Postgres-XL的限制
Postgres-XL是基于PostgreSQL的一个分布式数据库。
相比于PostgreSQL,XL的表的数据是可以分布到不同的datanode上的,对存在于不同的datanode上的数据进行处理,目前还存在很多限制。当然可能在以后的新版本中,会突破这些限制。
下面针对postgres-xl-10r1版本进行测试,看看目前还存在哪些限制。
1. 分布建不能更新
select * from test2;
id | name
----+------
|
|
|
|
|
( rows) postgres=# update test2 set name='b' where id=;
UPDATE postgres=# update test2 set id= where name='';
-- ::49.533 CST [] ERROR: could not plan this distributed update
-- ::49.533 CST [] DETAIL: correlated UPDATE or updating distribution column currently not supported in Postgres-XL.
-- ::49.533 CST [] STATEMENT: update test2 set id= where name='';
ERROR: could not plan this distributed update
DETAIL: correlated UPDATE or updating distribution column currently not supported in Postgres-XL. postgres=# select * from test2;
id | name
----+------
|
|
| b
|
|
( rows)
2. 复杂查询
在PostgreSQL,表数据只放在一台pc上,当两个表关联查询时,可以直接获取到表数据进行join。但是在Postgres-XL中,表数据是分布在不同的datanode上,datanode又可能分布在不同的pc上;这时候两个表进行关联查询需要从不同的datanode之间进行,如果是多个表进行关联查询,情况更加复杂了。
2.1 非分布键作为条件限制
postgres=# select * from test1,test2;
id | name | id | name
----+------+----+------
| a | |
.
.
.
| b | | b
.
.
.
| d | |
( rows) postgres=# select * from test1,test2 where test1.name='b' and test2.name='b';
id | name | id | name
----+------+----+------
| b | | b
( row) postgres=# select * from test1,test2 where test1.name=test2.name;
-- ::08.939 CST [] ERROR: cannot wait on a latch owned by another process
-- ::08.939 CST [] LOG: server process (PID ) was terminated by signal : Segmentation fault
-- ::08.939 CST [] DETAIL: Failed process was running: Remote Subplan
-- ::08.939 CST [] LOG: terminating any other active server processes
-- ::08.940 CST [] WARNING: terminating connection because of crash of another server process
.
.
.
当where条件中直接判断两个表字段是否相等时,报错。多次尝试后,还出现过其他错误(例如:“ERROR: Couldn't resolve SQueue race condition after 10 tries”),有时候也能执行成功,证明这一查询还是存在很大的问题。
2.2 非亲和表的限制
亲和表,即两张表的分布类型和分布键都一致,称这两张表为亲和表。
表test3和表test4都是以id列作为分布键、分布类型为Modulo,test3和test4是亲和表。
postgres=# \d+ test3
Table "public.test3"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+---------+-----------+----------+-----------------------------------+----------+--------------+-------------
id | integer | | not null | nextval('test3_id_seq'::regclass) | plain | |
name | text | | | | extended | |
Indexes:
"test3_pkey" PRIMARY KEY, btree (id)
Distribute By: MODULO(id)
Location Nodes: ALL DATANODES postgres=# \d+ test4
Table "public.test4"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+---------+-----------+----------+---------+---------+--------------+-------------
id | integer | | | | plain | |
Distribute By: MODULO(id)
Location Nodes: ALL DATANODES postgres=# select * from test3 order by id;
id | name
----+------
| a
| b
| cc
| dd
| ee
| ff
( rows) postgres=# select * from test4 order by id;
id
---- ( rows) postgres=# select * from test4 a inner join test3 b on a.id=b.id order by a.id;
id | id | name
----+----+------
| | a
| | b
| | dd
| | ff
( rows)
下面是非亲和表test2与test4的内连接查询。结果是不正确的,而且有时执行查询会报错。
postgres=# \d+ test2
Table "public.test2"
Column | Type | Collation | Nullable | Default | Storage | Stats target | Description
--------+---------+-----------+----------+---------+----------+--------------+-------------
id | integer | | not null | | plain | |
name | text | | | | extended | |
Indexes:
"test2_pkey" PRIMARY KEY, btree (id)
Distribute By: HASH(id)
Location Nodes: ALL DATANODES postgres=# select * from test2 order by id;
id | name
-----+------
|
| b
|
|
|
|
|
|
( rows) postgres=# select * from test2 a inner join test4 b on a.id=b.id order by a.id;
-- ::19.389 CST [] WARNING: Unexpected data on connection, cleaning.
