hadoop--hive数据仓库
一、hive概述

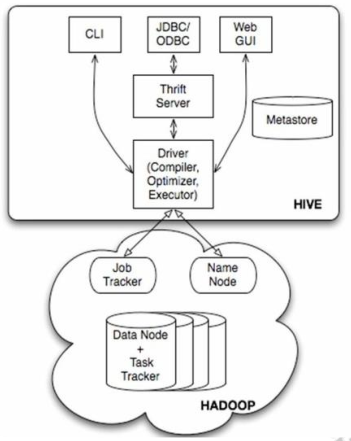
Hive是基于 Hadoop 的一个【数据仓库工具】,可以将结构化的数据文件映射为一张数据库表,并提供简单的 sql 查询功能,可以将 sql 语句转换为 MapReduce 任务进行运行。使用SQL来快速实现简单的MapReduce 统计,不必开发专门的MapReduce 应用,学习成本低,十分适合数据仓库的统计分析。
【数据仓库】英文名称为 Data Warehouse,可简写为 DW 或 DWH。数据仓库,是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。一句话概括: 数据仓库是用来做 查询分析的数据库, 基本不用来做插入,修改,删除操作。
1、数据处理分类
(1)联机事务处理 OLTP(on-linetransaction processing)
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。OLTP系统强调数据库内存效率,强调内存各种指标的命令率,强调绑定变量,强调并发操作;
(2)联机分析处理P OLAP(On-Line AnalyticalProcessing)
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。OLAP系统则强调数据分析,强调SQL执行市场,强调磁盘I/O,强调分区等。
---类比表
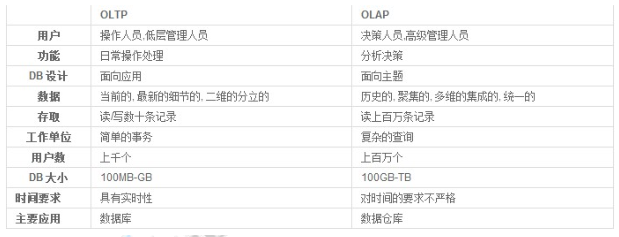
2.hive架构原理
用户接口主要有三个:CLI命令行,Client 和 WUI。
(1)最常用的是 CLI 命令行,Cli启动的时候,会同时启动一个Hive副本; Client是Hive的客户端,用户连接至Hive Server。
在启动Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。 WUI是通过浏览器访问Hive。
(2)Hive将 元数据存储在数据库中,如mysql、 derby 。 Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外
部表等),表的数据所在目录等。
(3)解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,
并在随后有MapReduce调用执行。
(4)Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)
二、hive搭建及三种模式
1.hive的搭建
1.1、安装 Hive安装环境以及前提说明:首先,Hive 是依赖于 hadoop 系统的,因此在运行 Hive 之前需要保证已经搭建好 hadoop 集群环境。
---安装一个关系型数据 mysql

1.2、配置环境变量:(类似于下面这样,跟之前hadoop1 /2.x 配置一样)
– HADOOP_HOME=/**/*
– HIVE_HOME=$*/**/*
1.3、替换和添加相关 jar 包--修改 HADOOP_HOME\share/hadoop/yarn/lib 目录下的 jline-*.jar将其替换成 HIVE_HOME\lib 下的 jline-2.12.jar。
--将 hive 连接 mysql 的 jar 包:mysql-connector-java-5.1.32-bin.jar拷贝到 hive 解压目录的 lib 目录下
1.4、修改配置文件(选择 3 种模式里哪一种)见三种安装模式
1.5、启动 hive:bin/hive
2.三种模式: (内嵌模式/本地模式/远程模式)
2.1 内嵌模式
这种安装模式的元数据是内嵌在Derby数据库中的,只能允许一个会话连接,数据会存放到HDFS上。
这种方式是最简单的存储方式,只需要hive-site.xml做如下配置便可(注:使用 derby 存储方式时,运行 hive 会在当
前目录生成一个 derby 文件和一个 metastore_db)
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:derby:;databaseName=metastore_db;creat
e=true</value> </property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>org.apache.derby.jdbc.EmbeddedDriver</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
2.2 本地模式
这种安装方式和嵌入式的区别在于,不再使用内嵌的 Derby 作为元数据的存储介质,而是使用其他数据库比如 MySQL 来存储元数据且是一个多用户的模式,
运行多个用户 client 连接到一个数据库中。这种方式一般作为公司内部同时使用 Hive。这里有一个前提,每一个用户必须要有对 MySQL 的访问权利,即每
一个客户端使用者需要知道 MySQL 的用户名和密码才行。这种存储方式需要在本地运行一个 mysql 服务器,并作如下配置(下面两种使用 mysql 的方式,
需要将 mysql 的 jar 包拷贝到$HIVE_HOME/lib 目录下)。
注: mysql-connector-java-5.1.32-bin.jar拷贝到 hive 解压目录的 lib 目录下
(jar包 链接:https://pan.baidu.com/s/17LzbGrLpLAcs-guXz2ttLg 密码:4k6w)
vim hive-site-xml 配置如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<!--数据仓库的位置,默认是/user/hive/warehouse-->
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive_rlocal/warehouse</value>
</property>
<property>
<!--控制hive是否连接一个远程metastore服务器还是开启一个本地客户端jvm-->
<name>hive.metastore.local</name>
<value>true</value>
</property>
<property>
<!--JDBC连接字符串,默认jdbc:derby:;databaseName=metastore_db;create=true-->
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node03/hive_remote?createDatabaseIfNotExist=t
rue</value>
</property>
<property>
<!--JDBC的driver,默认org.apache.derby.jdbc.EmbeddedDriver-->
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<!--username,默认APP-->
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
启动:
①开启集群(hive需要依赖集群); service iptables stop zkServer.sh start start-all.sh
②开启mysql服务器:先在mysql中链接到客户端,本机创建的数据库名为hive

