Hadoop入门 集群崩溃的处理方法
集群崩溃的处理方法
搞崩集群
hadoop102
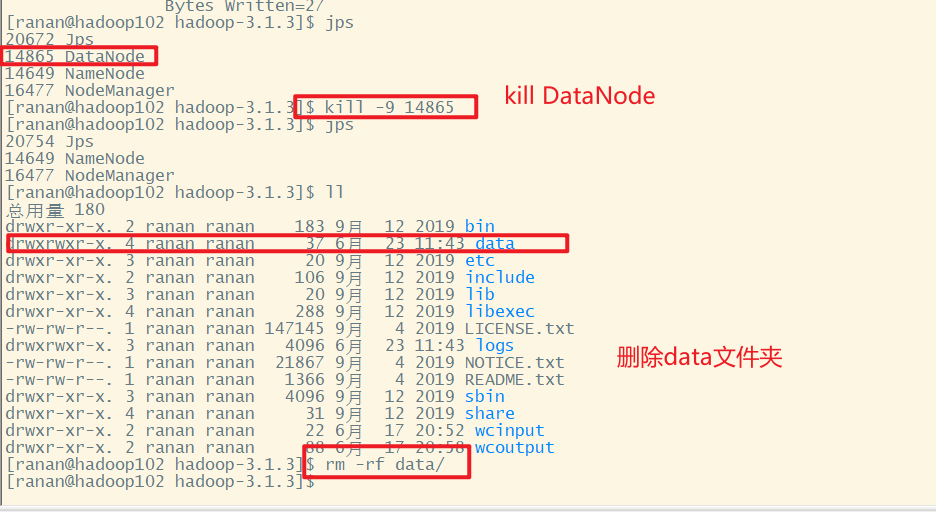
hadoop103
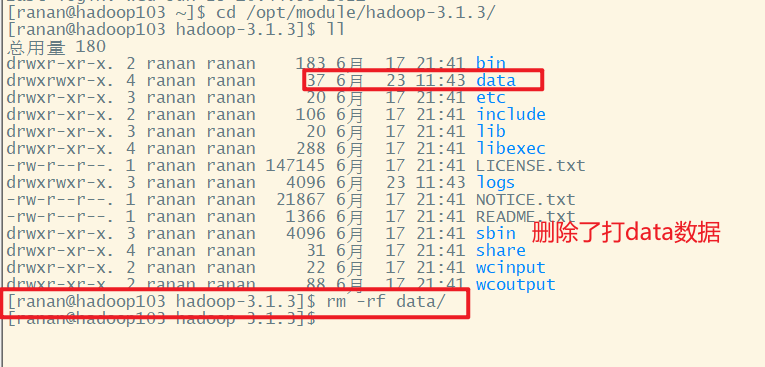
hadoop104

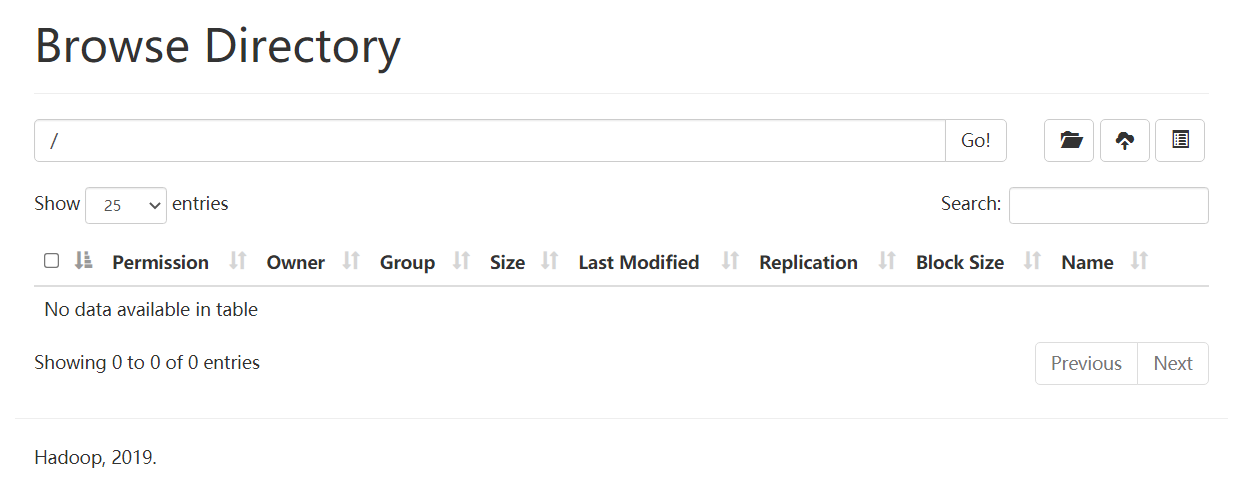
此时HDFS Web端的文件是不可以下载的,因为三个副本都删除了。
错误示范
最先想到的是格式化集群
[ranan@hadoop102 hadoop-3.1.3]$ hdfs namenode -format

提示需要先停掉集群,正常情况下先把yarn停掉
[ranan@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
[ranan@hadoop102 hadoop-3.1.3]$ sbin/stop-dfs.sh

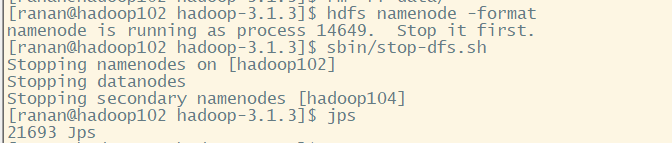
启动集群,发现集群正常启动,但是NameNode没了
