kafka的学习之二_kafka的压测与GUI管理
kafka的学习之二_kafka的压测与GUI管理
第一部分创建topic
cd /root/kafka_2.13-3.5.0
bin/kafka-topics.sh --create --bootstrap-server 10.110.139.184:9093 --command-config config/sasl.conf --replication-factor 3 --partitions 3 --topic zhaobsh01
bin/kafka-topics.sh --create --bootstrap-server 10.110.139.184:9093 --command-config config/sasl.conf --replication-factor 2 --partitions 5 --topic zhaobsh02
查看topic列表
bin/kafka-topics.sh --list --bootstrap-server 10.110.139.181:9093,10.110.139.182:9093,10.110.139.184:9093,10.110.139.185:9093,10.110.139.186:9093 --command-config config/sasl.conf
查看topic的分区情况等
bin/kafka-topics.sh --describe --bootstrap-server 10.110.139.181:9093,10.110.139.182:9093,10.110.139.184:9093,10.110.139.185:9093,10.110.139.186:9093 --command-config config/sasl.conf
验证消息的发送与接收
开启一个消息生产端:
bin/kafka-console-producer.sh --bootstrap-server 10.110.139.181:9093 --producer.config config/sasl.conf --topic zhaobsh01
开启一个消息消费端
bin/kafka-console-consumer.sh --bootstrap-server 10.110.139.186:9093 --consumer.config config/sasl.conf --topic zhaobsh01
在消费的生产端输入:
>zhaobsh
>test
然后在消费端就可以看到:
zhaobsh
test
测试脚本部分之一 生产者
bin/kafka-producer-perf-test.sh --num-records 100000 --record-size 1024 --throughput -1 --producer.config config/sasl.conf --topic zhaobsh01 --producer-props bootstrap.servers=10.110.139.181:9093 --print-metrics
# 参数解析
--num-records 100000 消息条数
--record-size 1024 消息大小
--throughput -1 不进行流量限制.
--producer.config 读取用户密码相关
--topic 要测试的消息队列信息.
--print-metrics 展示具体的信息
--producer-props bootstrap.servers=node:port 指定服务器
zhaobsh001:
100000 records sent, 18885.741265 records/sec (18.44 MB/sec), 1128.56 ms avg latency, 1751.00 ms max latency, 1215 ms 50th, 1642 ms 95th, 1731 ms 99th, 1748 ms 99.9th
zhaobsh002:
100000 records sent, 31746.031746 records/sec (31.00 MB/sec), 603.69 ms avg latency, 1039.00 ms max latency, 602 ms 50th, 950 ms 95th, 1028 ms 99th, 1038 ms 99.9th.
# 注意两个队列的特点:
Topic: zhaobsh01 TopicId: si9qBBcyQpKyTFkTURj_uQ PartitionCount: 3 ReplicationFactor: 3 Configs: segment.bytes=1073741824
