTGS)
实施:

----拆分组成用量*的字符串lms220103
WITH V_GS AS (SELECT GS,HOW,
INSTR(GS, '*', 1, 1) N_FIRST,
INSTR(GS, '*', 1, 2) N_LAST,
INSTR(GS, '*', 1, 3) N_MIDDLE,
NVL(SUBSTR(GS, 0, INSTR(GS, '*', 1, 1) - 1), GS) N_FIRST_VALUE1,
NVL(SUBSTR(GS, -1, INSTR(GS, '*', -1, 1) + 1),1) N_LAST_VALUE,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 2) - 1), -1),1) N_MIDDLE_VALUE2,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 3) - 1), -1),1) N_MIDDLE_VALUE3,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 4) - 1), -1),1) N_MIDDLE_VALUE4,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 5) - 1), -1),1) N_MIDDLE_VALUE5,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 6) - 1), -1),1) N_MIDDLE_VALUE6,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 7) - 1), -1),1) N_MIDDLE_VALUE7,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 8) - 1), -1),1) N_MIDDLE_VALUE8,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 9) - 1), -1),1) N_MIDDLE_VALUE9,
NVL(SUBSTR(SUBSTR(GS, 0, INSTR(GS, '*', 1, 10) - 1), -1),1) N_MIDDLE_VALUE10
FROM (SELECT GS, (LENGTH(REPLACE(GS, '*', '00')) - LENGTH(GS)) HOW
FROM TESTGS))
SELECT GS,
HOW,
(CASE
WHEN HOW = 0 THEN
GS
WHEN HOW = 1 THEN to_char(N_FIRST_VALUE1*N_LAST_VALUE)
WHEN HOW = 2 THEN to_char(N_FIRST_VALUE1*N_MIDDLE_VALUE2*N_LAST_VALUE)
WHEN HOW = 3 THEN to_char(N_FIRST_VALUE1*N_MIDDLE_VALUE2*N_MIDDLE_VALUE3*N_LAST_VALUE)
WHEN HOW = 4 THEN to_char(N_FIRST_VALUE1*N_MIDDLE_VALUE2*N_MIDDLE_VALUE3*N_MIDDLE_VALUE4*N_LAST_VALUE)
WHEN HOW = 5 THEN to_char(N_FIRST_VALUE1*N_MIDDLE_VALUE2*N_MIDDLE_VALUE3*N_MIDDLE_VALUE4*N_MIDDLE_VALUE5*N_LAST_VALUE)
WHEN HOW = 6 THEN to_char(N_FIRST_VALUE1*N_MIDDLE_VALUE2*N_MIDDLE_VALUE3*N_MIDDLE_VALUE4*N_MIDDLE_VALUE5*N_MIDDLE_VALUE6*N_LAST_VALUE)
WHEN HOW = 7 THEN to_char(N_FIRST_VALUE1*N_MIDDLE_VALUE2*N_MIDDLE_VALUE3*N_MIDDLE_VALUE4*N_MIDDLE_VALUE5*N_MIDDLE_VALUE6*N_MIDDLE_VALUE7*N_LAST_VALUE)
WHEN HOW = 8 THEN to_char(N_FIRST_VALUE1*N_MIDDLE_VALUE2*N_MIDDLE_VALUE3*N_MIDDLE_VALUE4*N_MIDDLE_VALUE5*N_MIDDLE_VALUE6*N_MIDDLE_VALUE7*N_MIDDLE_VALUE8*N_LAST_VALUE)
WHEN HOW = 9 THEN to_char(N_FIRST_VALUE1*N_MIDDLE_VALUE2*N_MIDDLE_VALUE3*N_MIDDLE_VALUE4*N_MIDDLE_VALUE5*N_MIDDLE_VALUE6*N_MIDDLE_VALUE7*N_MIDDLE_VALUE8*N_MIDDLE_VALUE9*N_LAST_VALUE)
WHEN HOW = 10 THEN to_char(N_FIRST_VALUE1*N_MIDDLE_VALUE2*N_MIDDLE_VALUE3*N_MIDDLE_VALUE4*N_MIDDLE_VALUE5*N_MIDDLE_VALUE6*N_MIDDLE_VALUE7*N_MIDDLE_VALUE8*N_MIDDLE_VALUE9*N_MIDDLE_VALUE10*N_LAST_VALUE)
else '请联系开发更新代码'
END) JG
FROM V_GS
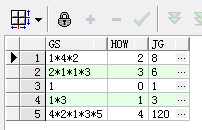
运行的结果:
Oracle中的substr()函数和INSTR()函数和mysql中substring_index函数字符截取函数用法:计算BOM系数用量拼接字符串*计算值方法的更多相关文章
- Oracle substr() 字符截取函数
1.substr函数格式 (俗称:字符截取函数) 格式1: substr(string string, int a, int b); 格式2:substr(string string, int a ...
