Kioskcached(1)之 Memcached & Redis & Kioskcached 性能测试对比
前言:本文仅仅是作者自己在学习过程中的一次实验而已,或许因为各种因素会导致实验结果与你之前的认知不太一样,因此请你带着批判的眼光看待本文(本文不具有实际环境的参考性)。
一:测试目的
在了解了一些NoSQL的知识之后,我发现Memcached是一个多线程的模型,对于一个NoSQL数据库,如果不考虑数据持久化功能(读写磁盘),剩余的内存操作应该是非常快的。但是多线程就意味着需要互斥和同步,锁是必须的,因此我设想多线程或许还会影响其性能而没有单线程快,这也是我为了验证自己的想法做的测试,因此也有了我标题中提到的我自己的项目 Kioskcached——一款单线程的简易key-value数据库。
二:测试环境
OS : RedHat 7
Kernel : Linux version 3.10.0-514.el7.x86_64
CPU : Intel(R) Core(TM) i5 CPU M 520 @ 2.40GHz
Mem : 8G//备注:除了测试三个数据库的QPS,我还使用Google的 gperftools 工具我的项目做了
CPU PROFILER,找出了代码中占用CPU最多的函数,并考虑优化它。
三:测试过程及结果
1.Memcached
1:启动Memcached,使用默认大小64M就够了,我们存取的数据量大概是10M左右,(100B(key+value)*100000(nums) = 10M)。

2:测试代码如下:
https://github.com/yangbodong22011/kioskcached/tree/master/test/Memcached
3: 编译运行
$ g++ testFoot.cpp -lmemcached -lprofiler
$ ./a.out 100000 //插入10万条数据
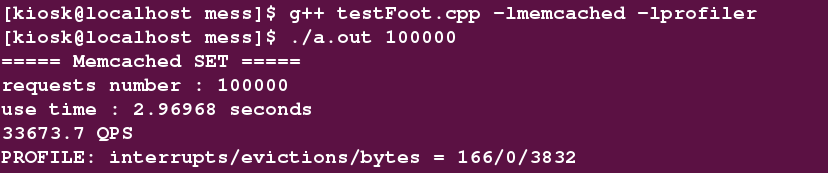
测试得到 QPS 为: 33673.7
2.Redis
1:源码安装Redis之后,./redis-server启动Redis服务器
2:在src目录下有 redis-benchmark 可执行文件,这是官方自带的Redis性能测试工具。
$ ./redis-benchmark -h 127.0.0.1 -c 1 -n 100000 -d 100
-c : client的数量,1表示只有一个客户端
-n : 100000 : 表示10万次请求
-d : 100 : 表示一次数据量为100字节
3:测试结果
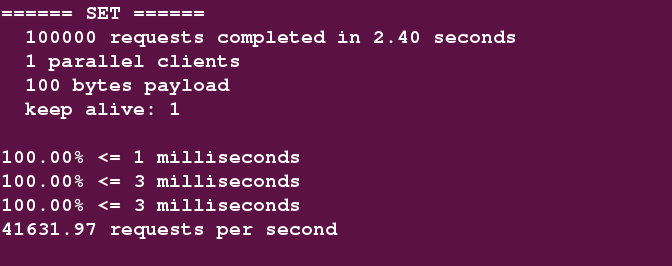
测试得到 QPS 为: 41631.97
3.Kioskcached
1:一款内存缓存型数据库,采用C/C++开发,网络库部分使用Redis源码,单线程IO多路复用模型避免了锁的争用,保证了操作的原子性。使用C++11 unordered_set管理内存数据结构。
2: Kioskcached的测试情况:
- 当value的值为100字节时 : QPS = 316275

使用gperftools找出使用CPU前几位的函数为:

$ cat output.txt
Total: 259 samples
34 13.1% 13.1% 56 21.6% std::_Hashtable::_M_find_before_node
21 8.1% 21.2% 22 8.5% _int_malloc
17 6.6% 27.8% 23 8.9% std::_Hashtable::_M_rehash_aux
...... 剩余的省略输出结果说明(按照列数往下):
| 序号 | 说明 |
|---|---|
| 1 | 分析样本数量(不包含其他函数调用) |
| 2 | 分析样本百分比(不包含其他函数调用) |
| 3 | 目前为止的分析样本百分比(不包含其他函数调用) |
