[转帖]dfs和bfs
dfs和bfs
https://www.cnblogs.com/wzl19981116/p/9397203.html
1.dfs(深度优先搜索)是两个搜索中先理解并使用的,其实就是暴力把所有的路径都搜索出来,它运用了回溯,保存这次的位置,深入搜索,都搜索完了便回溯回来,搜下一个位置,直到把所有最深位置都搜一遍,要注意的一点是,搜索的时候有记录走过的位置,标记完后可能要改回来;
回溯法是一种搜索法,按条件向前搜索,以达到目标。但当探索到某一步时,发现原先选择达不到目标,就退回一步重新选择,这种走不通就退回再走的技术为回溯法;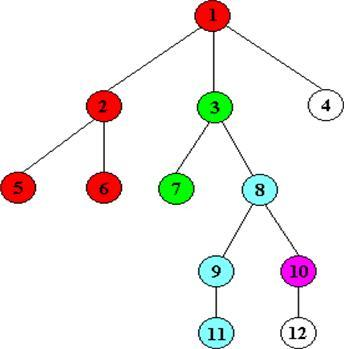
例如这张图,从1开始到2,之后到5,5不能再走了,退回2,到6,退回2退回1,到3,一直进行;
理解这种方法比较简单,难的是要怎么用
void dfs(int deep)
{
int x=deep/n,y=deep%n;
if(符合某种要求||已经不能在搜了)
{
做一些操作;
return ;
}
if(符合某种条件且有地方可以继续搜索的)//这里可能会有多种条件,可能要循环什么的
{
a[x][y]='x';//可能要改变条件,这个是瞎写的
dfs(deep+1,sum+1);//搜索下一层
a[x][y]='.';//可能要改回条件,有些可能不用改比如搜地图上有多少块连续的东西
}
}2.bfs(宽度/广度优先搜索),这个一直理解了思想,不会用,后面才会的,思想,从某点开始,走四面可以走的路,然后在从这些路,在找可以走的路,直到最先找到符合条件的,这个运用需要用到队列(queue),需要稍微掌握这个才能用bfs。

一张图,bfs就是和它类似,很好的帮助理解,雷从上往下,同时向四面八方的延长(当然不是很严谨的),然后找到那个最近的建筑物,然后劈了它;
还是这张图,从1开始搜,有2,3,4几个点,存起来,从2开始有5,6,存起来,搜3,有7,8,存起来,搜4,没有了;现在开始搜刚刚存的点,从5开始,没有,然后搜6.。。一直进行,直到找到;
int visit[N][N]//用来记录走过的位置
int dir[4][2]={0,-1,0,1,-1,0,1,0};
struct node
{
int x,y,bits;//一般是点,还有步数,也可以存其他的
};
queue<node>v;
void bfs1(node p)
{
node t,tt;
v.push(p);
while(!v.empty())
{
t=v.front();//取出最前面的
v.pop();//删除
if(找到符合条件的)
{
做记录;
while(!v.empty()) v.pop();//如果后面还需要用,随手清空队列
return;
}
visit[t.x][t.y]=1;//走过的进行标记,以免重复
rep(i,0,4)//做多次查找
{
tt=t;
tt.x+=dir[i][0];tt.y+=dir[i][1];//这里的例子是向上下左右查找的
if(如果这个位置符合条件)
{
tt.bits++;//步数加一
v.push(tt); //把它推入队列,在后面的时候就可以用了
}
}
}
}3.dfs和bfs的区别
其实有时候两个都可以用,不过需要其他的东西来记录什么的,各自有各自的优势
bfs是用来搜索最短径路的解是比较合适的,比如求最少步数的解,最少交换次数的解,因为bfs搜索过程中遇到的解一定是离最初位置最近的,所以遇到一个解,一定就是最优解,此时搜索算法可以终止,而如果用dfs,会搜一些其他的位置,需要搜很多次,然后还要一个东西来记录这次找的位置,之后找到的还要和这次找到的进行比较,这样就比较麻烦
dfs合搜索全部的解,因为要搜索全部的解,在记录路径的时候也会简单一点,而bfs搜索过程中,遇到离根最近的解,并没有什么用,也必须遍历完整棵搜索树。
bfs是浪费空间节省时间,dfs是浪费时间节省空间。因为dfs要走很多的路径,可能都是没用的,(做有些题目的时候要进行剪枝,就是确定不符合条件的就可以结束,以免浪费时间,否则有些题目会TLE);而bfs可以走的点要存起来,需要队列,因此需要空间来储存,但是快一点。
稍微理解之后就可以了,不一定要纠结怎么用,先去做题目,很多都是做着就突然明白怎么用了。
[转帖]dfs和bfs的更多相关文章
- Clone Graph leetcode java(DFS and BFS 基础)
题目: Clone an undirected graph. Each node in the graph contains a label and a list of its neighbors. ...
