【论文笔记】Leveraging Post-click Feedback for Content Recommendations
Leveraging Post-click Feedback for Content Recommendations
Authors: Hongyi Wen, Longqi Yang, Deborah Estrin
Recsys'19 Cornell University
论文链接:https://dl.acm.org/doi/pdf/10.1145/3298689.3347037
本文链接:https://www.cnblogs.com/zihaojun/p/15708632.html
0. 总结
这篇文章证明了在推荐系统中,将用户点击之后没有看完的物品作为负样本的一部分参与训练是有效的。
1.研究目标
利用用户在点击之后的反馈数据,来解决点击数据中的噪声问题,提高推荐系统的性能。
- 例如,用户观看视频或听音乐的时长,可以反映用户看到物品之后是否真正喜欢。
2.问题背景
在构建推荐系统时,通常会选用隐式反馈数据作为训练数据,但隐式反馈数据的正样本不一定都是用户喜欢的物品。例如,用户点击了一个物品,这只能反映用户对这个物品的第一印象比较好,用户在浏览之后可能并不喜欢这个物品。
3.分析点击之后的反馈信息
数据集:
- Spotify:在线音乐数据集,包含上亿的听歌会话,每个会话包含最多二十首歌,记录了用户跳过还是听完了每首歌,跳过与否是根据挑战赛组委会设定的播放阈值。随机选择了九百万会话进行分析。
- ByteDance:用户与短视频(10秒)的交互记录,包含是否完播。选取了13 million的数据。
3.1 反馈信息的特点
点击之后的用户反馈在很多场景中都存在,这种反馈可能是显式的(评分),也可能是隐式的(观看时长)。在上述两个数据集中,音乐和短视频场景下,分别有51%和56%的交互是点击之后被跳过的。也就是说,超过半数的交互是点击之后用户并不满意的。
