python 爬虫学习<将某一页的所有图片下载下来>
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。
我们最常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过截图工具截取下来,但这样就降低图片的清晰度。好吧~!其实你很厉害的,右键查看页面源代码。
我们可以通过python 来实现这样一个简单的爬虫功能,把我们想要的代码爬取到本地。下面就看看如何使用python来实现这样一个功能。
一,获取整个页面数据
首先我们可以先获取要下载图片的整个页面信息。
getjpg.py

#coding=utf-8
import urllib def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html html = getHtml("http://tieba.baidu.com/p/2738151262") print html
Urllib 模块提供了读取web页面数据的接口,我们可以像读取本地文件一样读取www和ftp上的数据。首先,我们定义了一个getHtml()函数:
urllib.urlopen()方法用于打开一个URL地址。
read()方法用于读取URL上的数据,向getHtml()函数传递一个网址,并把整个页面下载下来。执行程序就会把整个网页打印输出。
二,筛选页面中想要的数据
Python 提供了非常强大的正则表达式,我们需要先要了解一点python 正则表达式的知识才行。
http://www.cnblogs.com/fnng/archive/2013/05/20/3089816.html
假如我们百度贴吧找到了几张漂亮的壁纸,通过到前段查看工具。找到了图片的地址,如:src=”http://imgsrc.baidu.com/forum......jpg”pic_ext=”jpeg”
修改代码如下:
import re
import urllib def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
return imglist html = getHtml("http://tieba.baidu.com/p/2460150866")
print getImg(html)
我们又创建了getImg()函数,用于在获取的整个页面中筛选需要的图片连接。re模块主要包含了正则表达式:
re.compile() 可以把正则表达式编译成一个正则表达式对象.
re.findall() 方法读取html 中包含 imgre(正则表达式)的数据。
运行脚本将得到整个页面中包含图片的URL地址。
三,将页面筛选的数据保存到本地
把筛选的图片地址通过for循环遍历并保存到本地,代码如下:
#coding=utf-8
import urllib
import re def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html def getImg(html):
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1 html = getHtml("http://tieba.baidu.com/p/2460150866") print getImg(html)
这里的核心是用到了urllib.urlretrieve()方法,直接将远程数据下载到本地。
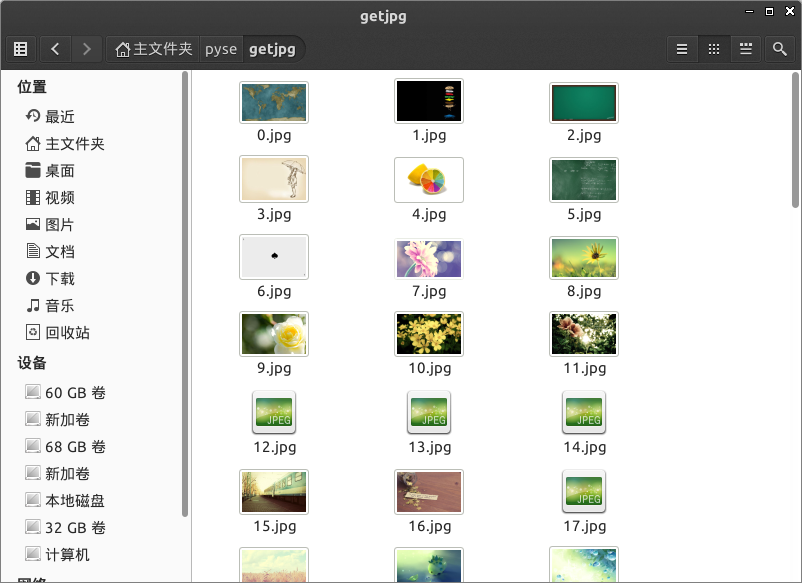
通过一个for循环对获取的图片连接进行遍历,为了使图片的文件名看上去更规范,对其进行重命名,命名规则通过x变量加1。保存的位置默认为程序的存放目录。
程序运行完成,将在目录下看到下载到本地的文件。
python 爬虫学习<将某一页的所有图片下载下来>的更多相关文章
- python爬虫学习(1) —— 从urllib说起
0. 前言 如果你从来没有接触过爬虫,刚开始的时候可能会有些许吃力 因为我不会从头到尾把所有知识点都说一遍,很多文章主要是记录我自己写的一些爬虫 所以建议先学习一下cuiqingcai大神的 Pyth ...
