Spark的DataFrame的窗口函数使用
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处
SparkSQL这块儿从1.4开始支持了很多的窗口分析函数,像row_number这些,平时写程序加载数据后用SQLContext 能够很方便实现很多分析和查询,如下
val sqlContext = new SQLContext(sc)
sqlContext.sql(“select ….”)
然而我看到Spark后续版本的DataFrame功能很强大,想试试使用这种方式来实现比如row_number这种功能,话不多说,快速用pyspark测试一下,记录一下遇到的问题.
from pyspark.sql import Row, functions as F
from pyspark.sql.window import Window
from pyspark import SparkContext
sc = SparkContext("local[3]", "test data frame on 2.0")
testDF = sc.parallelize( (Row(c="class1", s=50), Row(c="class2", s=40), Row(c="class3", s=70), Row(c="class2", s=49), Row(c="class3", s=29), Row(c="class1", s=78) )).toDF()
(testDF.select("c", "s", F.rowNumber().over(Window.partitionBy("c").orderBy("s")).alias("rowNum") ).show())
spark-submit提交任务后直接报错如下

告诉我RDD没有toDF()属性,查阅spark官方文档得知还是需要用SQLContext或者sparkSession来初始化一下,先考虑用SQLContext吧,修改代码如下
from pyspark.sql import Row, functions as F
from pyspark.sql.window import Window
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext("local[3]", "test data frame on 2.0")
rddData = sc.parallelize( (Row(c="class1", s=50), Row(c="class2", s=40), Row(c="class3", s=70), Row(c="class2", s=49), Row(c="class3", s=29), Row(c="class1", s=78)))
sqlContext = SQLContext(sc)
testDF = rddData.toDF()
(testDF.select("c", "s", F.rowNumber().over(Window.partitionBy("c").orderBy("s")).alias("rowNum") ).show())
spark-submit提交任务后接着报另外一个错,如下

ok,错误很清楚,rowNumber这里我写错了,没有这个函数,查阅spark源码中的functions.py,会发现如下说明
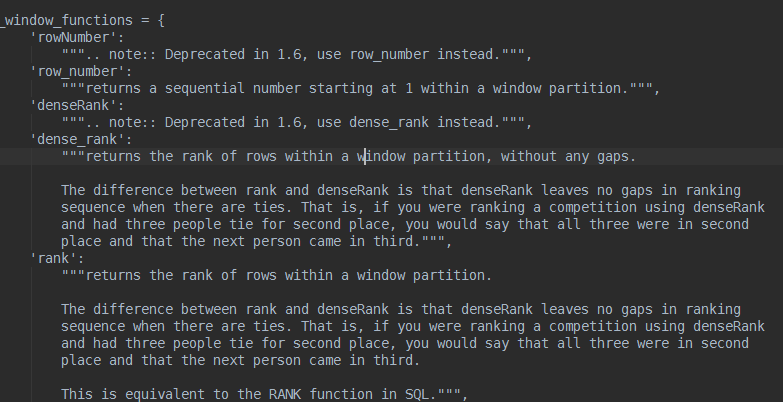
这里说了,rowNumber从1.6开始,用row_number代替,直接修改py脚本如下
from pyspark.sql import Row, functions as F
from pyspark.sql.window import Window
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext("local[3]", "test data frame on 2.0")
rddData = sc.parallelize( (Row(c="class1", s=50), Row(c="class2", s=40), Row(c="class3", s=70), Row(c="class2", s=49), Row(c="class3", s=29), Row(c="class1", s=78)))
sqlContext = SQLContext(sc)
testDF = rddData.toDF()
(testDF.select("c", "s", F.row_number().over(Window.partitionBy("c").orderBy("s")).alias("rowNum") ).show())
这次运行没问题,结果如下
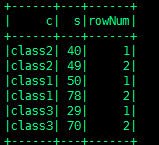
但是我只想取每组rowNum为1的那个,代码如下
from pyspark.sql import Row, functions as F
from pyspark.sql.window import Window
from pyspark import SparkContext
from pyspark.sql import SQLContext
sc = SparkContext("local[3]", "test data frame on 2.0")
rddData = sc.parallelize( (Row(c="class1", s=50), Row(c="class2", s=40), Row(c="class3", s=70), Row(c="class2", s=49), Row(c="class3", s=29), Row(c="class1", s=78)))
sqlContext = SQLContext(sc)
testDF = rddData.toDF()
result = (testDF.select("c", "s", F.row_number().over(Window.partitionBy("c").orderBy("s")).alias("rowNum")))
finalResult = result.where(result.rowNum <= 1).show()
可以看到,sql能实现的DataFrame的函数都可以实现,毕竟DataFrame是基于row和column的,就是写起来麻烦点.