具体到每个物品和每个用户的完播比例,如Figure 1所示,两个数据集上面,左边一列(用户跳过比例)的分布不同,可能是因为音乐和视频的使用场景不同,音乐被跳过会更加随机。
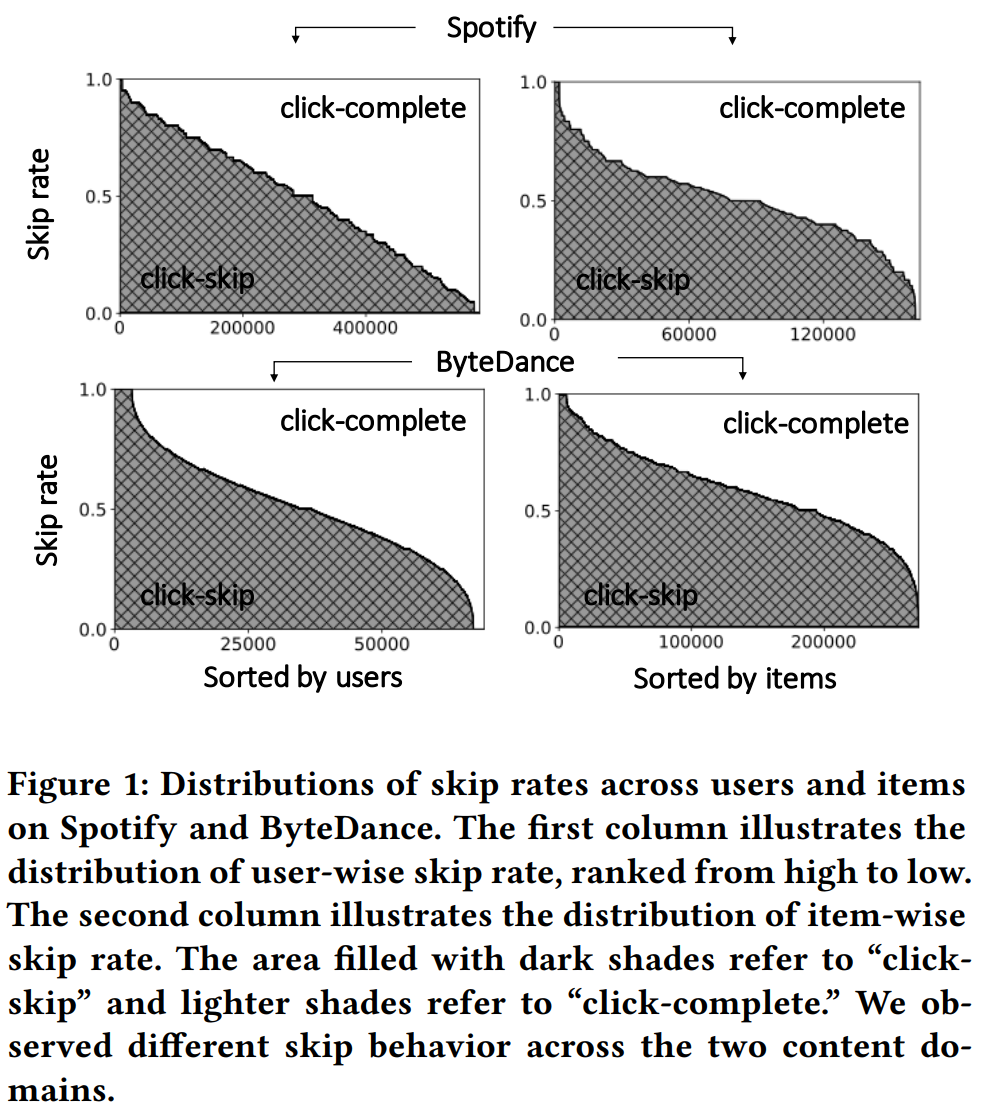
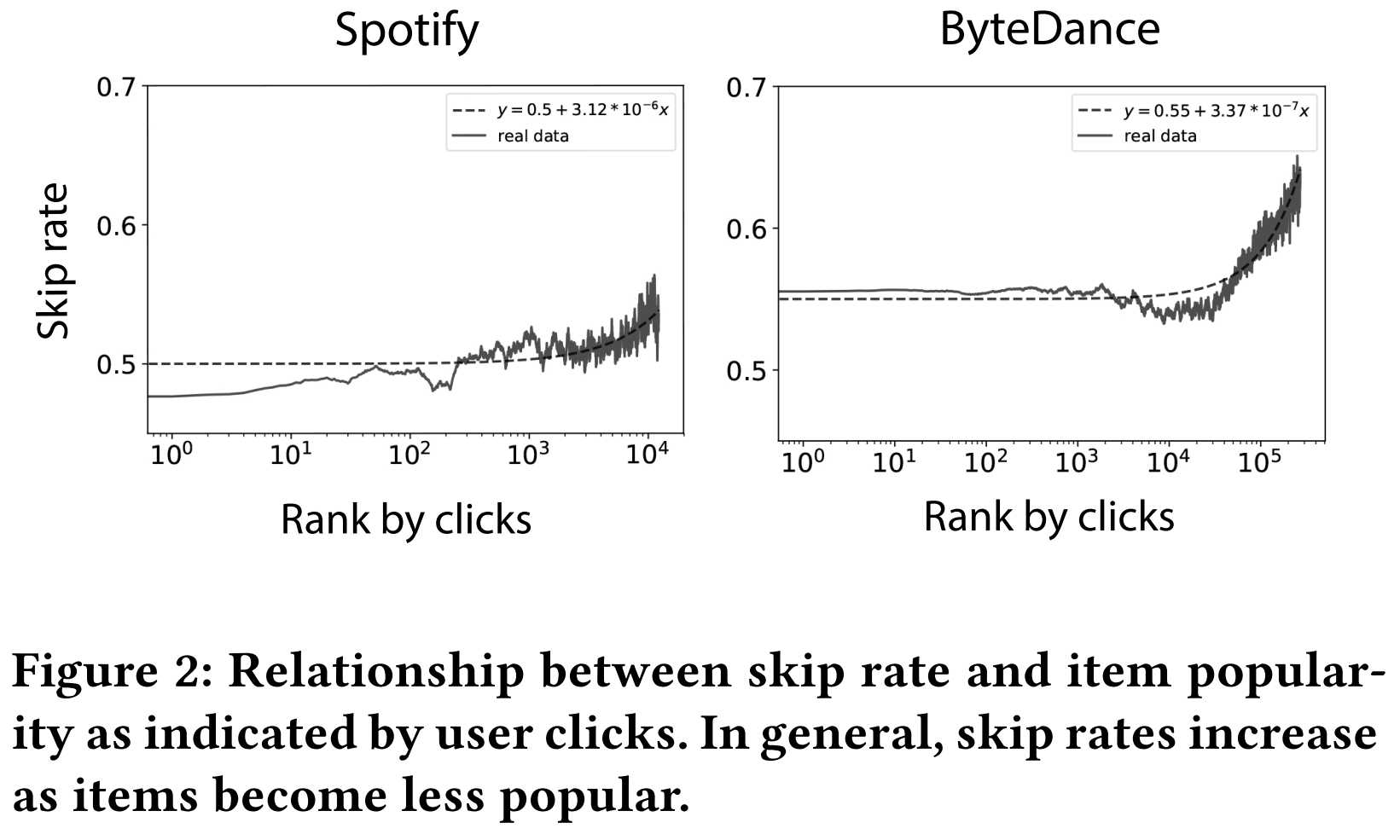
作者还观察到,越冷门的物品,被跳过的比例越高。这可能是物品质量导致的。
3.2 点击和反馈信息
用点击数据作为训练集,分别在常规测试集和兴趣测试集上进行性能测试,研究模型对点击行为和对完播行为的推荐精度差别。
- 常规测试集是指,将所有物品作为候选集,将测试阶段点击物品作为正样本。
- 兴趣测试集是指,将测试阶段的点击样本作为候选列表,将完播数据作为正样本(看能不能把完播排在跳过前面)。
最后得出结论,模型对点击行为的预测能力远高于对完播行为的预测能力。
这一段实验设计有问题,详见Weakness部分
\hline \text { Dataset } & \text { # of users } & \text { # of items } & \text { # of records } & \text { Density } & \text { Percentage of skips % } \\
\hline \text { Spotify } & 229,792 & 100,586 & 4,090,895 & 0.018 \% & 51.05 \% \\
\text { ByteDance } & 37,043 & 271,259 & 9,391,103 & 0.093 \% & 55.13 \% \\
\hline
\end{array}
\]
4.方法
方法是比较简单的,虽然写的很复杂。
总体思路就是把用户跳过的样本(skip)也当做负样本。
4.1 Pointwise Loss
\(O_P\)表示用户未跳过的交互,\(O_N\)表示用户跳过的交互,\(O_M\)表示用户未交互的物品。
\]
其实就是把跳过的物品当做负样本,并且加个权重。
4.2 Pairwise Loss