Topic: zhaobsh01 Partition: 0 Leader: 2 Replicas: 2,3,4 Isr: 2,3,4
Topic: zhaobsh01 Partition: 1 Leader: 3 Replicas: 3,4,5 Isr: 3,4,5
Topic: zhaobsh01 Partition: 2 Leader: 4 Replicas: 4,5,1 Isr: 4,5,1
Topic: zhaobsh02 TopicId: Iok1GhBgTKywxNxo0kh5PA PartitionCount: 5 ReplicationFactor: 2 Configs: segment.bytes=1073741824
Topic: zhaobsh02 Partition: 0 Leader: 1 Replicas: 1,2 Isr: 1,2
Topic: zhaobsh02 Partition: 1 Leader: 2 Replicas: 2,3 Isr: 2,3
Topic: zhaobsh02 Partition: 2 Leader: 3 Replicas: 3,4 Isr: 3,4
Topic: zhaobsh02 Partition: 3 Leader: 4 Replicas: 4,5 Isr: 4,5
Topic: zhaobsh02 Partition: 4 Leader: 5 Replicas: 5,1 Isr: 5,1
测试脚本部分之二 消费者
bin/kafka-consumer-perf-test.sh --fetch-size 10000 --messages 1000000 --topic zhaobsh01 --consumer.config config/sasl.conf --bootstrap-server 10.110.139.181:9093 --print-metrics
# 注意脚本也比较简单.可以直接使用
zhaobsh001:
data.consumed.in.MB: 195.3125
MB.sec: 10.9683
data.consumed.in.nMsg: 200002
nMsg.sec 11231.6505
rebalance.time.ms: 3451
fetch.time.ms 14356
fetch.MB.sec 13.6049
fetch.nMsg.sec 13931.5965
zhaobsh002:
data.consumed.in.MB: 97.6563,
MB.sec: 5.9423,
data.consumed.in.nMsg: 100000,
nMsg.sec 6084.9458,
rebalance.time.ms: 3525,
fetch.time.ms 12909,
fetch.MB.sec 7.5650,
fetch.nMsg.sec 7746.5334
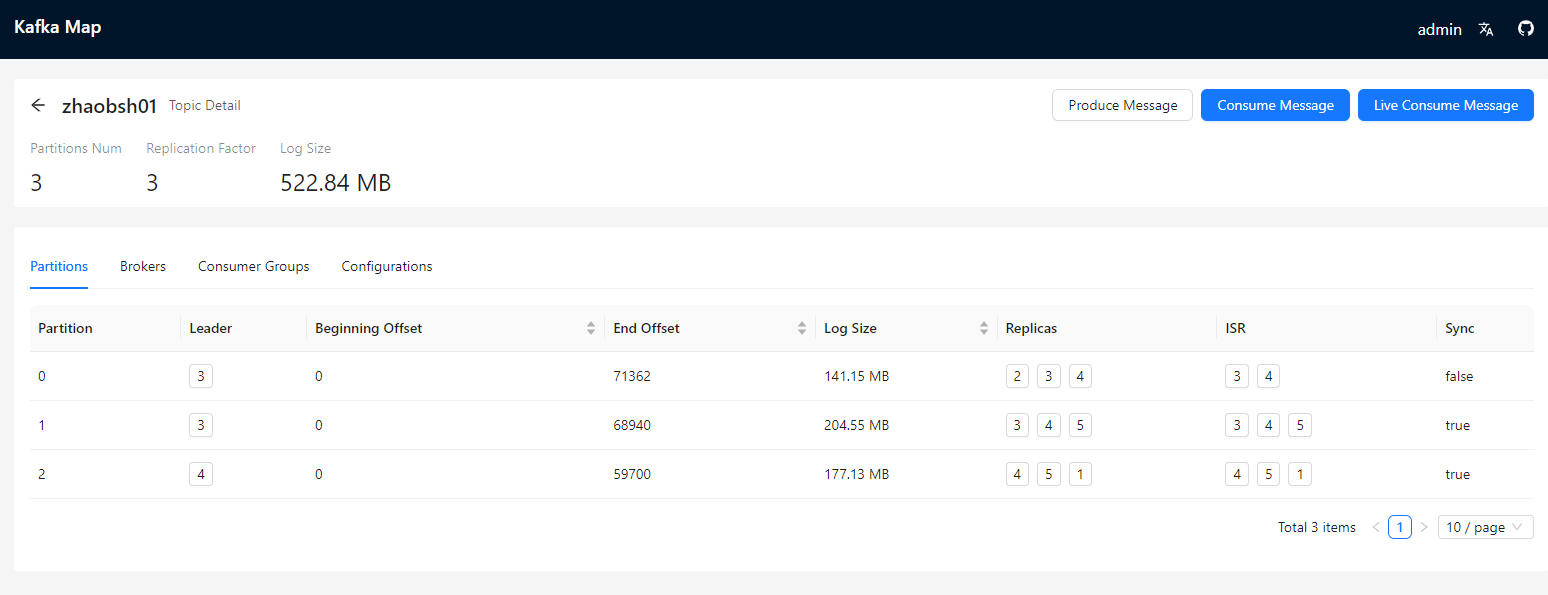
kafka-map 的简单使用
1. 下载:
https://github.com/dushixiang/kafka-map
2. 修改yaml文件
default:
# 初始化安装时的账号
username: admin
# 初始化安装时的密码
password: xxxx
3. 启动服务
nohup /jdk-17.0.2/bin/java -jar kafka-map.jar &
注意 java必须用高版本
4. 打开浏览器访问:
http://ip:8080
# 修改修改默认端口
界面化
kafka的学习之二_kafka的压测与GUI管理的更多相关文章
- elasticsearch系列(二) esrally压测
环境准备 linux centOS(工作环境) python3.4及以上 pip3 JDK8 git1.9及以上 gradle2.13级以上 准备过程中的坑 这些环境准备没什么太大问题,都是wget下 ...
- JMeter分布式压测实战(2020年清明假期学习笔记)
一.常用压力测试工具对比 简介:目前用的常用测试工具对比 1.loadrunner 性能稳定,压测结果及颗粒度大,可以自定义脚本进行压测,但是太过于重大,功能比较繁多. 2.Apache ab(单接口 ...
- Jmeter压测学习6---登录参数CSV
前言 我们在压测登录接口的时候,如果只用一个账号去设置并发压测,这样的结果很显然是不合理的,一个用户并发无法模拟真实的情况.如果要压测登录接口,肯定得准备几百,甚至上千的账号去登录,测试的结果才具有可 ...