| 4 | 分析样本数量(包含其他函数调用) |
| 5 | 分析样本百分比(包含其他函数调用) |
| 6 | 函数名 |
- 当value的值为1000字节时 : QPS = 203203
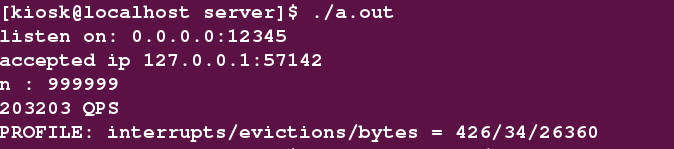
使用gperftools找出使用CPU前几位的函数为:
Total: 426 samples
78 18.3% 18.3% 78 18.3% __read_nocancel
64 15.0% 33.3% 70 16.4% _int_malloc
28 6.6% 39.9% 57 13.4% std::_Hashtable::_M_find_before_node
...... 剩余的省略
可以发现与100字节相比较,此时read系统调用占用CPU已经成为了第一。- 当value的值为10000字节时

使用gperftools找出使用CPU前几位的函数为:
Total: 521 samples
102 19.6% 19.6% 102 19.6% __read_nocancel
79 15.2% 34.7% 83 15.9% _int_malloc
42 8.1% 42.8% 42 8.1% __GI_epoll_wait
29 5.6% 48.4% 52 10.0% std::_Hashtable::_M_find_before_node
malloc 还是我们的难题和瓶颈。
...... 剩余的省略
3 : 总结
可以看出像:
_int_malloc
std::_Hashtable::_M_find_before_node
std::_Hashtable::_M_rehash_aux
__read_nocancel这些都消耗非常多的CPU,要是优化的话先从它们入手,我自己可以处理的是malloc 和 std::_Hashtable::_M_find_before_node。
四:改进方法
- 重新找寻Hash函数,做适配替代目前的Hash函数。
- 使用tcmalloc等第三方性能优于glibc ptmalloc的内存分配器。
[完]
Kioskcached(1)之 Memcached & Redis & Kioskcached 性能测试对比的更多相关文章
- Python自动化 【第十一篇】:Python进阶-RabbitMQ队列/Memcached/Redis
本节内容: RabbitMQ队列 Memcached Redis 1. RabbitMQ 安装 http://www.rabbitmq.com/install-standalone-mac.htm ...
- PostgreSQL单机、同步复制、异步复制性能测试对比
测试环境: •测试机:PC •内存:8GB •CPU:Intel(R) Core(TM) i5-3450 3.10GHz •硬盘:HDD •数据量:20GB •测试工具:pgbench •Postgr ...
- [转帖]Docker五种存储驱动原理及应用场景和性能测试对比
Docker五种存储驱动原理及应用场景和性能测试对比 来源:http://dockone.io/article/1513 作者: 陈爱珍 布道师@七牛云 Docker最开始采用AUFS作为文件系统 ...
- redis、rabitmq对比
redis.rabitmq对比 原文地址 简要介绍 RabbitMQ RabbitMQ是实现AMQP(高级消息队列协议)的消息中间件的一种,最初起源于金融系统,用于在分布式系统中存储转发消息,在易用性 ...
- tcmalloc jemalloc glibc内存分配管理模块性能测试对比
tcmalloc是谷歌提供的内存分配管理模块 jemalloc是FreeBSD提供的内存分配管理模块 glibc是Linux提供的内存分配管理模块 并发16个线程,分配压测3次,每次压15分钟,可以看 ...