\(O_P\)中,i表示没跳过的物品,j表示跳过的物品。
\(O_N\)中,i表示没跳过的物品,j没交互过的物品。
\]
注意论文中把第二项的ij反了过来(增加一点复杂度),其实没有必要。
当\(\beta = 0\)时,模型只利用没有跳过的交互作为正样本,而没有利用跳过的样本,称为BL。
当\(\beta \not = 0\)时,模型称为-NR。
5.实验结果
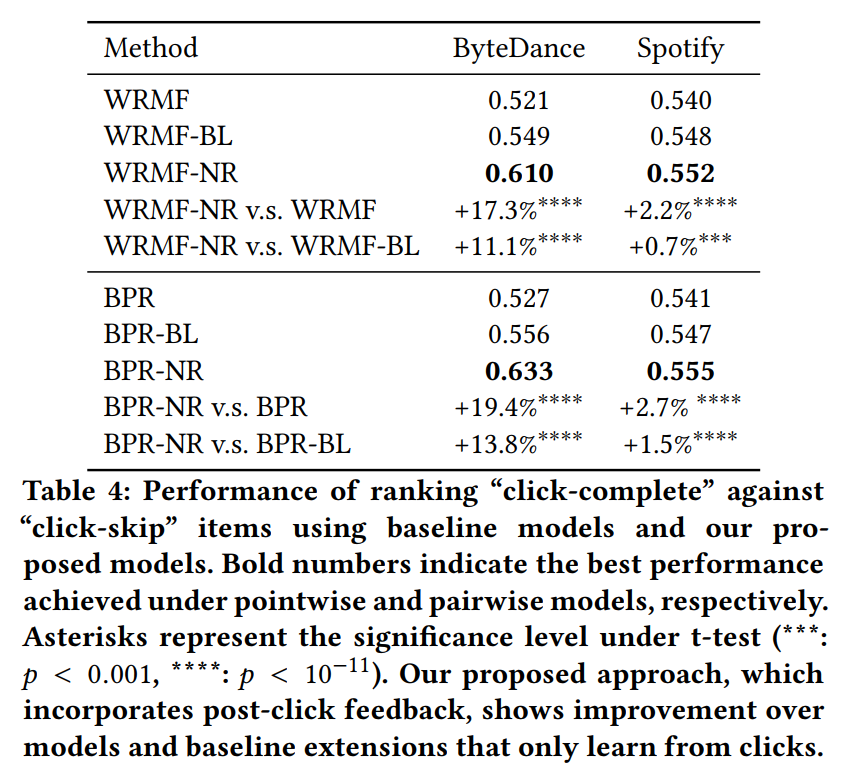
实验结果表明,将跳过的样本作为负样本(NR)是有效的,且直接将这些样本从正样本集中去除(BL)也是有效的
可以借鉴的地方
- 3.1的分析方法
- 数据集 Spotify[1]
Weakness
3.2的分析不合理
- 两种测试任务的难度是不同的,常规测试任务的负样本很简单,但是兴趣测试任务是很难的,因此直接比较两种设置下的AUC绝对值是不合理的。
- 比较合理的实验设置应该是保持测试方法一致,修改训练集数据,用(跳过+完播)和(完播)两种训练方式,看测试效果有什么不同。(看到后面才发现,这已经是论文主实验了)
有错词,例如5.2部分第三个单词purposed,应为proposed。
符号不一致,5.1部分使用的符号\(\lambda_p\)和\(\lambda_n\)在前文并没有提到。
[29]和[30]两篇引用是同一篇
进一步阅读
[15] Hongyu Lu, Min Zhang, and Shaoping Ma. 2018. Between Clicks and Satisfaction: Study on Multi-Phase User Preferences and Satisfaction for Online News Reading. In The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval. ACM, 435–444.
[34] Qian Zhao, F Maxwell Harper, Gediminas Adomavicius, and Joseph A Konstan. 2018. Explicit or implicit feedback? engagement or satisfaction?: a feld experiment on machine-learning-based recommender systems. In Proceedings of the 33rd Annual ACM Symposium on Applied Computing. ACM, 1331–1340.
[5] Yifan Hu, Yehuda Koren, and Chris Volinsky. 2008. Collaborative fltering for implicit feedback datasets. In Eighth IEEE International Conference on Data Mining (ICDM’08). IEEE, 263–272.
[8] Youngho Kim, Ahmed Hassan, Ryen W White, and Imed Zitouni. 2014. Modeling dwell time to predict click-level satisfaction. In Proceedings of the 7th ACM international conference on Web search and data mining. ACM, 193–202.
[11] Mounia Lalmas, Janette Lehmann, Guy Shaked, Fabrizio Silvestri, and Gabriele Tolomei. 2015. Promoting positive post-click experience for in-stream yahoo gemini users. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 1929–1938.
