python开发_xml.dom_解析XML文档_完整版_博主推荐
在阅读之前,你需要了解一些xml.dom的一些理论知识,在这里你可以对xml.dom有一定的了解,如果你阅读完之后。
下面是我做的demo
运行效果:
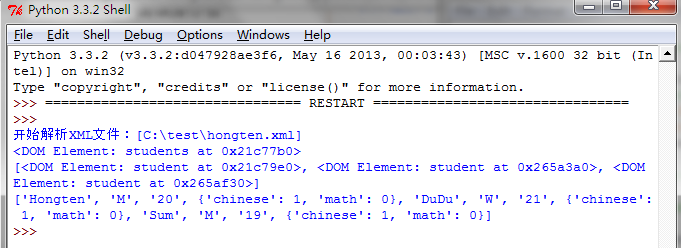
解析的XML文件位置:c:\\test\\hongten.xml
<?xml version="1.0" encoding="UTF-8"?>
<students>
<student no="2009081097">
<name>Hongten</name>
<gender>M</gender>
<age>20</age>
<score subject="math">97</score>
<score subject="chinese">90</score>
</student>
<student no="2009081098">
<name>DuDu</name>
<gender>W</gender>
<age>21</age>
<score subject="math">87</score>
<score subject="chinese">96</score>
</student>
<student no="2009081099">
<name>Sum</name>
<gender>M</gender>
<age>19</age>
<score subject="math">64</score>
<score subject="chinese">98</score>
</student>
</students>
====================================================
代码部分:
====================================================
#python xml.dom #Author : Hongten
#Mailto : hongtenzone@foxmail.com
#Blog : http://www.cnblogs.com/hongten
#QQ : 648719819
#Version : 1.0
#Create : 2013-09-03 import os
from xml.dom import minidom #global var
SHOW_LOG = True
XML_PATH = None def get_dom_by_parse(path):
'''根据XML文件地址解析XML文件,返回dom对象'''
if os.path.exists(path):
if SHOW_LOG:
print('开始解析XML文件:[{}]'.format(path))
return minidom.parse(path)
else:
print('the path [{}] dose not exist!'.format(path)) def get_dom_by_file(path):
'''解析作为文档打开的XML文件'''
if os.path.exists(path):
if SHOW_LOG:
print('开始打开XML文件:[{}]'.format(path))
with open(path) as pf:
if SHOW_LOG:
print('开始解析XML文件:[{}]'.format(path))
return minidom.parse(pf)
else:
print('the path [{}] dose not exist!'.format(path)) def get_dom_by_string(s):
'''解析以字符串形式的XML数据格式'''
if s is not None and s != '':
if SHOW_LOG:
print('开始解析字符串形式的XML数据:[{}]'.format(s))
return minidom.parseString(s)
else:
print('the input string is None or equals \'\'.') def get_root(dom):
'''返回XML文件的根节点'''
if dom is not None:
return dom.documentElement
else:
print('the dom is None!') def get_element_children(fatherElement, subNodeName):
'''根据父节点fatherElement获取子节点subNodeName'''
if fatherElement is not None:
if subNodeName is not None and subNodeName != '':
return fatherElement.getElementsByTagName(subNodeName)
else:
print('the sub node name is None or equals \'\'.')
else:
print('the father node is None!') def get_element_value(element, index=0):
'''获取节点的值'''
if element is not None:
return element.childNodes[index].nodeValue
else:
print('the element is None!') def get_element_attrib_value(element, name):
'''根据节点element的属性名称name获取属性名称的值'''
if element is not None:
if name is not None and name != '':
return element.getAttribute(name)
else:
print('the name is None or equals \'\'.')
else:
print('the element is None!') def get_info(root_children):
'''解析XML内容'''
info = []
for item in root_children:
subs = []
score_value = []
i_no = get_element_attrib_value(item, 'no')
i_name = get_element_children(item, 'name')
i_gender = get_element_children(item, 'gender')
i_age = get_element_children(item, 'age')
i_score = get_element_children(item, 'score')
for sub in i_score:
i_sub = get_element_attrib_value(sub, 'subject')
subs.append(i_sub) v_name = get_element_value(i_name[0])
v_gender = get_element_value(i_gender[0])
v_age = get_element_value(i_age[0])
for s in range(len(i_score)):
score_value.append(s)
v_score = dict(zip(subs, score_value))
info.append(v_name)
info.append(v_gender)
info.append(v_age)
info.append(v_score)
return info def init():
global SHOW_LOG
SHOW_LOG = True
global XML_PATH
XML_PATH = 'C:\\test\\hongten.xml' def main():
init()
dom = get_dom_by_parse(XML_PATH)
root = dom.documentElement
print(root)
root_children = get_element_children(root, 'student')
print(root_children)
info = get_info(root_children)
print(info) if __name__ == '__main__':
main()
python开发_xml.dom_解析XML文档_完整版_博主推荐的更多相关文章
- python优秀库 - 使用xmltodict解析xml文档
上次讲到如何使用BeautifulSoup解析XML文档,今天发现另外一个python库xmltodict(https://github.com/martinblech/xmltodict)也很简单. ...
