Dubbo日志链路追踪TraceId选型

一、目的
开发排查系统问题用得最多的手段就是查看系统日志,但是在分布式环境下使用日志定位问题还是比较麻烦,需要借助 全链路追踪ID 把上下文串联起来,本文主要分享基于 Spring Boot + Dubbo 框架下 日志链路追踪ID 的实现方案选型思路。
目前大多数分布式追踪系统的思想模型都来自 Google's Dapper 论文
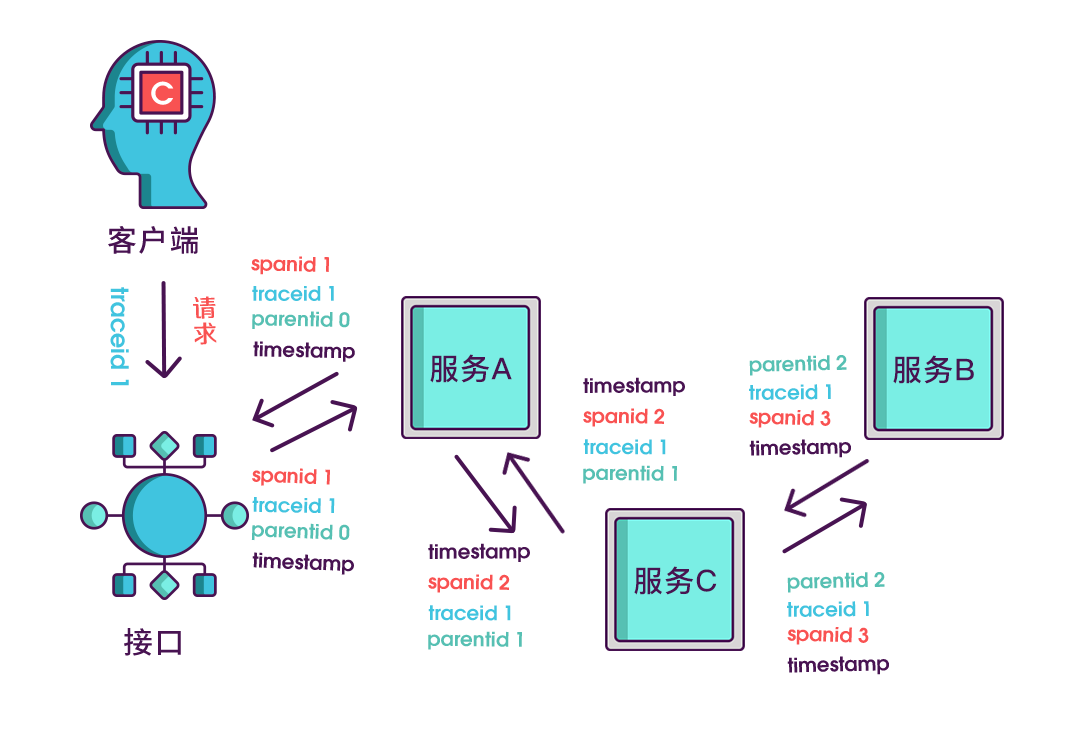
全链路追踪的核心思想:
- 为每条请求都单独分配一个唯一的
traceId用来标识一条请求链路,该traceId会贯穿整个请求处理过程的所有服务 - 每个服务/线程都拥有自己的
spanId标识,代表请求的其中一段处理步骤 - 一个请求包含一个
traceId和一个或多个spanId
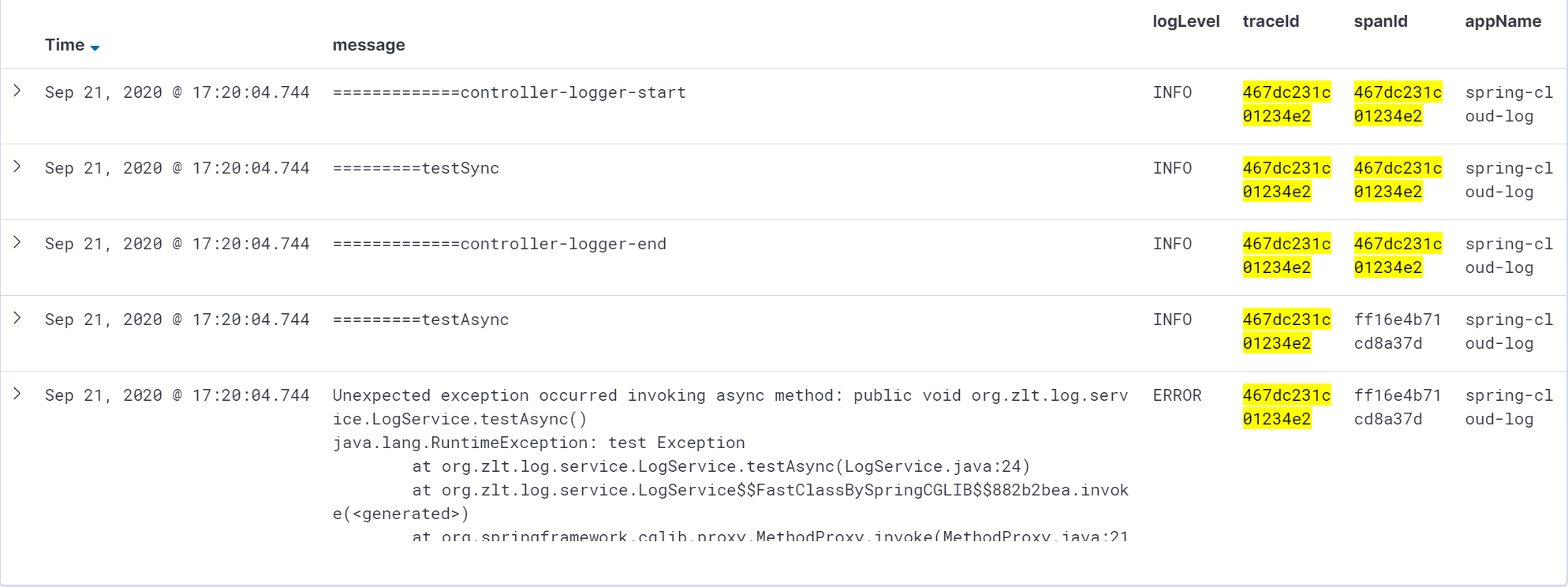
日志全链路追踪 就是在每条系统日志里都添加显示
traceId和spanId信息
二、方案选型
2.1. 方案一(apm-toolkit)
这是 SkyWalking 的一个日志插件,通过这个插件可以在日志中输出
traceId
2.1.1. 使用方式
配置依赖,在 pom 文件中添加以下内容
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-logback-1.x</artifactId>
<version>8.1.0</version>
</dependency>
配置日志模板,修改 logback-spring.xml 文件中 Appender 元素的 encoder 为以下内容
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%tid] [%thread] %-5level %logger{35} - %msg%n</pattern>
</layout>
</encoder>
ps: pattern 中的内容按需修改,其中的 %tid 就是相当于 traceId,默认 TID:N/A,当有请求调用时会生成并显示 traceId
2.1.2. 总结
优点:无需编码,业务无入侵,可与