- sqlsugar freesql hisql 三个ORM框架性能测试对比
hisql与目前比较流行的ORM框架性能测试对比 总体测试结果 插入记录数 hisql(耗时) sqlsugar(耗时) freesql(耗时) 5条 0.0107秒 0.0312秒 0.02675秒 ...
- c# sqlsugar,hisql,freesql orm框架全方位性能测试对比 sqlserver 性能测试
在2022年1月份本人做过一次sqlsugar,hisql,freesql三个框架的性能测试,上次主要是测的sqlserver下的常规插入(非bulkcopy的方式数据插入),hisql与目前比较流行 ...
- memcached与redis实现的对比
版权声明:本文由田京昆原创文章,转载请注明出处: 文章原文链接:https://www.qcloud.com/community/article/129 来源:腾云阁 https://www.qclo ...
- 内存数据库:memcached与redis技术的对比试验
本文以高性能nginx服务器为应用背景,想利用缓存技术来减轻系统负荷,加快响应时间,从而增加web服务器的吞吐量. redis是一种分布式内存数据库,memcached是一种内存缓存技术,它们都采用k ...
随机推荐
- Shell系列(24)- 条件判断之文件类型
按照文件类型进行判断 标红,记住:其他了解即可 测试选项 作用 -b 文件 判断该文件是否存在,并且是否为块设备文件(是块设备文件为真) -c 文件 判断该文件是否存在,并且是否为字符设备文件(是字符 ...
- iNeuOS工业互联网操作系统部署在华为欧拉(openEuler)国产系统,vmware、openEuler、postgresql、netcore、nginx、ineuos一站式部署
目 录 1. 概述... 3 2. 创建虚拟机&安装华为欧拉(openEuler)系统... 4 2.1 创建新的虚拟机... 4 2.2 ...
- IdentityServer4[5]简化模式
Implicit简化模式(直接通过浏览器的链接跳转申请令牌) 简化模式是相对于授权码模式而言的.其不再需要[Client]的参与,所有的认证和授权都是通过浏览器来完成的. 创建项目 IdentityS ...
- JVM-直接内存(Direct Memory)
1.直接内存概述 直接内存不是虚拟机运行时数据区的一部分,也不是<Java虚拟机规范>中定义的内存区域. 直接内存是在Java堆外的,直接向系统申请的内存区间. 来源于NIO,通过存在堆中 ...
- scheduler源码分析——调度流程
前言 当api-server处理完一个pod的创建请求后,此时可以通过kubectl把pod get出来,但是pod的状态是Pending.在这个Pod能运行在节点上之前,它还需要经过schedule ...
- apiserver源码分析——处理请求
前言 上一篇说道k8s-apiserver如何启动,本篇则介绍apiserver启动后,接收到客户端请求的处理流程.如下图所示 认证与授权一般系统都会使用到,认证是鉴别访问apiserver的请求方是 ...
- android-- 按需打包的框架搭建--新手教程
1, 新建项目VariantTest 2, 生成keystore 可以看到, 默认的build variant只有debug一种 当我试图选release的时候,发现报错了 什么错呢 大致意思是说我们 ...
- bzoj3073Journeys(线段树优化最短路)
这里还是一道涉及到区间连边的问题. 如果暴力去做,那么就会爆炸 那么这时候就需要线段树来优化了. 因为是双向边 所以需要两颗线段树来分别对应入边和出边 QwQ然后做就好了咯 不过需要注意的是,这个边数 ...
- 开源协同OA办公平台教程:O2OA服务管理中,接口的调用权限
本文介绍O2OA服务管理中,接口的权限设定和调用方式. 适用版本:5.4及以上版本 创建接口 具有服务管理设计权限的用户(具有ServiceManager角色或Manager角色)打开" ...
- 这部分布式事务开山之作,凭啥第一天预售就拿下当当新书榜No.1?
大家好,我是冰河~~ 今天,咱们就暂时不聊[精通高并发系列]了,今天插播一下分布式事务,为啥?因为冰河联合猫大人共同创作的分布式事务领域的开山之作--<深入理解分布式事务:原理与实战>一书 ...