Spark的DataFrame的窗口函数使用
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处
SparkSQL这块儿从1.4开始支持了很多的窗口分析函数,像row_number这些,平时写程序加载数据后用SQLContext 能够很方便实现很多分析和查询,如下
val sqlContext = new SQLContext(sc)
sqlContext.sql(“select ….”)
然而我看到Spark后续版本的DataFrame功能很强大,想试试使用这种方式来实现比如row_number这种功能,话不多说,快速用pyspark测试一下,记录一下遇到的问题.
from pyspark.sql import Row, functions as F
from pyspark.sql.window import Window
from pyspark import SparkContext
sc = SparkContext("local[3]", "test data frame on 2.0")
testDF = sc.parallelize( (Row(c="class1", s=50), Row(c="class2", s=40), Row(c="class3", s=70), Row(c="class2", s=49), Row(c="class3", s=29), Row(c="class1", s=78) )).toDF()
(testDF.select("c", "s", F.rowNumber().over(Window.partitionBy("c").orderBy("s")).alias("rowNum") ).show())
spark-submit提交任务后直接报错如下

告诉我RDD没有toDF()属性,查阅spark官方文档得知还是需要用SQLContext或者sparkSession来初始化一下,先考虑用SQLContext吧,修改代码如下
from pyspark.sql import Row, functions as F
from pyspark.sql.window import Window
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext("local[3]", "test data frame on 2.0")
rddData = sc.parallelize( (Row(c="class1", s=50), Row(c="class2", s=40), Row(c="class3", s=70), Row(c="class2", s=49), Row(c="class3", s=29), Row(c="class1", s=78)))
sqlContext = SQLContext(sc)
testDF = rddData.toDF()
(testDF.select("c", "s", F.rowNumber().over(Window.partitionBy("c").orderBy("s")).alias("rowNum") ).show())
spark-submit提交任务后接着报另外一个错,如下

ok,错误很清楚,rowNumber这里我写错了,没有这个函数,查阅spark源码中的functions.py,会发现如下说明
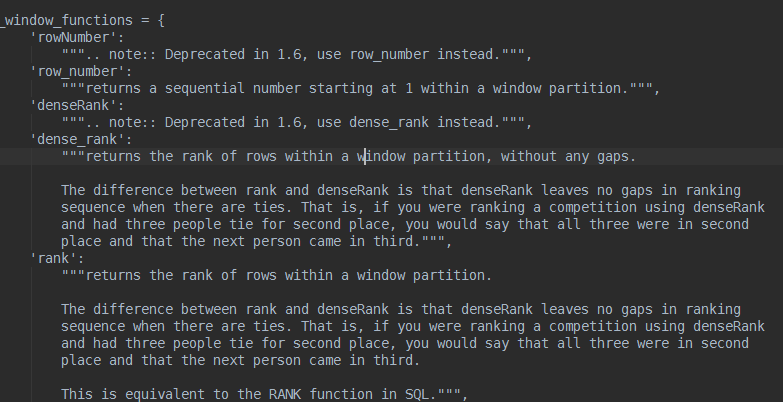
这里说了,rowNumber从1.6开始,用row_number代替,直接修改py脚本如下
from pyspark.sql import Row, functions as F
from pyspark.sql.window import Window
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext("local[3]", "test data frame on 2.0")
rddData = sc.parallelize( (Row(c="class1", s=50), Row(c="class2", s=40), Row(c="class3", s=70), Row(c="class2", s=49), Row(c="class3", s=29), Row(c="class1", s=78)))
sqlContext = SQLContext(sc)
testDF = rddData.toDF()
(testDF.select("c", "s", F.row_number().over(Window.partitionBy("c").orderBy("s")).alias("rowNum") ).show())
这次运行没问题,结果如下
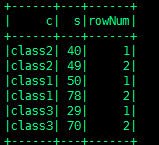
但是我只想取每组rowNum为1的那个,代码如下
from pyspark.sql import Row, functions as F
from pyspark.sql.window import Window
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext("local[3]", "test data frame on 2.0")
rddData = sc.parallelize( (Row(c="class1", s=50), Row(c="class2", s=40), Row(c="class3", s=70), Row(c="class2", s=49), Row(c="class3", s=29), Row(c="class1", s=78)))
sqlContext = SQLContext(sc)
testDF = rddData.toDF()
result = (testDF.select("c", "s", F.row_number().over(Window.partitionBy("c").orderBy("s")).alias("rowNum")))
finalResult = result.where(result.rowNum <= 1).show()
可以看到,sql能实现的DataFrame的函数都可以实现,毕竟DataFrame是基于row和column的,就是写起来麻烦点.
参考资料:http://spark.apache.org/docs/1.3.1/api/python/pyspark.sql.html
Spark的DataFrame的窗口函数使用的更多相关文章
- Spark sql -- Spark sql中的窗口函数和对应的api
一.窗口函数种类 ranking 排名类 analytic 分析类 aggregate 聚合类 Function Type SQL DataFrame API Description Ranking ...
