认识map-reduce
基本概念
map-reduce1.0
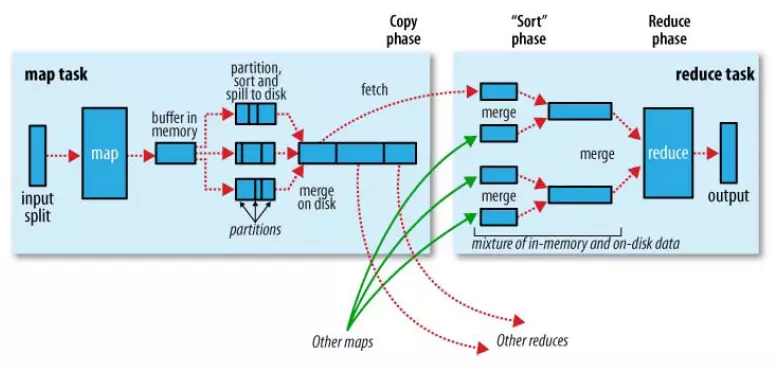
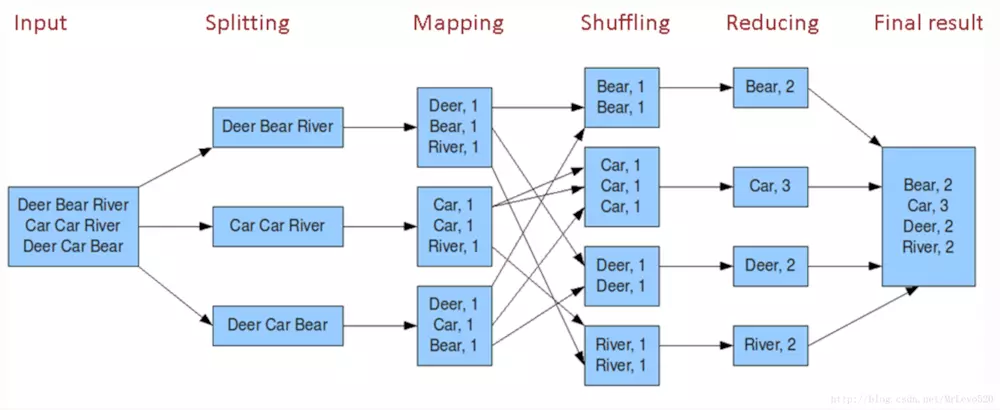
例子:
hadoop streaming
- 用语言驱动map-reduce的话,使用的hadoop streaming命令,可以通过python,php,java来驱动;
- 命令参数列表如下:
|
-input <path> |
输入数据路径 |
|
-output <path> |
输出数据路径 |
|
-mapper <cmd|JavaClassName> |
mapper可执行程序或Java类 |
|
-reducer <cmd|JavaClassName> |
reducer可执行程序或Java类 |
|
-file <file> Optional |
分发本地文件 |
|
-cacheFile <file> Optional |
分发HDFS文件 |
|
-cacheArchive <file> Optional |
分发HDFS压缩文件 |
|
-numReduceTasks <num> Optional |
reduce任务个数 |
|
-jobconf | -D NAME=VALUE Optional |
作业配置参数 |
|
-combiner <JavaClassName>Optional |
Combiner Java类 |
|
-partitioner <JavaClassName>Optional |
Partitioner Java类 |
|
-inputformat <JavaClassName> Optional |
InputFormat Java类 |
|
-outputformat <JavaClassName> Optional |
OutputFormat Java类 |
|
-inputreader <spec> Optional |
InputReader配置 |
|
-cmdenv <n>=<v> Optional |
传给mapper和reducer的环境变量 |
|
-mapdebug <path> Optional |
mapper失败时运行的debug程序 |
|
-reducedebug <path> Optional |
reducer失败时运行的debug程序 |
|
-verbose Optional |
详细输出模式 |
map和 reduce task的个数设置问题
参考资料: https://www.cnblogs.com/xiangyangzhu/p/5278328.html
reduce task的个数 决定 map task的个数,reduce task的个数是人为指定的(??存疑,还有一种说法是文件大小和block的关系决定map task的个数)
MapReduce作业中Map Task数目的确定:
1)MapReduce从HDFS中分割读取Split文件,通过Inputformat交给Mapper来处理。Split是MapReduce中最小的计算单元,一个Split文件对应一个Map Task
2)默认情况下HDFS种的一个block,对应一个Split。
3)当执行Wordcount时:
(1)一个输入文件小雨64MB,默认情况下则保存在hdfs上的一个block中,对应一个Split文件,所以将产生一个Map Task。
(2)如果输入一个文件为150MB,默认情况下保存在HDFS上的三个block中,对应三个Split文件,所以将产生三个Map Task。
(3)如果有输入三个文件都小于64MB,默认情况下会保存在三个不同的block中,也将产生三个Map Task。
4)用户可自行指定block与split的关系,HDSF中的一个block,一个Split也可以对应多个block。Split与block的关系都是一对多的关系。
5)总结MapReduce作业中的Map Task数目是由:
(1)输入文件的个数与大小
(2)hadoop设置split与block的关系来决定。