【论文笔记】Leveraging Post-click Feedback for Content Recommendations的更多相关文章
- 【论文笔记】 Denoising Implicit Feedback for Recommendation
Denoising Implicit Feedback for Recommendation Authors: 王文杰,冯福利,何向南,聂礼强,蔡达成 WSDM'21 新加坡国立大学,中国科学技术大学 ...
- 【论文笔记】用反事实推断方法缓解标题党内容对推荐系统的影响 Click can be Cheating: Counterfactual Recommendation for Mitigating Clickbait Issue
Click can be Cheating: Counterfactual Recommendation for Mitigating Clickbait Issue Authors: 王文杰,冯福利 ...
- 【论文笔记】SamWalker: Social Recommendation with Informative Sampling Strategy
SamWalker: Social Recommendation with Informative Sampling Strategy Authors: Jiawei Chen, Can Wang, ...
- Perceptual Losses for Real-Time Style Transfer and Super-Resolution and Super-Resolution 论文笔记
Perceptual Losses for Real-Time Style Transfer and Super-Resolution and Super-Resolution 论文笔记 ECCV 2 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Twitter 新一代流处理利器——Heron 论文笔记之Heron架构
Twitter 新一代流处理利器--Heron 论文笔记之Heron架构 标签(空格分隔): Streaming-process realtime-process Heron Architecture ...
- Deep Learning论文笔记之(六)Multi-Stage多级架构分析
Deep Learning论文笔记之(六)Multi-Stage多级架构分析 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些 ...
随机推荐
- CSS-sprit 雪碧图
CSS-sprit 雪碧图 可以将 多个小图片统一保存到一个大图片中,然后通过调整background-position来显示响应的图片 这样图片会同时加载到网页中 就可以避免出现闪烁 ...
- C/C++ Qt Tree与Tab组件实现分页菜单
虽然TreeWidget组件可以实现多节点的增删改查,但多节点操作显然很麻烦,在一般的应用场景中基本上只使用一层结构即可解决大部分开发问题,TreeWidget组件通常可配合TabWidget组件,实 ...
- 洛谷 P5518 - [MtOI2019]幽灵乐团 / 莫比乌斯反演基础练习题(莫比乌斯反演+整除分块)
洛谷题面传送门 一道究极恶心的毒瘤六合一题,式子推了我满满两面 A4 纸-- 首先我们可以将式子拆成: \[ans=\prod\limits_{i=1}^A\prod\limits_{j=1}^B\p ...
- day08 文件属性
day08 系统目录 今日内容 一.重要目录 1./usr 2./var 3./proc 二.文件的属性 1.文件属性的介绍 2.文件属性的详述 3.企业案例 /usr 安装第三方软件的目录: 1./ ...
- Hive(八)【行转列、列转行】
目录 一.行转列 相关函数 concat concat_ws collect_set collect_list 需求 需求分析 数据准备 写SQL 二.列转行 相关函数 split explode l ...
- 一起手写吧!promise.all
Promise.all 接收一个 promise 对象的数组作为参数,当这个数组里的所有 promise 对象全部变为resolve或 有 reject 状态出现的时候,它才会去调用 .then 方法 ...
- Maven 学习第一步[转载]
转载至:http://www.cnblogs.com/haippy/archive/2012/07/04/2576453.html 什么是 Maven?(摘自百度百科) Maven是Apache的一个 ...
- Linux基础命令---dig工具
dig dig是一个DNS查询工具,多数管理员会使用dig命令来解决DNS的问题. 此命令的适用范围:RedHat.RHEL.Ubuntu.CentOS.Fedora. 1.语法 di ...
- restful接口文档
1.先理清业务bai流程 2.定义前后端开发的接口规范.比如json的格dao式,url的格式 3.定内义接口文容档,这里的接口文档一般就是对应后台的实体reqVo(调用后台接口<控制器> ...
- node.js require() 源码解读
时至今日,Node.js 的模块仓库 npmjs.com ,已经存放了15万个模块,其中绝大部分都是 CommonJS 格式.这种格式的核心就是 require 语句,模块通过它加载.学习 Node. ...