[ranan@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
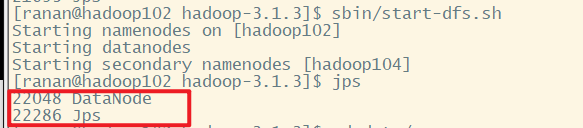
查看目录,发现删除了DataNode中的name
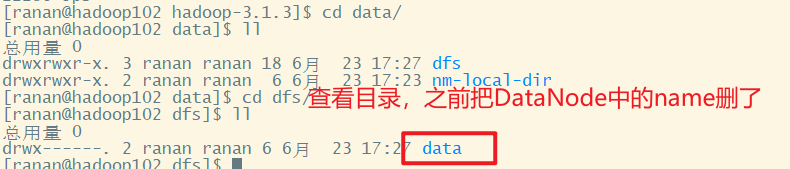
那就格式NameNode,之前并没有成功格式化。
[ranan@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
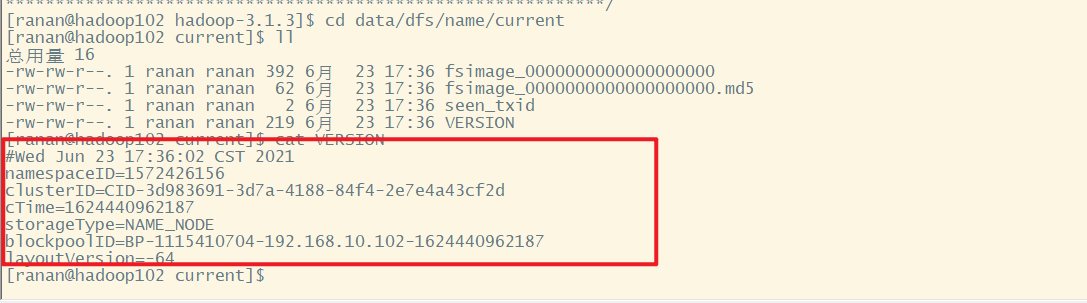
格式化之后,发现name文件夹有了,进去查看版本号。发现两次的版本号不一样。
[ranan@hadoop102 hadoop-3.1.3]$ cd data/dfs/name/current
[ranan@hadoop102 current]$ cat VERSION
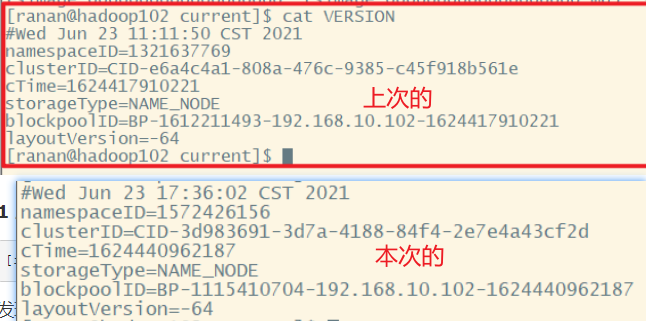
此时进入HDFS网页,发现进不去了
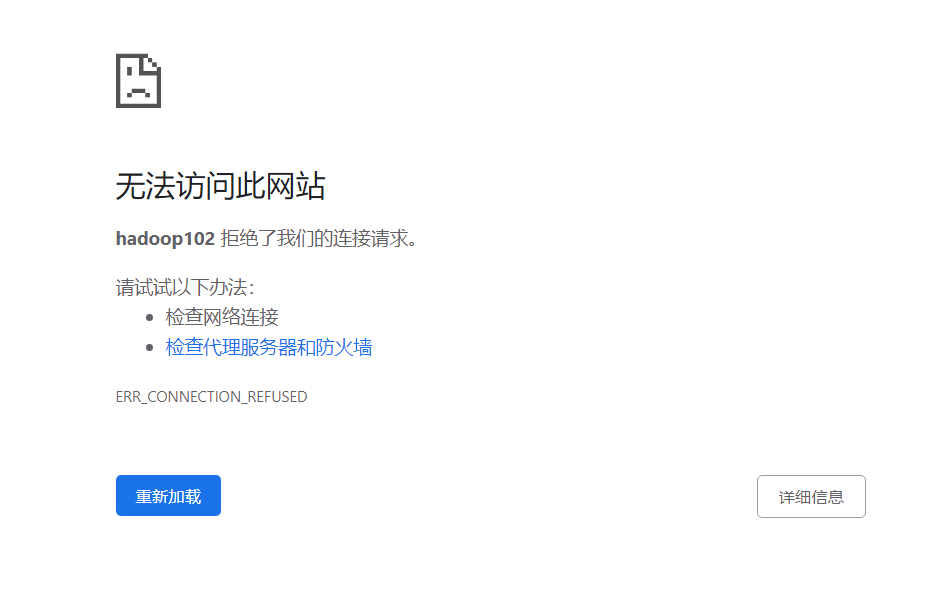
查看发现namenode还是没有启动

那该怎么办?
