011-数据结构-树形结构-B+树[mysql应用]、B*树
一、B+树概述
B+树是B树的变种,有着比B树更高的查询效率。
一棵 B+ 树需要满足以下条件:
- 节点的子树数和关键字数相同(B 树是关键字数比子树数少一)
- 节点的关键字表示的是子树中的最大数,在子树中同样含有这个数据
- 叶子节点包含了全部数据,同时符合左小右大的顺序
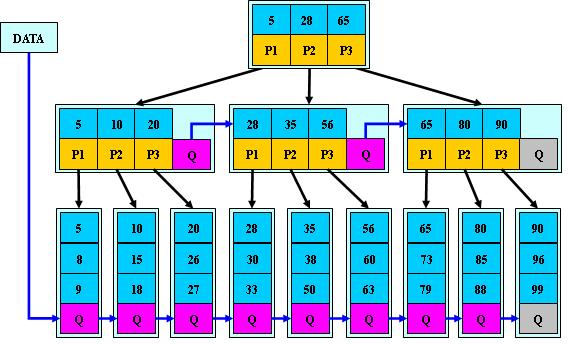
如下图一个M=3 的B+树:
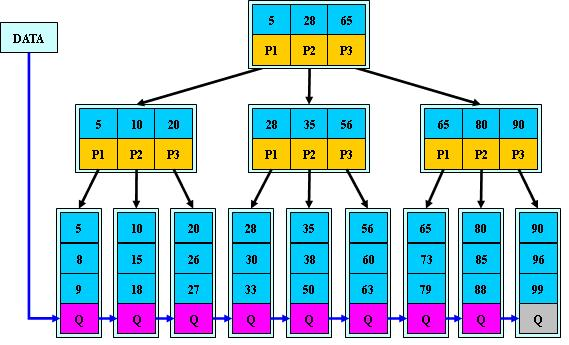
简单概括下 B+ 树的三个特点:
- 关键字数和子树相同
- 非叶子节点仅用作索引,它的关键字和子节点有重复元素
- 叶子节点用指针连在一起
第一点:在 B 树中,节点的关键字用于在查询时确定查询区间,因此关键字数比子树数少一;而在 B+ 树中,节点的关键字代表子树的最大值,因此关键字数等于子树数。
第二点,除叶子节点外的所有节点的关键字,都在它的下一级子树中同样存在,最后所有数据都存储在叶子节点中。根节点的最大关键字其实就表示整个 B+ 树的最大元素。
第三点,叶子节点包含了全部的数据,并且按顺序排列,B+ 树使用一个链表将它们排列起来,这样在查询时效率更快。
由于 B+ 树的中间节点不含有实际数据,只有子树的最大数据和子树指针,因此磁盘页中可以容纳更多节点元素,也就是说同样数据情况下,B+ 树会 B 树更加“矮胖”,因此查询效率更快。
B+ 树的查找必会查到叶子节点,更加稳定。
有时候需要查询某个范围内的数据,由于 B+ 树的叶子节点是一个有序链表,只需在叶子节点上遍历即可,不用像 B 树那样挨个中序遍历比较大小。
B+ 树的三个优点:
- 层级更低,IO 次数更少
- 每次都需要查询到叶子节点,查询性能稳定
- 叶子节点形成有序链表,范围查询方便
1.1、B+树相比B树的优势:
1.单一节点存储更多的元素,使得查询的IO次数更少;
2.所有查询都要查找到叶子节点,查询性能稳定;
3.所有叶子节点形成有序链表,便于范围查询。
代码地址:地址 中的data-004-tree中 BPlusTree
参看地址:
https://blog.csdn.net/u011240877/article/details/80490663
https://blog.csdn.net/qq_33171970/article/details/88395278
1.1、B+树的应用【mysql】
mysql使用B+树作为索引:
B+树相对B树的优点:
①B+树的所有Data域在叶子节点,一般来说都会进行一个优化,就是将所有的叶子节点用指针串联起来,遍历叶子节点就能获取全部数据,这样就能进行区间访问了。
②IO一次读数据是从磁盘上读的,磁盘容量是固定的,取数据量大小是固定的,非叶子节点不存储数据,节点小,磁盘IO次数就少。
1、MYISAM
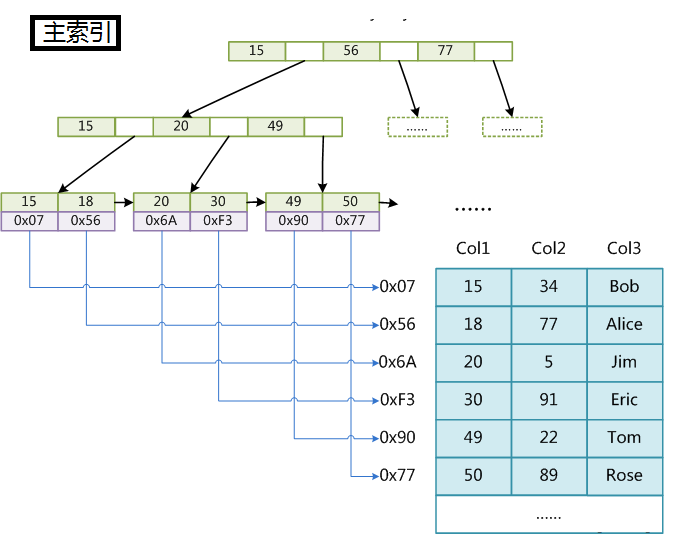

MyISAM中有两种索引,分别是主索引和辅助索引,在这里面的主索引使用具有唯一性的键值进行创建,而辅助索引中键值可以是相同的。MyISAM分别会存一个索引文件和数据文件。它的主索引是非聚集索引。当我们查询的时候我们找到叶子节点中保存的地址,然后通过地址我们找到所对应的信息。
2、INNODB
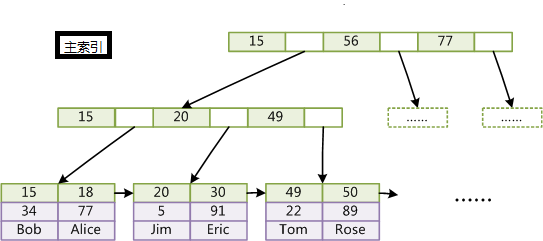
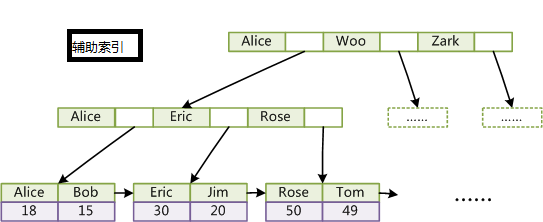