SkyWalking的图形化界面中使用该ID快速定位各种接口的调用关系。缺点:强耦合
SkyWalking才能生效- 必须添加sk的
javaagent - 必须部署
SkyWalking服务端
- 必须添加sk的
2.2. 方案二(sleuth)
Sleuth 是 Spring Cloud 的组件之一,它为 Spring Cloud 实现了一种分布式追踪解决方案,兼容Zipkin,HTrace与其他日志追踪系统
2.2.1. 使用方式
配置父依赖,在 pom 文件中添加以下内容管理版本号
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth</artifactId>
<version>2.2.4.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencyManagement>
配置依赖,在 pom 文件中添加以下内容
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
适配dubbo,要让 sleuth 支持 dubbo 框架,需要增加以下两个步骤:
首先添加 dubbo 的插件依赖
<dependency>
<groupId>io.zipkin.brave</groupId>
<artifactId>brave-instrumentation-dubbo-rpc</artifactId>
<version>5.12.6</version>
</dependency>
配置 dubbo 过滤器
dubbo:
provider:
filter: tracing
consumer:
filter: tracing
配置日志模板,修改 logback-spring.xml 文件中 Appender 元素的 encoder 为以下内容
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%X{X-B3-TraceId},%X{X-B3-SpanId}] [%thread] %-5level %logger{35} - %msg%n</pattern>
<charset>utf-8</charset>
</encoder>