再到客户端:service mysqld start -----> mysql -u root -p (用户名/密码)
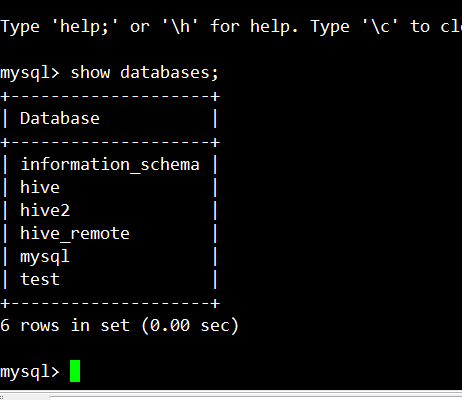
③启动hive: 执行hive
小试牛刀:
创建一个数据库:zhangsan hive> show databases;
OK
default
wuxiong
Time taken: 0.051 seconds, Fetched: 2 row(s)
hive> create database zhangsan;
OK
Time taken: 0.113 seconds
hive> show databases;
OK
default
wuxiong
zhangsan
Time taken: 0.046 seconds, Fetched: 3 row(s)
hive>
是否生效:①查看集群对应的目录 : hive-site-xml配置文件中已定义了目录的存放位置:/user/hive/warehouse ------>打开node02节点(active)
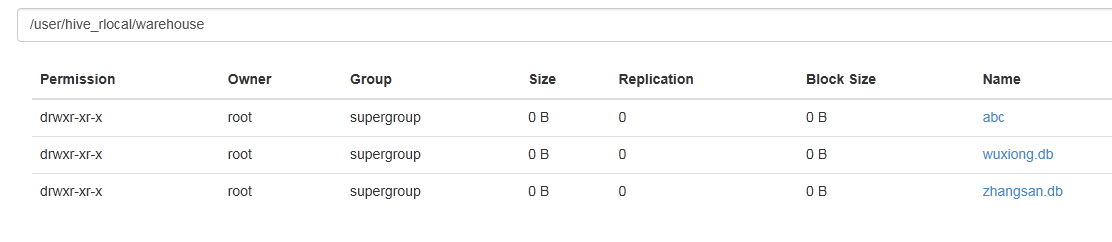
②本地mysql数据库hive中查看:hive_remote ----->dbs----->会发现:

ok,数据库创建完毕!存放位置也能找到!
接上述'zhangsan'数据库继续创建一张表:
use zhangsan;
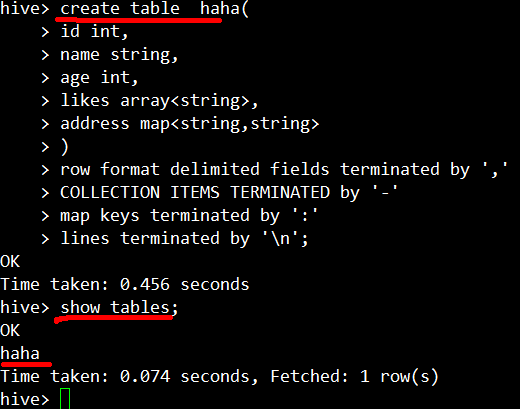
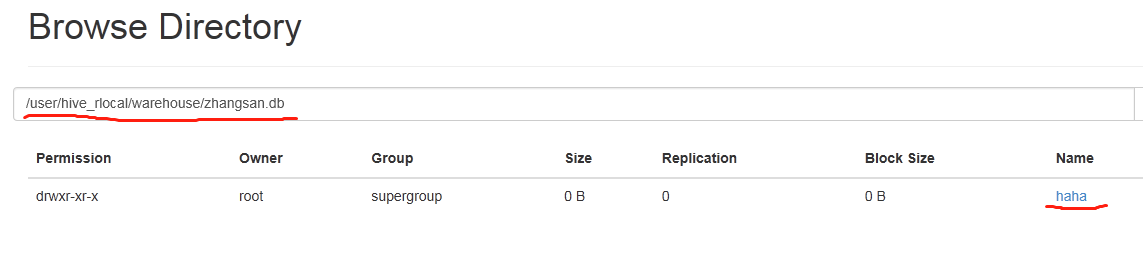
查找:①mysql--->hive----->hive_remote------>TBLS