参考资料:http://spark.apache.org/docs/1.3.1/api/python/pyspark.sql.html
Spark的DataFrame的窗口函数使用的更多相关文章
- Spark sql -- Spark sql中的窗口函数和对应的api
一.窗口函数种类 ranking 排名类 analytic 分析类 aggregate 聚合类 Function Type SQL DataFrame API Description Ranking ...
- pandas和spark的dataframe互转
pandas的dataframe转spark的dataframe from pyspark.sql import SparkSession # 初始化spark会话 spark = SparkSess ...
- 【spark】dataframe常见操作
spark dataframe派生于RDD类,但是提供了非常强大的数据操作功能.当然主要对类SQL的支持. 在实际工作中会遇到这样的情况,主要是会进行两个数据集的筛选.合并,重新入库. 首先加载数据集 ...
- Spark操作dataFrame进行写入mysql,自定义sql的方式
业务场景: 现在项目中需要通过对spark对原始数据进行计算,然后将计算结果写入到mysql中,但是在写入的时候有个限制: 1.mysql中的目标表事先已经存在,并且当中存在主键,自增长的键id 2. ...
- Spark:将DataFrame写入Mysql
Spark将DataFrame进行一些列处理后,需要将之写入mysql,下面是实现过程 1.mysql的信息 mysql的信息我保存在了外部的配置文件,这样方便后续的配置添加. //配置文件示例: [ ...
- Spark:DataFrame批量导入Hbase的两种方式(HFile、Hive)
Spark处理后的结果数据resultDataFrame可以有多种存储介质,比较常见是存储为文件.关系型数据库,非关系行数据库. 各种方式有各自的特点,对于海量数据而言,如果想要达到实时查询的目的,使 ...
- [Spark][Python][DataFrame][RDD]DataFrame中抽取RDD例子
[Spark][Python][DataFrame][RDD]DataFrame中抽取RDD例子 sqlContext = HiveContext(sc) peopleDF = sqlContext. ...
- [Spark][Python][DataFrame][RDD]从DataFrame得到RDD的例子
[Spark][Python][DataFrame][RDD]从DataFrame得到RDD的例子 $ hdfs dfs -cat people.json {"name":&quo ...
- [Spark][Python][DataFrame][Write]DataFrame写入的例子
[Spark][Python][DataFrame][Write]DataFrame写入的例子 $ hdfs dfs -cat people.json {"name":" ...
随机推荐
- 一个诡异的COOKIE问题
今天下午,发现本地的测试环境突然跑不动了,thinkphp直接跑到异常页面,按照正常的排错思路,直接看thinkphp的log 有一条 [ error ] [2]setcookie() expects ...
- 对百度WebUploader开源上传控件的二次封装,精简前端代码(两句代码搞定上传)
前言 首先声明一下,我这个是对WebUploader开源上传控件的二次封装,底层还是WebUploader实现的,只是为了更简洁的使用他而已. 下面先介绍一下WebUploader 简介: WebUp ...
- LoadRunner函数百科叒叒叒更新了!
首先要沉痛通知每周四固定栏目[学霸君]由于小编外派公干,本周暂停. 那么这周就由云层君来顶替了,当然要要说下自己做的内容啦,DuangDuang! <LoadRunner函数百科>更新通知 ...
- c# Enumerable中Aggregate和Join的使用
参考页面: http://www.yuanjiaocheng.net/ASPNET-CORE/asp.net-core-environment.html http://www.yuanjiaochen ...
- stringstream的基本用法
原帖地址:https://zhidao.baidu.com/question/580048330.htmlstringstream是字符串流.它将流与存储在内存中的string对象绑定起来.在多种数据 ...
- 【干货分享】流程DEMO-请休假
流程名: 请假申请 流程相关文件: 流程包.xml WebService业务服务.xml WebService.asmx WebService.cs 流程说明: 流程中集成了webservice服 ...
- 【python之路5】学习小结
一.编程语言 java C语言 C++ C# Python 二.python语言的种类 Cpython:python的官方版本,使用最为广泛,实现将python(py文件)转换为字节码文件(pyc文件 ...
- .NET面试题系列[1] - .NET框架基础知识(1)
很明显,CLS是CTS的一个子集,而且是最小的子集. - 张子阳 .NET框架基础知识(1) 参考资料: http://www.tracefact.net/CLR-and-Framework/DotN ...
- 玩转Windows服务系列——使用Boost.Application快速构建Windows服务
玩转Windows服务系列——创建Windows服务一文中,介绍了如何快速使用VS构建一个Windows服务.Debug.Release版本的注册和卸载,及其原理和服务运行.停止流程浅析分别介绍了Wi ...
- .Net 4.5可执行程序OutOfMemory
原创文章转载请注明出处:@协思, http://zeeman.cnblogs.com 产线上新部署的服务,发生几次无故停止的情况,通过系统事件看到是这样: 这个服务缓存了大量的数据,内存占用比 ...