- 数据结构(12) -- 图的邻接矩阵的DFS和BFS
//////////////////////////////////////////////////////// //图的邻接矩阵的DFS和BFS ////////////////////////// ...
- 数据结构(11) -- 邻接表存储图的DFS和BFS
/////////////////////////////////////////////////////////////// //图的邻接表表示法以及DFS和BFS //////////////// ...
- 在DFS和BFS中一般情况可以不用vis[][]数组标记
开始学dfs 与bfs 时一直喜欢用vis[][]来标记有没有访问过, 现在我觉得没有必要用vis[][]标记了 看代码 用'#'表示墙,'.'表示道路 if(所有情况都满足){ map[i][j]= ...
- 图论中DFS与BFS的区别、用法、详解…
DFS与BFS的区别.用法.详解? 写在最前的三点: 1.所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次. 2.实现bfs和dfs都需要解决的一个问题就是如何存储图.一般有两种方法:邻接矩阵 ...
- 图论中DFS与BFS的区别、用法、详解?
DFS与BFS的区别.用法.详解? 写在最前的三点: 1.所谓图的遍历就是按照某种次序访问图的每一顶点一次仅且一次. 2.实现bfs和dfs都需要解决的一个问题就是如何存储图.一般有两种方法:邻接矩阵 ...
- 数据结构基础(21) --DFS与BFS
DFS 从图中某个顶点V0 出发,访问此顶点,然后依次从V0的各个未被访问的邻接点出发深度优先搜索遍历图,直至图中所有和V0有路径相通的顶点都被访问到(使用堆栈). //使用邻接矩阵存储的无向图的深度 ...
- dfs和bfs的区别
详见转载博客:https://www.cnblogs.com/wzl19981116/p/9397203.html 1.dfs(深度优先搜索)是两个搜索中先理解并使用的,其实就是暴力把所有的路径都搜索 ...
- 邻接矩阵实现图的存储,DFS,BFS遍历
图的遍历一般由两者方式:深度优先搜索(DFS),广度优先搜索(BFS),深度优先就是先访问完最深层次的数据元素,而BFS其实就是层次遍历,每一层每一层的遍历. 1.深度优先搜索(DFS) 我一贯习惯有 ...
随机推荐
- SecureCRT 日记保存带时间戳
%h:%m:%s:%t--- result:
- 如何判断当前脚本运行在node还是浏览器中
判断global对象,如果是window,就是运行在浏览器中,如果global对象是undefined,则运行在node中.
- match 和 search 和 indexOf 查找及 正则表达式的 exec 和 test 用法
function test(){ var name= "1.087"; var abc = "abd wor66k ne78xt"; var reg = /\d ...
- SDOI2019快速查询
链接 vijos 思路 虽然询问1e7,但他询问很有意思,所以最多修改1e5个. 先把他们修改的点缩小到1e5之内并没有什么影响. 然后维护mul和add.不修改很好弄,修改的点可以弄点式子加加减减弄 ...
- 信息学奥赛一本通 提高篇 序列第k个数 及 快速幂
我是传送门 这个题首先是先判断是等差还是等比数列 等差的话非常简单: 前后两个数是等差的,举个栗子: 3 6 9 12 这几个数,(我感觉 1 2 3 4并说明不了什么) 每次都加3嘛,很容易看出,第 ...
- python自动化测试学习目录
一.python学习目录 <1> ----python驱动 [python驱动]python进行selenium测试时GeckoDriver放在什么地方? python下浏览器静默运行驱动 ...
- Debian系Linux 发行版 源配置说明
概述: 本文是在逛论坛是的发现,借鉴过来,以便学习.源列表主文件 /etc/apt/sources.list同时也可创建独立的源配置文件到 /etc/apt/sources.list.d/* 下 so ...
- hotspot的内存
java memory主要分heap memory 和 non-heap memory,其计算公式如下: Max memory = [-Xmx] + [-XX:MaxPermSize] + numbe ...
- ubuntu之路——day17.4 卷积神经网络示例
以上是一个识别手写数字的示例 在这个示例中使用了两个卷积-池化层,三个全连接层和最后的softmax输出层 一般而言,CNN的构成就是由数个卷积层紧跟池化层再加上数个全连接层和输出层来构建网络. 在上 ...
- mysql 导出查询结果
show variables like '%secure%'; 看看导出位置 SELECT * FROM tb WHERE sn = '1' LIMIT 1,10into outfile '/var/ ...