②集群中:
2.3 远程模式
remote:这种存储方式需要在远端服务器运行一个 mysql 服务器,并且需要在 Hive 服务器启动 meta服务。本机配置了
三个节点:node01、node02、node03,node01上已配置了mysql,现在以node02为服务端,node03为客户端依次配置系统文件
hive-site.xml
node02配置如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node01:3306/hive2?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>
node03配置如下:
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node01:9083</value>
</property>
</configuration>
启动:
node02 (服务端): hive --server metastore
node03(客户端):启动 hive
hadoop--hive数据仓库的更多相关文章
- Hive -- 基于Hadoop的数据仓库分析工具
Hive是一个基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库 ...
- Hive和SparkSQL: 基于 Hadoop 的数据仓库工具
Hive: 基于 Hadoop 的数据仓库工具 前言 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,将类 SQL 语句转 ...
- 基于Hadoop的数据仓库Hive
Hive是基于Hadoop的数据仓库工具,可对存储在HDFS上的文件中的数据集进行数据整理.特殊查询和分析处理,提供了类似于SQL语言的查询语言–HiveQL,可通过HQL语句实现简单的MR统计,Hi ...
- 大数据之路week07--day05 (一个基于Hadoop的数据仓库建模工具之一 HIve)
什么是Hive? 我来一个短而精悍的总结(面试常问) 1:hive是基于hadoop的数据仓库建模工具之一(后面还有TEZ,Spark). 2:hive可以使用类sql方言,对存储在hdfs上的数据进 ...
- Hadoop Hive基础sql语法
目录 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件映射为一张数据库表,并提供完整的 ...
- Hadoop Hive概念学习系列之什么是Hive?(一)
参考 <Hadoop大数据分析与挖掘实战>的在线电子书阅读 http://yuedu.baidu.com/ebook/d128cf8e33687e21 ...
- Hadoop Hive与Hbase整合+thrift
Hadoop Hive与Hbase整合+thrift 1. 简介 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句 ...
- Hadoop Hive sql语法详解
Hadoop Hive sql语法详解 Hive 是基于Hadoop 构建的一套数据仓库分析系统,它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,可以将结构 化的数据文件 ...
- Hadoop Hive与Hbase关系 整合
用hbase做数据库,但因为hbase没有类sql查询方式,所以操作和计算数据很不方便,于是整合hive,让hive支撑在hbase数据库层面 的 hql查询.hive也即 做数据仓库 1. 基于Ha ...
- Hadoop Hive sql 语法详细解释
Hive 是基于Hadoop 构建的一套数据仓库分析系统.它提供了丰富的SQL查询方式来分析存储在Hadoop 分布式文件系统中的数据,能够将结构 化的数据文件映射为一张数据库表,并提供完整的SQL查 ...
随机推荐
- reentrantlock用于替代synchronized
1.①使用reentrantlock可以完成同样的功能 ②需要注意的是,必须要必须要必须要手动释放锁(重要的事情说三遍) ③使用syn锁定的话如果遇到异常,jvm会自动释放锁,但是lock必须 ...
- new 关键字
学习过的调用或者是执行函数的方式有几种? ①函数名+小括号 ②事件处理函数 ③定时器 ④数组里面的元素是函数,枚举出来执行 ⑤new关键字 提示:需要注意new 关键字需要在函数名前面使用 构造函数是 ...
- java实现Kafka的消费者示例
使用java实现Kafka的消费者 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 3 ...
- Multiple Database Block Sizes and the Buffer Cache
In oracle 10g we can have multiple block sizes at the same time. When a tablespace is created we can ...
- LeetCode题解之Number of 1 Bits
1.题目描述 2.问题分析 使用C++ 标准库的 bitset 类,将整数转换为 二进制,然后将二进制表示转换为字符串,统计字符串中 1 的个数即可. 3.代码 int hammingWeight(u ...
- selenium&phantomjs实战--漫话爬取
为什么直接保存当前网页,而不是找到所有漫话链接,再有针对性的保存图片? 因为防盗链的原因,当直接保存漫话链接图片时,只能保存到防盗链的图片. #!/usr/bin/env python # _*_ c ...
- Elasticsearch安装记录
一 安装部分 1.新建用户 elasticsearch不能使用root身份执行 adduser esuser passwd esuser 2.赋予权限 切换到root chown -R esuser ...
- 使用CocoaPods
使用CocoaPods 1. 安装CocoaPods 有时候,默认的 https://rubygems.org/ 访问不了,你需要先执行以下命令移除掉sources gem sources -r ht ...
- UNIX高级环境编程(1)File I/O
引言: Unix系统中主要的文件操作包括: open read write lseek close unbuffered IO和standard I/O相对应,后面的章节我们会讨论这两者的区别. 在讨 ...
- QuickBI助你成为分析师-数据建模(一)
摘要: 数据集编辑功能界面介绍以及常见问题总结. 在数据集编辑界面可以进行数据建模来更好的展示数据,创建数据集默认将数值类型字段作为度量,日期.字符串等类型作为维度,度量可以根据维度分组展示.下面来介 ...