- MySQL 中的反引号(`):是为了区分 MySql 关键字与普通字符而引入的符号;一般,表名与字段名都使用反引号。
MySQL 中的反引号(`):是为了区分 MySql 关键字与普通字符而引入的符号:一般,表名与字段名都使用反引号.
- Sql Server中的nvarchar(n)、varchar(n) 和Mysql中的char(n)、varchar(n)
刚才有幸看了下 nvarchar(n)和varchar(n),感觉以前的认知有误. nvarchar(n):n指的是字符个数,范围是1-4000,存储的是可变长度的Unicode字符数据. 按字符存储 ...
- mysql 字段包含某个字符的函数
通过sql查询语句,查询某个字段中包含特定字符串: 例子:查询e_book表的types字段包含字符串"3",有下面4种方式 select * from e_book where ...
- EL中拼接字符串的方法
近期在项目中碰到一个需要在JSP页面中比较两String类型的值的问题,于是想当然的写了如下代码: <c:if test="${'p'+longValue=='p1'}"&g ...
- Oracle中的substr()函数 详解及应用
注:本文来源于<Oracle中的substr()函数 详解及应用> 1)substr函数格式 (俗称:字符截取函数) 格式1: substr(string string, int a, ...
- Oracle中的substr()函数详解案例
1)substr函数格式 (俗称:字符截取函数) 格式1: substr(string string, int a, int b); 格式2:substr(string string, int a ...
- JavaScript中字符串截取函数slice()、substring()、substr()
在js中字符截取函数有常用的三个slice().substring().substr()了,下面我来给大家介绍slice().substring().substr()函数在字符截取时的一些用法与区别吧 ...
- 数据库Oracle字符处理函数
练习字符处理函数(数据库表都是从1开始),我们用到一张"伪表" dual: dual 表:dual 是一张只有一个字段,一行记录的表.dual 表也称之为'伪表',因为他不存储主题 ...
- MySQL 中的 FOUND_ROWS() 与 ROW_COUNT() 函数
移植sql server 的存储过程到mysql中,遇到了sql server中的: IF @@ROWCOUNT < 1 对应到mysql中可以使用 FOUND_ROWS() 函数来替换. 1. ...
随机推荐
- Elasticsearch 6.x 配置search-guard 插件
前言 es之前版本一直无用户验证功能,不过官方有提供一x-pack,但是问题是付费.在es的6.3.2版本中,已经集成了x-pack,虽然es团队已经对x-pack开源,但是在该版本中如果需要使用 ...
- ChatGPT的ABAP能力如何?
ChatGPT是最近的热门话题,作为语言模型,它擅长处理各种语言相关的问题.显然,ABAP也是一种语言,ABAP开发者的很大一部分工作就是把自然语言和ABAP语言做互相转换,这应该也是在ChatGPT ...
- 2023-06-23:redis中什么是缓存击穿?该如何解决?
2023-06-23:redis中什么是缓存击穿?该如何解决? 答案2023-06-23: 缓存击穿是指一个缓存中的热点数据非常频繁地被大量并发请求访问,当该热点数据失效的瞬间,持续的大并发请求无法通 ...
- 安装VMware Workstation 16 Pro
下载 官网:https://www.vmware.com/cn/products/workstation-pro/workstation-pro-evaluation.html 注:我是在新毒霸软件管 ...
- APP流水线测试领域探索与最佳实践
1 背景 APP端UI自动化因其特殊性(需连接测试机)一般都在本地执行,这种执行方式的局限性有以下弊端: 时效性低:研发每次打包后都需要通知测试,测试再去打包平台取包,存在时间差 研发自测或产品验收无 ...
- 揭开 RocketMQ 事务消息的神秘面纱
事务消息是 RocketMQ 的高级特性之一,相信很多同学都对于其实现机制很好奇. 这篇文章,笔者会从应用场景.功能原理.实战例子.实现细节四个模块慢慢为你揭开事务消息的神秘面纱. 1 应用场景 以电 ...
- PDF书签的编辑器,基于(python、Tkinter)
使用 脚本 在github下载源码. 安装python3 安装必要的python包 pip install numpy pip install pandas pip install PyMuPDF p ...
- CMU15-445 Project3 Query Execution心得
Project3 Query Execution 心得 一.概述 首先要说:这个 project很有趣很硬核!从这个 project 开始才感觉自己在数据库方面真正成长了! 第一个 project : ...
- Python异常模块与包
Python异常模块与包 一.了解异常 1.1 什么是异常 当检测到一个错误时,Python解释器就无法继续执行了,反而出现了一些错误的提示,这就是所谓的"异常", 也就是我们常说 ...
- 何为DDD
从这一刻开始,请大家忘记自己是一名技术人员,用业务的角度来思考问题. 1.什么是DDD DDD(Domain-driven design,领域驱动设计),是一个很好的应用于微服务架构的方法论 DDD要 ...