MapReduce作业中Reduce Task数目的指定:
1)JobClient类中submitJobInternal方法中指定:int reduces=jobCopy.getNumReduceTasks();
2)而JobConf类中,public int getNumReduceTasks(){return geInt("mapred.reduce.tasks",1)}
因此,Reduce Task数目是由mapred.reduce.tasks指定,如果不指定则默认为1.
这就很好解释了wordcount程序中的reduce数量为1的问题,这时候map阶段的partition(分区)就为1了。
other说法
增加task的数量,一方面增加了系统的开销,另一方面增加了负载平衡和减小了任务失败的代价;
map task的数量即mapred.map.tasks的参数值,用户不能直接设置这个参数。Input Split的大小,决定了一个Job拥有多少个map。默认input split的大小是64M(与dfs.block.size的默认值相同)。然而,如果输入的数据量巨大,那么默认的64M的block会有几万甚至几十万的Map Task,集群的网络传输会很大,最严重的是给Job Tracker的调度、队列、内存都会带来很大压力。mapred.min.split.size这个配置项决定了每个 Input Split的最小值,用户可以修改这个参数,从而改变map task的数量。
一个恰当的map并行度是大约每个节点10-100个map,且最好每个map的执行时间至少一分钟。
reduce task的数量由mapred.reduce.tasks这个参数设定,默认值是1。
合适的reduce task数量是0.95或者0.75*( nodes * mapred.tasktracker.reduce.tasks.maximum), 其中,mapred.tasktracker.tasks.reduce.maximum的数量一般设置为各节点cpu core数量,即能同时计算的slot数量。对于0.95,当map结束时,所有的reduce能够立即启动;对于1.75,较快的节点结束第一轮reduce后,可以开始第二轮的reduce任务,从而提高负载均衡
性能优化
Reducers数过多的情况:
生成了很多个小文件(最终输出文件由reducer决定,一个reducer输出一个文件),那么如果这些小文件作为下一个Job输入,则会出现小文件过多需要进行合并的问题。而且启动和初始化reducer需要耗费时间和资源。
Reducers数过少:
执行耗时,并且可能出现数据倾斜
Reducer个数的决定:
默认情况下,Hive分配reducer个数由下列参数决定:
参数1:hive.exec.reducers.bytes.per.reducer(默认为1G)
参数2:hive.exec.reducers.max(默认为999)
计算reducer数的公式:
N=min(参数2,总输入数据量/参数1)
即默认一个reduce处理1G数据量。
注意:与mapred.map.tasks参数不同,如果设置了setmapred.reduce.tasks参数的数值,忽略上述计算,reducer个数可以由mapred.reduce.tasks直接指定。
认识map-reduce的更多相关文章
- MapReduce剖析笔记之三:Job的Map/Reduce Task初始化
上一节分析了Job由JobClient提交到JobTracker的流程,利用RPC机制,JobTracker接收到Job ID和Job所在HDFS的目录,够早了JobInProgress对象,丢入队列 ...
- python--函数式编程 (高阶函数(map , reduce ,filter,sorted),匿名函数(lambda))
1.1函数式编程 面向过程编程:我们通过把大段代码拆成函数,通过一层一层的函数,可以把复杂的任务分解成简单的任务,这种一步一步的分解可以称之为面向过程的程序设计.函数就是面向过程的程序设计的基本单元. ...