- 阿里云linux安装jmeter并进行压测
一.阿里云linux安装JDK 1.下载安装JDK jdk官网,选择linux版本,下载并保存. (一)yum安装 安装epel的yumyuan yum install epel-release -y ...
- 高德全链路压测平台TestPG的架构与实践
导读 2018年十一当天,高德DAU突破一个亿,不断增长的日活带来喜悦的同时,也给支撑高德业务的技术人带来了挑战.如何保障系统的稳定性,如何保证系统能持续的为用户提供可靠的服务?是所有高德技术人面临的 ...
- Java秒杀实战 (四)JMeter压测
转自:https://blog.csdn.net/qq_41305266/article/details/81071278. 一.JMeter入门 下载链接 http://jmeter.apache. ...
- jmeter压测实践
技巧一:命令行执行 命令执行:指定参数,报告的存储位置 jmeter -n -t baidu_requests_results.jmx -r -l baidu_requests_results.jtl ...
- jmeter 压测的执行步骤步骤
一.设置测试参数 如图 Number of Threads:总共起多少个线程. Ramp-UP Period(in seconds):多少秒启动完所有线程. loop Count:循环次数 Sched ...
- 无界面运行Jmeter压测脚本 --后知者
原文作者---后知者 原文地址:http://www.cnblogs.com/houzhizhe/p/8119735.html [后知者的故事]:针对单一接口压测时出现了从未遇到的问题,设好并发量后用 ...
- 无界面运行Jmeter压测脚本
今天在针对单一接口压测时出现了从未遇到的问题,设好并发量后用调度器控制脚本的开始和结束,但在脚本应该自动结束时间,脚本却停不下来,手动stop报告就会有error率,卡了我很久很久不能解决,网络上也基 ...
随机推荐
- 春眠不觉晓,Java数据类型知多少?基础牢不牢看完本文就有数了
文编|JavaBuild 哈喽,大家好呀!我是JavaBuild,以后可以喊我鸟哥!俺滴座右铭是不在沉默中爆发,就在沉默中灭亡,一起加油学习,珍惜现在来之不易的学习时光吧,等工作之后,你就会发现,想学 ...
- 解决大模型“开发难”,昇思MindSpore自动并行技术应用实践
本文分享自华为云社区<DTSE Tech Talk|第35期:解决大模型"开发难",昇思MindSpore自动并行技术应用实践>,作者华为云社区精选. 昇思MindSp ...
- 如何使用TCP/IP开发网络程序
摘要:进行TCP协议网络程序的编写,关键在于ServerSocket套接字的熟练使用,TCP通信中所有的信息传输都是依托ServerSocket类的输入输出流进行的. 本文分享自华为云社区<Ja ...
- Axure 公司年会抽奖器
步骤一:拖拉摆放好相关控件 1.摆好相关相关背景,即一个心形和一行文字"一路同行,感谢同行" 2.一个中继器,中继器里面放有一个300X60的白底黑框矩形.一个"name ...
- zsh踩坑记录
1. zsh: no matches found: uvicorn[standard] 方法一 # 在~/.zshrc中添加下面这句话 setopt no_nomatch # 然后source ~/. ...
- 在低代码开发平台 ILLA Cloud 中使用 Hugging Face 上的模型
ILLA Cloud 是一个面向开发者的开源低代码开发平台,平台专注于帮助开发者快速建立企业内部应用,为开发者节约数据调用与页面设计的时间.平台具有面向开发者.数据整合.协同开发.灵活部署等功能与特点 ...
- peewee update和save性能分析
背景 python项目中使用了peewee这款orm框架,在对数据库更新时有两种语法,分别是save和update方法.有同事说从peewee的日志来看,update比save更快,于是做了一个简单的 ...
- 高数 | Dirichlet 积分
在分析学中,Dirichlet 积分 是如下形式的 无穷限积分 \[\int_{0}^{+\infty} \frac{\sin x}{x} \mathrm{~d} x \] 它是条件收敛的,且收敛到 ...
- 0x53 动态规划-区间DP
A: 石子合并 所求问题:1到n这些石子合并最少需要多少代价 由于石子合并的顺序可以任意,我们将石子分为两个部分 子问题:1到k这堆石子合并,k+1到n这堆石子合并,再把两堆石子合并,需要多少代价\( ...
- 前端科普系列(3):CommonJS 不是前端却革命了前端
本文首发于 vivo互联网技术 微信公众号 链接:https://mp.weixin.qq.com/s/15sedEuUVTsgyUm1lswrKA作者:Morrain 一.前言 上一篇<前端科 ...