InnoDB索引和MyISAM最大的区别是它只有一个数据文件,在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点数据域保存了完整的数据记录。所以我们又把它的主索引叫做聚集索引。而它的辅助索引和MyISAM也会有所不同,它的辅助索引都是将主键作为数据域。所以,这样当我们查找的时候通过辅助索引要先找到主键,然后通过主索引再找到对于的主键,得到信息。
MyISAM表索引在处理文本索引时更具优势,而INNODB表索引在其它类型上更具效率优势,同时MySQL高并发需要事务场景时,只能使用INNODB表
二、B*树
是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针;
B*树定义了非叶子结点关键字个数至少为(2/3)*M,即块的最低使用率为2/3(代替B+树的1/2);
B+树的分裂:当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向兄弟的指针;
B*树的分裂:当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父结点增加新结点的指针;
所以,B*树分配新结点的概率比B+树要低,空间使用率更高;
代码地址:地址 中的data-004-tree中 BStarTree
三、小结
3.1、对比
二叉树,每个结点只存储一个关键字,等于则命中,小于走左结点,大于走右结点;
B树【B-树】:多路搜索树,每个结点存储M/2到M个关键字,非叶子结点存储指向关键字范围的子结点;所有关键字在整颗树中出现,且只出现一次,非叶子结点可以命中;由于B树的每一个节点都包含key和value,因此经常访问的元素可能离根节点更近,因此访问也更迅速。
B+树:在B-树基础上,为叶子结点增加链表指针,所有关键字都在叶子结点中出现,非叶子结点作为叶子结点的索引;B+树总是到叶子结点才命中;
B*树:在B+树基础上,为非叶子结点也增加链表指针,将结点的最低利用率从1/2提高到2/3;
3.2、为什么说B+tree比B树更适合实际应用中操作系统的文件索引和数据库索引?
(1) B+tree的磁盘读写代价更低
B+tree的内部结点并没有指向关键字具体信息的指针。因此其内部结点相对B树更小。如果把所有同一内部结点的关键字存放在同一盘块中,那么盘块所能容纳的关键字数量也越多。一次性读入内存中的需要查找的关键字也就越多。相对来说IO读写次数也就降低了。
举个例子,假设磁盘中的一个盘块容纳16bytes,而一个关键字2bytes,一个关键字具体信息指针2bytes。一棵9阶B-tree(一个结点最多8个关键字)的内部结点需要2个盘快。而B+ 树内部结点只需要1个盘快。当需要把内部结点读入内存中的时候,B 树就比B+ 树多一次盘块查找时间(在磁盘中就是盘片旋转的时间)。
(2)B+tree的查询效率更加稳定
由于非叶子结点并不是最终指向文件内容的结点,而只是叶子结点中关键字的索引。所以任何关键字的查找必须走一条从根结点到叶子结点的路。所有关键字查询的路径长度相同,导致每一个数据的查询效率相当。
(3)B树在提高了磁盘IO性能的同时并没有解决元素遍历的效率低下的问题。正是为了解决这个问题,B+树应运而生。B+树只要遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁的,而B树不支持这样的操作(或者说效率太低)。
011-数据结构-树形结构-B+树[mysql应用]、B*树的更多相关文章
- Atitit 常见的树形结构 红黑树 二叉树 B树 B+树 Trie树 attilax理解与总结
Atitit 常见的树形结构 红黑树 二叉树 B树 B+树 Trie树 attilax理解与总结 1.1. 树形结构-- 一对多的关系1 1.2. 树的相关术语: 1 1.3. 常见的树形结构 ...