ps: pattern 中的内容按需修改,其中的 %X{X-B3-TraceId} 为 traceId,%X{X-B3-SpanId} 为 spanId
2.2.2. 总结
优点:业务无入侵,有丰富的插件进行扩展包括定时任务、MQ等。
缺点:
brave-instrumentation-dubbo-rpc不支持dubbo 2.7.x需要自行开发插件。
2.3. 方案三(自研)
2.3.1. 无入侵增加 traceId
使用 Logback 的 MDC 机制,在日志模板中加入 traceId 标识,取值方式为 %X{traceId}
- 系统入口(api网关)创建
traceId的值 - 使用
MDC保存traceId - 修改
logback配置文件模板格式添加标识%X{traceId}
MDC(Mapped Diagnostic Context,映射调试上下文)是 log4j 和 logback 提供的一种方便在多线程条件下记录日志的功能。
2.3.2. 跨线程传递
解决 traceId 跨线程丢失问题
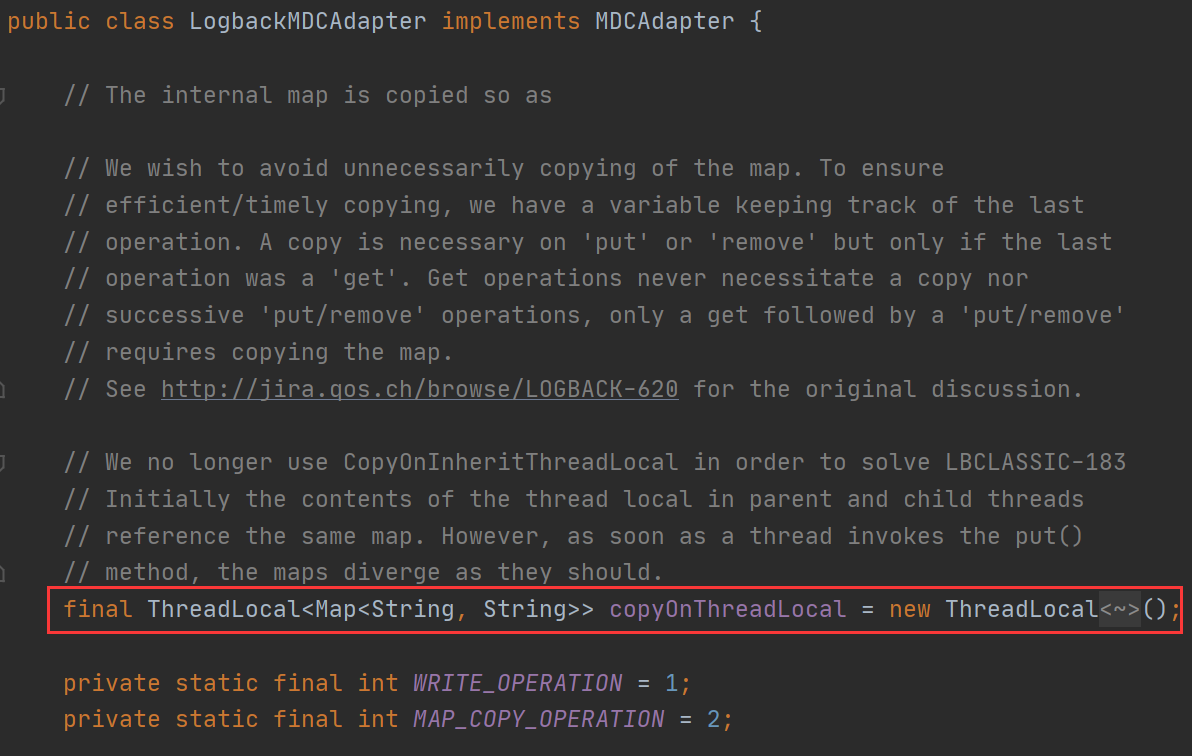
由于 MDC 内部使用的是 ThreadLocal 所以只有本线程才有效,子线程和下游的服务 MDC 里的值会丢失;
需要解决 Spring 的各种线程池与异步方法的父子线程间传递。
解决思路:重写一个 MDCAdapter 使用阿里的 TransmittableThreadLocal 替换原来的 ThreadLocal 对象,解决各种线程池(ExecutorService / ForkJoinPool / TimerTask)父子进程传值问题。
需要使用
TtlRunnable和TtlCallable来修饰传入线程池的Runnable和Callable
2.3.3. 跨进程传递
解决 traceId 跨进程丢失问题
dubbo服务 使用 org.apache.dubbo.rpc.Filter 创建一个过滤器进行 traceId 传递
- 服务消费者:负责传递链路追踪 ID
- 服务提供者:负责接收 ID 并保存到
MDC中
2.3.4. 总结
优点:业务无入侵,最小依赖,扩展灵活,适配性强。
缺点:需要自行实现,有大量的开发工作量。
三、方案总结
| 方案 | 开发工作量 | 可维护性 | 入侵性 | 性能 |