正确处理方法
1 回到hadoop的家目录
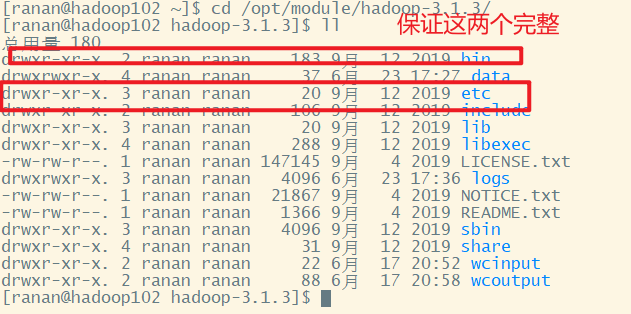
2 杀死进程
[ranan@hadoop102 hadoop-3.1.3]$ sbin/stop-dfs.sh
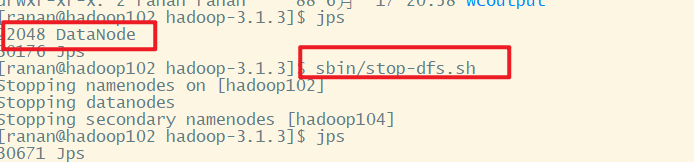
3 删除每个集群的data和logs
[ranan@hadoop102 hadoop-3.1.3]$ rm -rf data logs
[ranan@hadoop103 hadoop-3.1.3]$ rm -rf data logs
[ranan@hadoop104 hadoop-3.1.3]$ rm -rf data logs
4 格式化
[ranan@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
5 启动集群
[ranan@hadoop102 hadoop-3.1.3]$ hdfs namenode -format
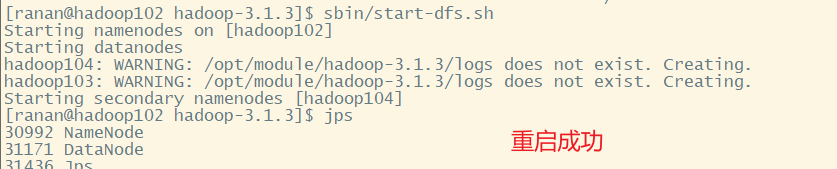
重启成功,但是数据都被清空了
总结
1.先停HDFS服务
2.清除所有节点的历史data和logs
3.格式化NameNode
4.重新启动
原因分析
格式化 NameNode,会产生新的集群 id,导致 NameNode 和 DataNode 的集群 id 不一致,集群找不到已往数据。如果集群在运行过程中报错,需要重新格式化 NameNode 的话,一定要先停止 namenode 和 datanode 进程,并且要删除所有机器的 data 和 logs 目录,然后再进行格式化。
namenode,datanode都有自己的版本号。namenode和datanode是一一绑定的。
格式化以后的namenode是匹配不上没有格式化以前的datanode。
版本要能匹配的上
Hadoop入门 集群崩溃的处理方法的更多相关文章
- Hadoop入门 集群常用知识与常用脚本总结
目录 集群常用知识与常用脚本总结 集群启动/停止方式 1 各个模块分开启动/停止(常用) 2 各个服务组件逐一启动/停止 编写Hadoop集群常用脚本 1 Hadoop集群启停脚本myhadoop.s ...