- 数据库索引 引用树形结构 B-数 B+数
MySQL 为什么使用B+数 B-树和B+树最重要的一个区别就是B+树只有叶节点存放数据,其余节点用来索引,而B-树是每个索引节点都会有Data域. 这就决定了B+树更适合用来存储外部数据,也就是所谓 ...
- 为什么 MySQL 索引要使用 B+树而不是其它树形结构?比如 B 树?
一个问题? InnoDB一棵B+树可以存放多少行数据?这个问题的简单回答是:约2千万 为什么是这么多呢? 因为这是可以算出来的,要搞清楚这个问题,我们先从InnoDB索引数据结构.数据组织方式说起. ...
- 为什么MySQL索引要使用 B+树,而不是其它树形结构?
作者:李平 https://www.cnblogs.com/leefreeman/p/8315844.html 一个问题? InnoDB一棵B+树可以存放多少行数据?这个问题的简单回答是:约2千万 为 ...
- 浅谈树形结构的特性和应用(上):多叉树,红黑树,堆,Trie树,B树,B+树...
上篇文章我们主要介绍了线性数据结构,本篇233酱带大家康康 无所不在的非线性数据结构之一:树形结构的特点和应用. 树形结构,是指:数据元素之间的关系像一颗树的数据结构.我们看图说话: 它具有以下特点: ...
- MySql/Oracle树形结构查询
Oracle树形结构递归查询 在Oracle中,对于树形查询可以使用start with ... connect by select * from treeTable start with id='1 ...
- 012-数据结构-树形结构-哈希树[hashtree]、字典树[trietree]、后缀树
一.哈希树概述 1.1..其他树背景 二叉排序树,平衡二叉树,红黑树等二叉排序树.在大数据量时树高很深,我们不断向下找寻值时会比较很多次.二叉排序树自身是有顺序结构的,每个结点除最小结点和最大结点外都 ...
- 010-数据结构-树形结构-B树[B-树]
一.概述 B 树就是常说的“B 减树(B- 树)”,又名平衡多路(即不止两个子树)查找树. 在计算机科学中,B树(英语:B-tree)是一种自平衡的树,能够保持数据有序.这种数据结构能够让查找数据.顺 ...
- MySQL 树形结构 根据指定节点 获取其所在全路径节点序列
背景说明 需求:MySQL树形结构, 根据指定的节点,获取其所在全路径节点序列. 问题分析 1.可以使用类似Java这种面向对象的语言,对节点集合进行逻辑处理,获取全路径节点序列. 2.直接自定义My ...
随机推荐
- Linux命令——blkid
简介 blkid用于查看块设备UUID.Label.挂载.文件系统类型等信息 选项参数 无参数——显示所有已挂载分区信息 查看特定分区 -s:指定输出信息(UUID.TYPE.LABEL.PTTYPE ...
- 基于tornado---异步并发接口
1.目的 由于有多个程序和脚本需要对mysql进行读写数据库,每次在脚本中进行数据库的连接.用cursor进行操作过于麻烦,因此希望可以有一个脚本开放接口,只需要传入sql语句,就可以返回结果回来.因 ...
- ViCANdo新版本发布(PART2)| XCP集成
大家好,这是ViCANdo功能更新的第二篇,上一篇我们介绍了ViCANdo对PCL的集成,这一篇我们介绍ViCANdo工具支持的另外一个功能:XCP解析功能集成. 标定 ...
- MySQL:查询、修改(二)
干货: 使用SELECT查询的基本语句SELECT * FROM <表名>可以查询一个表的所有行和所有列的数据.SELECT查询的结果是一个二维表. 使用SELECT *表示查询表的所有列 ...
- 我感觉这个书上的微信小程序登陆写得不好
基本功能是OK,但是感觉传的数据太多,不安全,需要改写. App({ d: { hostUrl: 'http://www.test.com/index.php', //请填写您自己的小程序主机URL ...
- P3193 [HNOI2008]GT考试(KMP+矩阵乘法加速dp)
P3193 [HNOI2008]GT考试 思路: 设\(dp(i,j)\)为\(N\)位数从高到低第\(i\)位时,不吉利数字在第\(j\)位时的情况总数,那么转移方程就为: \[dp(i,j)=dp ...
- ASP.NET Core 类库中取读配置文件 appsettings.json
首先引用NuGet包 Microsoft.Extensions.Configuration Microsoft.Extensions.Configuration.Json Microsoft.Exte ...
- 数据分析 - Numpy
简介 Numpy是高性能科学计算和数据分析的基础包.它也是pandas等其他数据分析的工具的基础,基本所有数据分析的包都用过它.NumPy为Python带来了真正的多维数组功能,并且提供了丰富的函数库 ...
- create系列创建节点的方法
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- nexus 3.17.0 简单说明
nexus 在6.24 发布了3.17.0 ,同时包含了好多新的特性 以下为一些主要变动: routing rules 可以增强repo 的安全 apt repo 格式的支持 可以方便的为ubuntu ...