|---|---|---|---|---|
| apm-toolkit | 无 | 低 | 业务无入侵 | 中 |
| sleuth | 中 | 中 | 业务无入侵 | 中 |
| 自研 | 高 | 高 | 业务无入侵 | 高 |
扫码关注有惊喜!

Dubbo日志链路追踪TraceId选型的更多相关文章
- SpringBoot之微服务日志链路追踪
SpringBoot之微服务日志链路追踪 简介 在微服务里,业务出现问题或者程序出的任何问题,都少不了查看日志,一般我们使用 ELK 相关的日志收集工具,服务多的情况下,业务问题也是有些难以排查,只能 ...
- 全链路追踪traceId,ThreadLocal与ExecutorService
关于全链路追踪traceId遇到线程池的问题,做过架构的估计都遇到过,现在以写个demo,总体思想就是获取父线程traceId,给子线程,子线程用完移除掉. mac上的chrome时不时崩溃,写了一大 ...
- 全链路追踪技术选型:pinpoint vs skywalking
目前分布式链路追踪系统基本都是根据谷歌的<Dapper大规模分布式系统的跟踪系统>这篇论文发展而来,主流的有zipkin,pinpoint,skywalking,cat,jaeger等. ...
- 应用SpringAOP及Tlog工具完成日志链路追踪、收集、持久化
一.痛点 目前我司各系统的日志管理比较原始,使用logback打日志到log文件,虽然有服务管理平台,但记录的日志也仅仅是前置机调用后台系统的出入参,当遇到问题时查日志较为麻烦. 登录VPN-打开服务 ...
- dubbo traceId透传实现日志链路追踪(基于Filter和RpcContext实现)
一.要解决什么问题: 使用elk的过程中发现如下问题: 1.无法准确定位一个请求经过了哪些服务 2.多个请求线程的日志交替打印,不利于查看按时间顺序查看一个请求的日志. 二.期望效果 能够查看一个请求 ...
- Dubbo 全链路追踪日志的实现
微服务架构的项目,一次请求可能会调用多个微服务,这样就会产生多个微服务的请求日志,当我们想要查看整个请求链路的日志时,就会变得困难,所幸的是我们有一些集中日志收集工具,比如很热门的ELK,我们需要把这 ...