id | name | id
----+------+----
| b |
| |
| |
( rows)
同样,outer join也存在一样的问题,不支持非亲和表的关联查询。但是,非亲和表可以进行cross join关联查询(没有where条件)。
2.3 子查询限制
子查询也受到非亲和表的限制,与2.2的情况基本一致,就不再去说明了。
特殊说明:2.2和2.3中提到非亲和表的限制问题,我后来增加了一个节点datanode3。结果再进行非亲和表关联时都正常了,没有再报错(上面提到有两个报错),查出来的结果也完全正确。这什么情况,郁闷。后来再尝试把节点datanode3从集群中删掉,也没有重现分亲和表限制的问题。
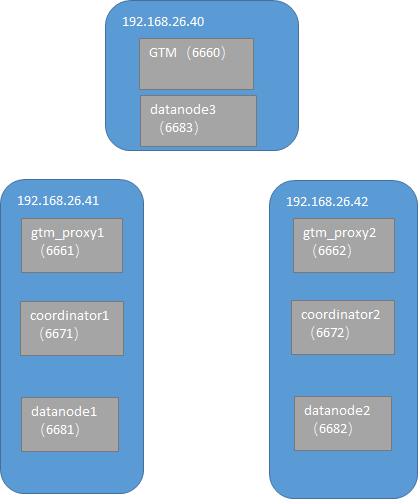
3. 支持特性
这里顺便提一下Postgres-XL支持的特性吧,方便记录一下在测试过程中测试到的项。
- CTE(通用表表达式),支持,但是里面的sql也受到上面提到的限制问题;
- Windows function,支持,同上;
- 集合操作,支持,同上;
- 非分片列count(distinct),支持;
- 支持跨分片更新;
- 支持跨分片事务;
总结
这次针对Postgres-XL去调研它目前存在的限制,主要还是在查询上限制比较大。在测试过程中,没有对所有的sql功能进行测试,也没有太深入去研究。
如果在以上说明存在的限制(或者支持特性)有不符合pgxl实际情况的,可能是我个人的错误,欢迎大牛指出。
希望Postgres-XL在以后的版本中,能把这些限制给解决掉,越做越完善。
Postgres-XL的限制的更多相关文章
- postgres创建表的过程以及部分源码分析
背景:修改pg内核,在创建表时,表名不能和当前的用户名同名. 首先我们知道DefineRelation此函数是最终创建表结构的函数,最主要的参数是CreateStmt这个结构,该结构如下 typede ...
- postgres索引创建、 存储过程的创建以及在c#中的调用
postgres创建索引参考 http://www.cnblogs.com/stephen-liu74/archive/2012/05/09/2298182.html CREATE TABLE tes ...
- postgres扩展开发
扩展开发的基本组成 demo--1.0.sql demo.c demo.control Makefile demo.c当中包含了自定义函数的实现,纯C语言,目录下可包含多个.c文件.demo-1.0. ...
- oracle迁移postgres之-Ora2Pg
描述 Ora2Pg:甲骨文PostgreSQL数据库模式转换器是一个免费的工具用于Oracle数据库迁移到PostgreSQL兼容模式.它连接Oracle数据库,扫描它自动提取其结构或数据,然后生成S ...
- oracle迁移postgres之-oracle_fdw
1. 安装oracle_fdw 在编译安装前,需要设置postgres的环境变量,如在.bash_profile中增加: export ORACLE_HOME=/u01/app/oracle expo ...
- windows安装postgres源代码
http://blog.csdn.net/adrastos/article/details/9093739 1. 下载PostgreSQL的源代码.解压. 2. 在Windows平台下编译需要跳过一个 ...
- postgres 类型转换 cast 转
转自: http://blog.csdn.net/yufenghyc/article/details/45869509 --1 例子postgres=# select 1/4; ?column? -- ...
- POSTGRES与JDBC对照
POSTGRES与JDBC对照 未经验证,仅供参考.
- 常用到的git,mvn,postgres,vim命令总结
mvn: 打包: mvn package 如果想在打包的时候跳过测试: mvn package -Dmaven.test.skip=true 使用的junit测试框架, 测试: mvn test 如果 ...
- postgres 批量更新内容
在程序中遇到这样的需求, 数据库表格式如下 需要把批量更新status, 如name = fox 时, status = 1, name = boa 时,status = 2 .... 类似的 pos ...
随机推荐
- Java8 中的 Optional
从 Java 8 引入的一个很有趣的特性是 Optional 类.Optional 类主要解决的问题是臭名昭著的空指针异常(NullPointerException) —— 每个 Java 程序员都 ...
- Sublime Text 3 配置 sass
先安装Sublime Text的sass 和 sass build插件, Sublime Text新建一个test.scss文件 $color: #369; body { backgroun ...
- Java基础笔记(二)——配置环境变量
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html 到此处下载jdk,并安装.(选 ...
- D. Blocks 数学题
Panda has received an assignment of painting a line of blocks. Since Panda is such an intelligent bo ...
- Zeppelin的入门使用系列之使用Zeppelin来创建临时表UserTable(三)
不多说,直接上干货! 前期博客 Zeppelin的入门使用系列之使用Zeppelin运行shell命令(二) 我们必须要先使用Spark 语句创建临时表UserTable,后续才能使用Spark SQ ...
- 2017年3月14日-----------乱码新手自学.net 之Authorize特性与Forms身份验证(登陆验证、授权小实例)
有段时间没写博客了,最近工作比较忙,能敲代码的时间也不多. 我一直有一个想法,想给单位免费做点小软件,一切思路都想好了,但是卡在一个非常基础的问题上:登陆与授权. 为此,我看了很多关于微软提供的Ide ...
- spring boot + spring data jpa
Spring Data Repository的核心接口是Repository(好像也没什么好惊讶的).这个接口需要领域类(Domain Class)跟领域类的ID类型作为参数.这个接口主要是让你能知道 ...
- 图解HTTP总结
一.TCP/IP 的分层管理 二.TCP/IP通信传输流 ARP地址解析协议参考:https://www.cnblogs.com/csguo/p/7527303.html 三.各种协议与HTTP协议的 ...
- 1、http简介
HTTP 简介 HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本地浏览器的传 ...
- Windows下Python多版本共存
Windows下Python多版本共存 Python数据科学安装Numby,pandas,scipy,matpotlib等(IPython安装pandas) 0.0 因为公司项目,需要Python两个 ...