- 记一次MongoDB Map&Reduce入门操作
需求说明 用Map&Reduce计算几个班级中,每个班级10岁和20岁之间学生的数量: 需求分析 学生表的字段: db.students.insert({classid:1, age:14, ...
- filter,map,reduce,lambda(python3)
1.filter filter(function,sequence) 对sequence中的item依次执行function(item),将执行的结果为True(符合函数判断)的item组成一个lis ...
- map reduce
作者:Coldwings链接:https://www.zhihu.com/question/29936822/answer/48586327来源:知乎著作权归作者所有,转载请联系作者获得授权. 简单的 ...
- python基础——map/reduce
python基础——map/reduce Python内建了map()和reduce()函数. 如果你读过Google的那篇大名鼎鼎的论文“MapReduce: Simplified Data Pro ...
- Map/Reduce 工作机制分析 --- 作业的执行流程
前言 从运行我们的 Map/Reduce 程序,到结果的提交,Hadoop 平台其实做了很多事情. 那么 Hadoop 平台到底做了什么事情,让 Map/Reduce 程序可以如此 "轻易& ...
- Map/Reduce个人实战--生成数据测试集
背景: 在大数据领域, 由于各方面的原因. 有时需要自己来生成测试数据集, 由于测试数据集较大, 因此采用Map/Reduce的方式去生成. 在这小编(mumuxinfei)结合自身的一些实战经历, ...
- 用通俗易懂的大白话讲解Map/Reduce原理
Hadoop简介 Hadoop就是一个实现了Google云计算系统的开源系统,包括并行计算模型Map/Reduce,分布式文件系统HDFS,以及分布式数据库Hbase,同时Hadoop的相关项目也很丰 ...
- map/reduce of python
[map/reduce of python] 参考: http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac92 ...
随机推荐
- 如何在yii1.0.7中设置数据库连接超时?
继承CDbConnection, 覆盖 init()方法 在 parent::init() 之前设置 $this->setAttribute(PDO::ATTR_TIMEOUT, $this-& ...
- DGCNN
架构总览 模型的整体架构源于 WebQA 的参考论文 Dataset and Neural Recurrent Sequence Labeling Model for Open-Domain Fact ...
- 休谟:《人性论》一书中提出的要重视"是"与"应该"的区别
"价值"最初是经济学的范畴,指的是经济价值.商品价值.价值作的为一个哲学概念,首先大概是由18 世纪的英国哲学家休谟(David H ume,1711-1776)提出的.他于173 ...
- Elastic 使用索引生命周期管理实现热温冷架构
Elastic: 使用索引生命周期管理实现热温冷架构 索引生命周期管理 (ILM) 是在 Elasticsearch 6.6(公测版)首次引入并在 6.7 版正式推出的一项功能.ILM 是 Elast ...
- Linux链接文件——软连接和硬链接
Linux链接文件——软连接和硬链接 摘要:本文主要介绍了Linux系统中的链接文件. 文件系统 在Linux系统中,将文件分为两个部分:用户数据和元数据. 元数据(inode) 元数据即文件的索引节 ...
- 一次压测中tomcat生成session释放不及时导致的频繁fullgc性能优化案例
性能问题:老年代一直处于占满状态,为什么没有发生内存溢出 以HotSpot VM的分代式GC为例,普通对象分配都是在young gen进行的,具体是从在位于young gen中的eden space中 ...
- 从webkit内核简单看css样式和css规则优先级(权重)
目录 webkit中样式相关类及类间关系 样式规则匹配 权重(优先级)计算 权重相同时的覆盖原则 webkit中样式相关类及类间关系 资料来源: <webkit技术内幕> 结构相关类: 1 ...
- RV32I基础整数指令集
RV32I是32位基础整数指令集,它支持32位寻址空间,支持字节地址访问,仅支持小端格式(little-endian,高地址高位,低地址地位),寄存器也是32位整数寄存器.RV32I指令集的目的是尽量 ...
- 智能社javascript
http://www.chuanke.com/?mod=student&act=study&courseid=91706
- Struts2 Action的3种创建方式
Action是Strut2的核心内容,相当于Servlet,用于处理业务. Action是一个Java类,直接新建Java类即可. Action有3种实现方式. 1.使用POJO,设置成员变量,写对应 ...