- 从 1.5 开始搭建一个微服务框架——日志追踪 traceId
你好,我是悟空. 前言 最近在搭一个基础版的项目框架,基于 SpringCloud 微服务框架. 如果把 SpringCloud 这个框架当做 1,那么现在已经有的基础组件比如 swagger/log ...
- 基于SLF4J的MDC机制和Dubbo的Filter机制,实现分布式系统的日志全链路追踪
原文链接:基于SLF4J的MDC机制和Dubbo的Filter机制,实现分布式系统的日志全链路追踪 一.日志系统 1.日志框架 在每个系统应用中,我们都会使用日志系统,主要是为了记录必要的信息和方便排 ...
- 原理分析dubbo分布式应用中使用zipkin做链路追踪
zipkin是什么 Zipkin是一款开源的分布式实时数据追踪系统(Distributed Tracking System),基于 Google Dapper的论文设计而来,由 Twitter 公司开 ...
- 原理分析dubbo分布式应用中使用zipkin做链路追踪(转)
作者:@nele本文为作者原创,转载请注明出处:https://www.cnblogs.com/nele/p/10171794.html 目录 zipkin是什么为什么使用Zipkinzipkin架构 ...
随机推荐
- 002. git 分支管理
git分支 git分支,从本质上来讲仅仅是指向提交对象的可变指针,在这一点上与svn是有着本质区别,svn的分支实际就是个目录而已. git默认分支名字是 master,在多次提交操作后,你其实已经有 ...
- ubuntu安装之后要做的10件事
部分内容整理自网络,如果侵权还请联系 基础配置 换源 换源 [ubuntu清华源镜像站] ctrl+click,进入镜像站链接,选择合适的版本,将镜像地址粘贴到本地文件里,对于: <24.04的 ...
- bashrc和profile区别
转载请注明出处: 作用与目的: .bashrc:这个文件主要用于配置和自定义用户的终端环境和行为.每次启动新的终端时,.bashrc文件都会被执行,加载用户设置的环境变量.别名.函数等.这使得用户能够 ...
- Codes 重新定义 SaaS 模式的研发项目管理平台开源版 4.5.3 发布
一:简介 Codes 重新定义 SaaS 模式 = 云端认证 + 程序及数据本地安装 + 不限功能 + 30 人免费 Codes 是一个 高效.简洁.轻量的一站式研发项目管理平台.包含需求管理,任 ...
- numpy基础--random模块:随机数生成
以下代码的前提:import numpy as np numpy.random模块对python内置的random进行了补充,增加了一些高效生成多种概率分布的样本值的函数.例如可以用normal来得到 ...
- 《Android开发卷——实时监听文本框输入》
在实际开发中,有时候会让用户发布一些类似微博.说说的东西,但是这个是有限制长度的,除了在文本输入框限制长度外,还要在旁边有一条提示还能输入多少个字的"友好提示". 1.文本框 ...
- java把时间戳转换成时间_(转)java时间与时间戳互转
java中时间精确到毫秒级,所以需求时间需要 除以1000 //将时间转换为时间戳 public static String dateToStamp(String s) throws Exceptio ...
- 盘点 Spring Boot 解决跨域请求的几种办法
熟悉 web 系统开发的同学,对下面这样的错误应该不会太陌生. 之所以会出现这个错误,是因为浏览器出于安全的考虑,采用同源策略的控制,防止当前站点恶意攻击 web 服务器盗取数据. 01.什么是跨域请 ...
- FFmpeg GL-transition转场的简单使用体验
写在前面 最近在处理视频,遇到两个视频之间的转场用原生的 xfade写起来很痛苦,实现成本高,难度大:我这里主要用的FFmpeg,就想找一个插件专门干转场这个事:搜索了一翻后找到 GL-transit ...
- 算法金 | Transformer,一个神奇的算法模型!!
大侠幸会,在下全网同名「算法金」 0 基础转 AI 上岸,多个算法赛 Top 「日更万日,让更多人享受智能乐趣」 抱个拳,送个礼 在现代自然语言处理(NLP)领域,Transformer 模型的出现带 ...