- pandas和spark的dataframe互转
pandas的dataframe转spark的dataframe from pyspark.sql import SparkSession # 初始化spark会话 spark = SparkSess ...
- 【spark】dataframe常见操作
spark dataframe派生于RDD类,但是提供了非常强大的数据操作功能.当然主要对类SQL的支持. 在实际工作中会遇到这样的情况,主要是会进行两个数据集的筛选.合并,重新入库. 首先加载数据集 ...
- Spark操作dataFrame进行写入mysql,自定义sql的方式
业务场景: 现在项目中需要通过对spark对原始数据进行计算,然后将计算结果写入到mysql中,但是在写入的时候有个限制: 1.mysql中的目标表事先已经存在,并且当中存在主键,自增长的键id 2. ...
- Spark:将DataFrame写入Mysql
Spark将DataFrame进行一些列处理后,需要将之写入mysql,下面是实现过程 1.mysql的信息 mysql的信息我保存在了外部的配置文件,这样方便后续的配置添加. //配置文件示例: [ ...
- Spark:DataFrame批量导入Hbase的两种方式(HFile、Hive)
Spark处理后的结果数据resultDataFrame可以有多种存储介质,比较常见是存储为文件.关系型数据库,非关系行数据库. 各种方式有各自的特点,对于海量数据而言,如果想要达到实时查询的目的,使 ...
- [Spark][Python][DataFrame][RDD]DataFrame中抽取RDD例子
[Spark][Python][DataFrame][RDD]DataFrame中抽取RDD例子 sqlContext = HiveContext(sc) peopleDF = sqlContext. ...
- [Spark][Python][DataFrame][RDD]从DataFrame得到RDD的例子
[Spark][Python][DataFrame][RDD]从DataFrame得到RDD的例子 $ hdfs dfs -cat people.json {"name":&quo ...
- [Spark][Python][DataFrame][Write]DataFrame写入的例子
[Spark][Python][DataFrame][Write]DataFrame写入的例子 $ hdfs dfs -cat people.json {"name":" ...
随机推荐
- 开源:Taurus.MVC 框架
为什么要创造Taurus.MVC: 记得被上一家公司忽悠去负责公司电商平台的时候,情况是这样的: 项目原版是外包给第三方的,使用:WebForm+NHibernate,代码不堪入目,Bug无限,经常点 ...
- 恋爱虽易,相处不易:当EntityFramework爱上AutoMapper
剧情开始 为何相爱? 相处的问题? 女人的伟大? 剧情收尾? 有时候相识即是一种缘分,相爱也不需要太多的理由,一个眼神足矣,当EntityFramework遇上AutoMapper,就是如此,恋爱虽易 ...
- POCO Controller 你这么厉害,ASP.NET vNext 知道吗?
写在前面 阅读目录: POCO 是什么? 为什么会有 POJO? POJO 的意义 POJO 与 PO.VO 的区别 POJO 的扩展 POCO VS DTO Controller 是什么? 关于 P ...
- C#基础篇 - 正则表达式入门
1.基本概念 正则表达式(Regular Expression)就是用事先定义好的一些特定字符(元字符)或普通字符.及这些字符的组合,组成一个“规则字符串”,这个“规则字符串”用来判断我们给定的字符串 ...
- Phoenix综述(史上最全Phoenix中文文档)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/users/6cb45a00b49c/latest_articles 网上关于P ...
- C++ 拷贝构造函数和赋值运算符
本文主要介绍了拷贝构造函数和赋值运算符的区别,以及在什么时候调用拷贝构造函数.什么情况下调用赋值运算符.最后,简单的分析了下深拷贝和浅拷贝的问题. 拷贝构造函数和赋值运算符 在默认情况下(用户没有定义 ...
- 创建ABPboilerplate模版项目
本文是根据角落的白板报的<通过ABPboilerplate模版创建项目>一文的学习总结,感谢原文作者角落的白板报. 1 准备 开发环境: Visual Studio 2015 update ...
- css样式之超出隐藏
文本超出部分隐藏,总结两种方法. 1.单行隐藏 html代码 <div class="mi">当文字超过范围的时候,超出部分会隐藏起来.</div> css ...
- BPM合同管理解决方案分享
一.方案概述合同是组织与组织间所订协议的法律 表现形式,体现着双方对于合作在法律和道德上的承诺.然而,大多数企业的合同管理都或多或少存在合同审批过程不规范.签订草率.审批权责不清.合同执行跟踪难.合同 ...
- 如何使用本地账户"完整"安装 SharePoint Server 2010+解决“New-SPConfigurationDatabase : 无法连接到 SharePoint_Config 的 SQL Server 的数据 库 master。此数据库可能不存在,或当前用户没有连接权限。”
注:目前看到的解决本地账户完整安装SharePoint Server 2010的解决方案如下,但是,有但是的哦: 当我们选择了"完整"模式安装SharePointServer201 ...