SQLFlow数据流分析工具的job功能介绍
SQLFlow是一款专业的数据血缘关系分析工具,在大型数据仓库中,完整的数据血缘关系可以用来进行数据溯源、表和字段变更的影响分析、数据合规性的证明、数据质量的检查等。
一、SQLFlow 是怎样工作的
- 从数据库、版本控制系统、文件系统中获取 SQL 脚本。
- 解析 SQL 脚本,分析其中的各种数据库对象关系,建立数据血缘关系。
- 以各种形式呈现数据血缘关系,包括交互式 UI、CSV、JSON、GRAPHML 格式。
二、SQLFlow 的组成
- Backend, 后台由一系列 Java 程序组成。负责 SQL 的解析、数据血缘分析、可视化元素的布局、身份认证等。
- Frontend,前端由一系列 javascript、html 代码组成。负责 SQL 的递交、数据血缘关系的可视化展示。
- Grabit 工具,一个 Java 程序。负责从数据库、版本控制系统、文件系统中收集 SQL 脚本,递交给后台进行数据血缘分析。
- Restful API,一套完整的 API。让用户可以通过 Java、C#、Python、PHP 等编程语言与后台进行交互,完成数据血缘分析。
三、在线工具连接:https://sqlflow.gudusoft.com/?utm_source=cnblogs&utm_medium=blog&utm_campaign=my-nick-name#/
四、SQLFlow的job功能
1、job能做什么
SQLFlow的job功能是为客户提供的固定血缘追溯场景所设计的,比如你有多个固定的分析逻辑,需要在工作中反复使用,此时你只需要根据具体的分析需求进行设置job即可。该job产生的逻辑关系图属于静态的,不会虽仓库中对象结构变化而变化,这样可以更好的帮助您进行版本追溯及管理。

上图中,做数字标记的job作业,属性1是在工具右侧面板上显示job分析的逻辑关系图,属性2可以分享该job,属性3是删除该job。
2、如何创建job
如下图所示:从工具job功能导航到job list页面,点击【upload】进行Create Job;
其中,sql source的可选来源有三种:upload file、from database、upload file+from database
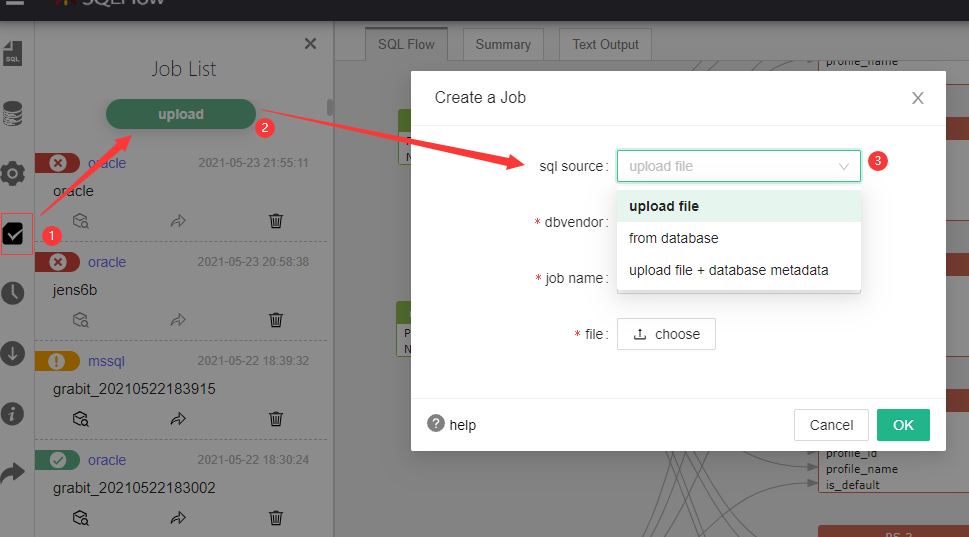
这里以常用的from database方式做Create Job演示:
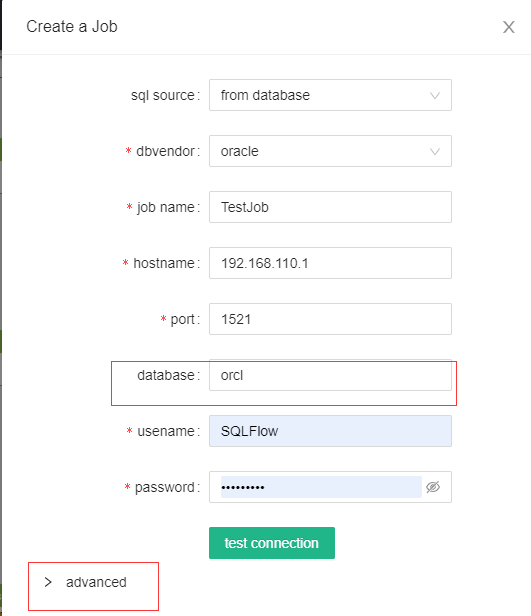
下图中,是Create Job需要填写的相关信息,其中*为必填项,有些数据库的database属性不是必填项,所以他不属于必填项。
dbvendor:需要选择的数据库种类;
job name:一个自定义的好记的job名称
hostname:IP或机器名
port:端口号
database:catalog name,即dbname。
usename:用户名
password:密码
【test connection】可以帮助您进行连接测试。
advanced的选项如下:
extractedDbsSchemas:所提取的特定schema
excludedDbsSchemas:包含的schema
extractedStoredProcedures:所提取的存储过程名称
extractedViews:所提取的视图名称
备注:高级选项都不是必填项!