- python爬虫学习 —— 总目录
开篇 作为一个C党,接触python之后学习了爬虫. 和AC算法题的快感类似,从网络上爬取各种数据也很有意思. 准备写一系列文章,整理一下学习历程,也给后来者提供一点便利. 我是目录 听说你叫爬虫 - ...
- Python爬虫学习:三、爬虫的基本操作流程
本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:三.爬虫的基本操作与流程 一般我们使用Python爬虫都是希望实现一套完整的功能,如下: 1.爬虫目标数据.信息: 2.将 ...
- Python爬虫学习:四、headers和data的获取
之前在学习爬虫时,偶尔会遇到一些问题是有些网站需要登录后才能爬取内容,有的网站会识别是否是由浏览器发出的请求. 一.headers的获取 就以博客园的首页为例:http://www.cnblogs.c ...
- Python爬虫学习:二、爬虫的初步尝试
我使用的编辑器是IDLE,版本为Python2.7.11,Windows平台. 本文是博主原创随笔,转载时请注明出处Maple2cat|Python爬虫学习:二.爬虫的初步尝试 1.尝试抓取指定网页 ...
- 《Python爬虫学习系列教程》学习笔记
http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多.学习过程中我把一些学习的笔记总结下来,还记录了一些自己 ...
- python爬虫学习视频资料免费送,用起来非常666
当我们浏览网页的时候,经常会看到像下面这些好看的图片,你是否想把这些图片保存下载下来. 我们最常规的做法就是通过鼠标右键,选择另存为.但有些图片点击鼠标右键的时候并没有另存为选项,或者你可以通过截图工 ...
- python爬虫学习笔记(一)——环境配置(windows系统)
在进行python爬虫学习前,需要进行如下准备工作: python3+pip官方配置 1.Anaconda(推荐,包括python和相关库) [推荐地址:清华镜像] https://mirrors ...
- [转]《Python爬虫学习系列教程》
<Python爬虫学习系列教程>学习笔记 http://cuiqingcai.com/1052.html 大家好哈,我呢最近在学习Python爬虫,感觉非常有意思,真的让生活可以方便很多. ...
随机推荐
- 爬虫基础---HTTP协议理解、网页的基础知识、爬虫的基本原理
一.HTTP协议的理解 URL和URI 在学习HTTP之前我们需要了解一下URL.URI(精确的说明某资源的位置以及如果去访问它) URL:Universal Resource Locator 统一资 ...
- Python 文件IO
Python 文件I/O 打印到屏幕 最简单的输出方法是用print语句,你可以给它传递零个或多个用逗号隔开的表达式.此函数把你传递的表达式转换成一个字符串表达式,并将结果写到标准输出如下: #!/u ...
- Code Conventions for the JavaScript Programming Language
This is a set of coding conventions and rules for use in JavaScript programming. It is inspired by t ...
- Codeforces 948C Producing Snow(优先队列+思维)
题目链接:http://codeforces.com/contest/948/problem/C 题目大意:给定长度n(n<=1e5),第一行v[i]表示表示第i堆雪的体积,第二行t[i]表示第 ...
- Codeforces 807C - Success Rate(二分枚举)
题目链接:http://codeforces.com/problemset/problem/807/C 题目大意:给你T组数据,每组有x,y,p,q四个数,x/y是你当前提交正确率,让你求出最少需要再 ...
- MySQL学习笔记:coalesce
函数:coalesce 作用:返回传入的参数中第一个非NULL的值 ); # ); # 如果传入的参数所有都是NULL,则返回NULL,比如: SELECT COALESCE(NULL, NULL, ...
- Python 安装 pytesser 处理验证码出现的问题
今天这个问题困扰了我好久,开始直接用 pip install pytesseract 安装了 pytesseract 然后出现了如下错误 Traceback (most recent call las ...
- Azkaban(三)Azkaban的使用
界面介绍 首页有四个菜单 projects:最重要的部分,创建一个工程,所有flows将在工程中运行. scheduling:显示定时任务 executing:显示当前运行的任务 history:显示 ...
- CF455D. Serega and Fun
D. Serega and Fun time limit per test 4 seconds memory limit per test 256 megabytes input standard i ...
- Codeforces 429C Guess the Tree(状压DP+贪心)
吐槽:这道题真心坑...做了一整天,我太蒻了... 题意 构造一棵 $ n $ 个节点的树,要求满足以下条件: 每个非叶子节点至少包含2个儿子: 以节点 $ i $ 为根的子树中必须包含 $ c_i ...