- Objective-C ,ios,iphone开发基础:使用GDataXML解析XML文档,(libxml/tree.h not found 错误解决方案)
使用GDataXML解析XML文档 在IOS平台上进行XML文档的解析有很多种方法,在SDK里面有自带的解析方法,但是大多情况下都倾向于用第三方的库,原因是解析效率更高.使用上更方便 这里主要介绍一下 ...
- 四种生成和解析XML文档的方法详解(介绍+优缺点比较+示例)
众所周知,现在解析XML的方法越来越多,但主流的方法也就四种,即:DOM.SAX.JDOM和DOM4J 下面首先给出这四种方法的jar包下载地址 DOM:在现在的Java JDK里都自带了,在xml- ...
- 浅谈用java解析xml文档(四)
继续接上一文,这一阵子因为公司项目加紧,导致最后一个解析xml文档的方式,还没有总结,下面总结使用dom4J解析xml. DOM4J(Document Object Model for Java) 使 ...
- 浅谈用java解析xml文档(二)
上一文中总结了dom解析xml文档的方式,本文开始总结使用SAX解析xml 的方式及它的优缺点! SAX(Simple API for XML),是指一种接口,或者一个软件包. 首先我们应该知道SAX ...
- DOM4J解析XML文档
Tip:DOM4J解析XML文档 Dom4j是一个简单.灵活的开放源代码的库.Dom4j是由早期开发JDOM的人分离出来而后独立开发的.与JDOM不同的是,dom4j使用接口和抽象基类,虽然Dom4j ...
- dom4j解析xml文档全面介绍
一.dom4j介绍 dom4j是一个Java的XML API,类似于jdom,用来读写XML文件的.dom4j是一个非常非常优秀的Java XML API,具有性能优异.功能强大和极端易用使用的特点, ...
- 四种生成和解析XML文档的方法详解
众所周知,现在解析XML的方法越来越多,但主流的方法也就四种,即:DOM.SAX.JDOM和DOM4J 下面首先给出这四种方法的jar包下载地址 DOM:在现在的Java JDK里都自带了,在xml- ...
- Java高级特性 第14节 解析XML文档(2) - SAX 技术
一.SAX解析XML文档 SAX的全称是Simple APIs for XML,也即XML简单应用程序接口.与DOM不同,SAX提供的访问模式是一种顺序模式,这是一种快速读写XML数据的方式.当使用S ...
随机推荐
- ubuntu 18.04 安装 flash
下载源码包, 解压 sudo cp Downloads/flash_player_npapi_linux.x86_64/libflashplayer.so /usr/lib/mozilla/plugi ...
- 关于mysql的wait_timeout参数 设置不生效的问题【转】
关于wait_timeout 有一次去online set wait_timeout 的时候发现改了不生效,如下: mysql> show variables like 'wait_timeou ...
- Nagios Openstack Plugin
Some simple example for checking Openstack services check nova service list #!/bin/sh export OS_PROJ ...
- 洛谷P1411 砝码称重
传送门啦 这个题总体思路就是先搜索在 $ dp $ void dfs(int keep,int now){ //使用 放弃 if(now > m) return; //已经放弃超过m个了,就退出 ...
- 云计算IaaS浅谈
(本篇文章仅仅是整理文档资料时,发现的一篇课程报告,感觉还挺有参考意义的) 最近几年云计算一直是IT业的热点,一股炽热的云计算浪潮席卷了世界,全世界都在讲云计算,都在搞云计算.虽然最初是由谷歌公司提出 ...
- wpf 在Popup内的TextBox 输入法 不能切换
切换输入法 输入不了中文 [DllImport("User32.dll")] public static extern IntPtr SetFocus(IntPtr hWnd); ...
- epoll对poll(select)的改进
select的几大缺点: 每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大: 每次调用select,内核需要遍历传递进来的所有fd(判断检测文件是否可用).有 ...
- ssm使用Ajax的formData进行异步图片上传返回图片路径,并限制格式和大小
之前整理过SSM的文件上传,这次直接用代码了. 前台页面和js //form表单 <form id= "uploadForm" enctype="multipart ...
- MEF实现设计上的“松耦合”(二)
介绍了下MEF的基础用法,让我们对MEF有了一个抽象的认识.当然MEF的用法可能不限于此,比如MEF的目录服务.目录筛选.重组部件等高级应用在这里就不做过多讲解,因为博主觉得这些用法只有在某些特定的环 ...
- 在MVC中如何使用vs2013编译调试razor cshtml
打开mvc项目的csproj文件: <MvcBuildViews>false</MvcBuildViews> 改为 <MvcBuildViews>true</ ...