当您所有信息填写正确后,点击【OK】即可成功创建job。
谢谢!
SQLFlow数据流分析工具的job功能介绍的更多相关文章
- iOS 常用工具库LFKit功能介绍
简介:LFKit包含了平时常用的category,封装的常用组件,一些工具类. 需要LFKit中所有自定义控件的pod 'LFKit/Component' 需要LFKit中所有category的pod ...
- MetaSploit攻击实例讲解------工具Meterpreter常用功能介绍(kali linux 2016.2(rolling))(详细)
不多说,直接上干货! 说在前面的话 注意啦:Meterpreter的命令非常之多,本篇博客下面给出了所有,大家可以去看看.给出了详细的中文 由于篇幅原因,我只使用如下较常用的命令. 这篇博客,利用下面 ...
- 代码生成工具Database2Sharp的架构介绍
1)代码生成工具介绍 Database2Sharp是一款代码生成工具和数据库文档生成工具,该工具从2005年开始至今,一直伴随着我们的客户和粉丝们经历着过各种各样的项目开发,在实际开发中能带来效率的提 ...
- 抓包工具 - HttpWatch(功能详细介绍)
HttpWatch是功能强大的网页数据分析工具,集成在IE工具栏,主要功能有网页摘要.cookies管理.缓存管理.消息头发送/接收,字符查询.POST数据.目录管理功能和报告输出.HttpWatch ...
- pt-query-digest工具的功能介绍了:
Ok,可以查看 pt-query-digest工具的功能介绍了: [root@472322 percona-toolkit-2.2.5]# pt-query-digest --help pt-quer ...
- [数据分析工具] Pandas 功能介绍(一)
如果你在使用 Pandas(Python Data Analysis Library) 的话,下面介绍的对你一定会有帮助的. 首先我们先介绍一些简单的概念 DataFrame:行列数据,类似 Exce ...
- 大数据之ETL工具Kettle的--1功能介绍
Kettle是一款国外开源的ETL工具,纯java编写,可以在Window.Linux.Unix上运行. 说白了就是,很有必要去理解一般ETL工具必备的特性和功能,这样才更好的掌握Kettle的使用. ...
- .NET平台开源项目速览(13)机器学习组件Accord.NET框架功能介绍
Accord.NET Framework是在AForge.NET项目的基础上封装和进一步开发而来.因为AForge.NET更注重与一些底层和广度,而Accord.NET Framework更注重与机器 ...
- 微信小程序产品定位及功能介绍
产品定位及功能介绍 微信小程序是一种全新的连接用户与服务的方式,它可以在微信内被便捷地获取和传播,同时具有出色的使用体验. 小程序注册 注册小程序帐号 在微信公众平台官网首页(mp.weixin.qq ...
随机推荐
- 了解PSexec
PSExec允许用户连接到远程计算机并通过命名管道执行命令.命名管道是通过一个随机命名的二进制文件建立的,该文件被写入远程计算机上的ADMIN $共享,并被SVCManager用来创建新服务. 您可以 ...
- [Fundamental of Power Electronics]-PART II-7. 交流等效电路建模-7.2 基本交流建模方法
7.2 基本交流建模方法 在本节中,PWM变换器的交流小信号模型导出步骤将被推导和解释.关键步骤是:(a)利用小纹波近似的动态版本,建立了与电感和电容波形的低频平均值相关的方程式,(b)平均方程的扰动 ...
- oo第三单元——社交网络
第三单元的作业背景是实现一个社交观关系模拟系统,主要训练了JML的阅读和理解能力,和图的一些数据结构和算法. JML语言的理论基础 JML相对于实现代码是比较抽象的,规定了方法的前提副作用结果.数据的 ...
- redis的持久化有哪几种方式?不同的持久化机制都有什么优缺点?(偏难)
1.RDB和AOF两种持久化机制的介绍 RDB持久化机制,对redis中的数据执行周期性的持久化 AOF机制对每条写入命令作为日志,以append-only的模式写入一个日志文件中,在redis重启的 ...
- 关于Vim/Neovim/SpaceVim的一些思考
1 前言 最近看到了Neovim以及SpaceVim,于是上手试了一下. 2 Neovim与SpaceVim Neovim是Vim的一个分支,具有更加现代的GUI.嵌入式以及脚本化的终端.异步工作控制 ...
- lvs 负载均衡 _DR模式 _Python脚本
import paramiko vip='192.168.83.6' # 虚拟IP # direct_server_information ds_info={ 'ip':'192.168.83.5', ...
- 字符串转成KB,MB, GB
import java.text.DecimalFormat; public class SizeUtil { public static String GetImageSize(String ima ...
- Day01_11_Java方法
Java - 方法 什么是java中的方法? - 方法就是一段代码片段,并且这段代码可以完成某个特定的功能.动作.是可以被重复的使用. - 方法就是类的一个动作. - 方法在C语言中也叫做函数 或 f ...
- DPAPI机制学习
0x00 前言 绝大多数应用程序都有数据加密保护的需求,存储和保护私密信息最安全的方式就是每次需要加密或解密时都从用户那里得到密码,使用后再丢弃.这种方式每次处理信息时都需要用户输入口令,对于绝大多 ...
- 《机器学习Python实现_10_02_集成学习_boosting_adaboost分类器实现》
一.简介 adaboost是一种boosting方法,它的要点包括如下两方面: 1.模型生成 每一个基分类器会基于上一轮分类器在训练集上的表现,对样本做权重调整,使得错分样本的权重增加,正确分类的样本 ...