- Hadoop入门 集群时间同步
集群时间同步 如果服务器在公网环境(能连接外网),可以不采用集群时间同步.因为服务器会定期和公网时间进行校准. 如果服务器在内网环境,必须要配置集群时间同步,否则时间久了,会产生时间偏差,导致集群执行 ...
- hadoop集群崩溃,因为tmp下/tmp/hadoop-hadoop/dfs/name文件误删除
hadoop执行start-all后,显示正常启动. starting namenode, logging to /opt/hadoop-0.20.2-cdh3u0/logs/hadoop-hadoo ...
- hadoop+spark集群搭建入门
忽略元数据末尾 回到原数据开始处 Hadoop+spark集群搭建 说明: 本文档主要讲述hadoop+spark的集群搭建,linux环境是centos,本文档集群搭建使用两个节点作为集群环境:一个 ...
- 使用Docker在本地搭建Hadoop分布式集群
学习Hadoop集群环境搭建是Hadoop入门必经之路.搭建分布式集群通常有两个办法: 要么找多台机器来部署(常常找不到机器) 或者在本地开多个虚拟机(开销很大,对宿主机器性能要求高,光是安装多个虚拟 ...
- 超快速使用docker在本地搭建hadoop分布式集群
超快速使用docker在本地搭建hadoop分布式集群 超快速使用docker在本地搭建hadoop分布式集群 学习hadoop集群环境搭建是hadoop入门的必经之路.搭建分布式集群通常有两个办法: ...
- Hadoop基础-Hadoop的集群管理之服役和退役
Hadoop基础-Hadoop的集群管理之服役和退役 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 在实际生产环境中,如果是上千万规模的集群,难免一个一个月会有那么几台服务器出点故 ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
- 基于zookeeper的高可用Hadoop HA集群安装
(1)hadoop2.7.1源码编译 http://aperise.iteye.com/blog/2246856 (2)hadoop2.7.1安装准备 http://aperise.iteye.com ...
随机推荐
- 常用JAVA API :HashSet 和 TreeSet
set容器的特点是不包含重复元素,也就是说自动去重. HashSet HashSet基于哈希表实现,无序. add(E e)//如果容器中不包含此元素,则添加. clear()//清空 contain ...
- MVC之三个单选按钮的切换选择
实现需求: 1.三个多选按钮中:只能同时选择限时抢购和分享金或者拼团特惠和分享金,其中限时抢购和拼团特惠不能同时选择.并且点击后显示,再次点击赢隐藏. 1 @*活动信息*@ 2 <div> ...
- Python 语法错误 except Exception, e: ^ SyntaxError: invalid syntax
出这个问题是因为python2和python3 语法有些不同 python2 和 3 处理 except 子句的语法有点不同,需要注意: Python2 try: print ("hello ...
- 在随着layui官网下架后 layui镜像站起来了
layui:https://gitee.com/lh_yun/layui 介绍 layui镜像站 「本站仅为 layui 文档保留的镜像站点,与官方无关」 源码地址 在线 pdf 1.主页 https ...
- Python科普系列——类与方法(上篇)
欢迎来到新的系列,up又开新坑了~~ 实际上,Python作为一门易用性见长的语言,看上去简单,却仍然有很多值得一说的内容,因此这个系列会把Python中比较有意思的地方也给科普一遍.而另一方面,关于 ...
- Django 小实例S1 简易学生选课管理系统 12 CSS样式完善
Django 小实例S1 简易学生选课管理系统 第12节--CSS样式完善 点击查看教程总目录 作者自我介绍:b站小UP主,时常直播编程+红警三,python1对1辅导老师. 课程模块的逻辑代码到这里 ...
- axios通过post请求下载文件/图片
我们平常下载文件一般都是通过get请求直接访问进行下载, 但是当有特殊情况如权限控制之类的会要求我们通过post请求进行下载,这时就不一样了, 具体方法是通过协调后端,约定返回的文件流,请求的resp ...
- [cf720D]Slalom
对于每一行,这些障碍将其划分为若干段,记第$i$行($y=i$时)从左到右第$j$段为$[l_{i,j},r_{i,j}]$ 显然一条路径恰好经过每一行中的一段,且两种方案不同当且仅当其中经过的一段不 ...
- [atARC112E]Rvom and Rsrev
毒瘤分类讨论题 (注:以下情况都有"之前的情况都不满足的"前提条件,并用斜体表示一些说明) Case0:若$|s|\le 2$,直接输出即可,因此假设$|s|>3$ 首先,我 ...
- [hdu5379]Mahjong tree
一棵子树的每一个儿子相当于划分一个区间,同时这些区间一定要存在一个点连续(直接的儿子),因此每一棵树最多只有两个儿子存在子树,并且这两个儿子所分到的区间一定是该区间最左和最右两段,所以ans*=(so ...