【mongoDB高级篇②】大数据聚集运算之mapReduce(映射化简)
简述
mapReduce从字面上来理解就是两个过程:map映射以及reduce化简。是一种比较先进的大数据处理方法,其难度不高,从性能上来说属于比较暴力的(通过N台服务器同时来计算),但相较于group以及aggregate来说,功能更强大,并更加灵活。
- 映射过程:先把某一类数据分组归类,这里的映射过程是支持分布式的,一边遍历每一台服务器,一边进行分类。
- 化简过程:然后再在分组中进行运算,这里的化简过程也是支持分布式的,在分类的过程中直接运算了。也就是说如果是一个求和的过程,先在a服务器分组求和,然后再在b服务器分组求和····最后再把化简以后的数据进行最终处理。在映射化简的过程都是每台服务器自己的CPU在运算,大量的服务器同时来进行运算工作,这就是大数据基本理念。
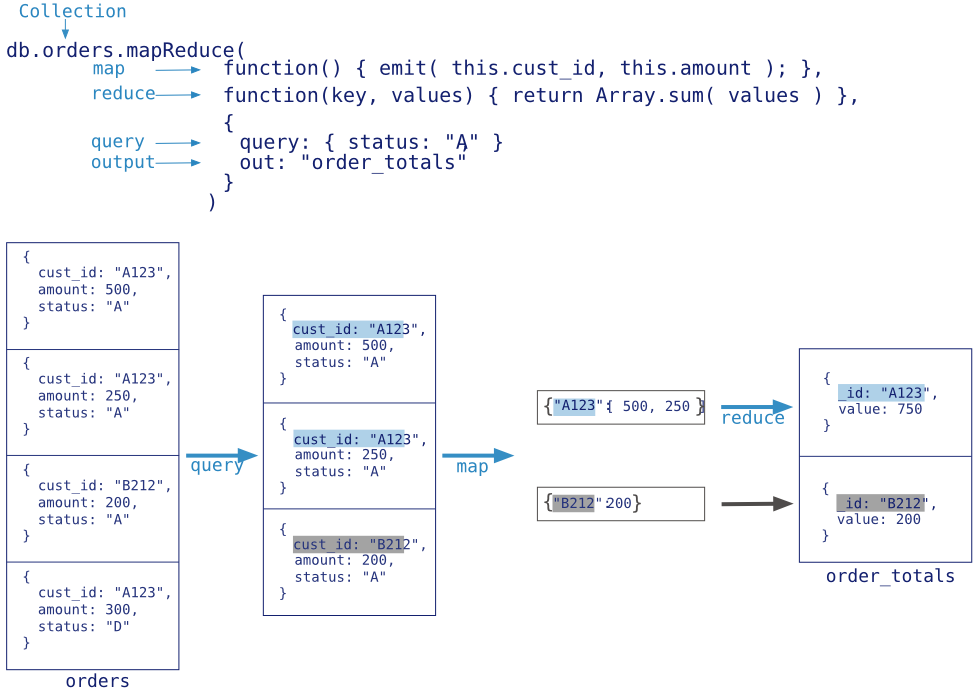
在这个映射化简操作中,MongoDB对每个输入文档(例如集合中满足查询条件的文档)执行了map操作。映射操作输出了键值对结果。对那些有多个值的关键字,MongoDB执reduce操作,收集并压缩了最终的聚合结果。然后MongoDB把结果保存到一个集合中。化简函数还可以把结果输出到finalize函数,进一步对聚合结果做处理,当然这步是可选的。
在MongoDB中,所有的映射化简函数都是使用JavaScript编写,并且运行在 mongod 进程中。映射化简操作使用一个集合中文档作为输入,并且可以在映射阶段之前执行任意的排序和限定操作。 mapReduce 命令可以把结果作为一个文档来返回,也可以把结果写入集合。输入集合和输出集合可以是分片的。
语法参数
更多参考: http://docs.mongodb.org/manual/reference/command/mapReduce/
map: function() {emit(this.cat_id,this.goods_number); }, # 函数内部要调用内置的emit函数,cat_id代表根据cat_id来进行分组,goods_number代表把文档中的goods_number字段映射到cat_id分组上的数据,其中this是指向向前的文档的,这里的第二个参数可以是一个对象,如果是一个对象的话,也是作为数组的元素压进数组里面;
reduce: function(cat_id,all_goods_number) {return Array.sum(all_goods_number)}, # cat_id代表着cat_id当前的这一组,all_goods_number代表当前这一组的goods_number集合,这部分返回的就是结果中的value值;
out: <output>, # 输出到某一个集合中,注意本属性来还支持如果输出的集合如果已经存在了,那是替换,合并还是继续reduce? 另外还支持输出到其他db的分片中,具体用到时查阅文档,筛选出现的键名分别是_id和value;
query: <document>, # 一个查询表达式,是先查询出来,再进行mapReduce的
sort: <document>, # 发往map函数前先给文档排序
limit: <number>, # 发往map函数的文档数量上限,该参数貌似不能用在分片模式下的mapreduce
finalize: function(key, reducedValue) {return modifiedObject; }, # 从reduce函数中接受的参数key与reducedValue,并且可以访问scope中设定的变量
scope: <document>, # 指定一个全局变量,能应用于finalize和reduce函数
jsMode: <boolean>, # 布尔值,是否减少执行过程中BSON和JS的转换,默认true,true时BSON-->js-->map-->reduce-->BSON,false时 BSON-->JS-->map-->BSON-->JS-->reduce-->BSON,可处理非常大的mapreduce。
verbose: <boolean> # 是否产生更加详细的服务器日志,默认true
实例
简单应用实例
# 求每组的库存总量
var map = function(){
emit(this.cat_id,this.goods_number);
}
var reduce = function(cat_id,numbers){
return Array.sum(numbers);
}
db.goods.mapReduce(map,reduce,{out:'res'})
# 查看Array支持的方法
for(var i in Array){
printjson(i);
}
"contains"
"unique"
"shuffle"
"tojson"
"fetchRefs"
"sum"
"avg"
"stdDev"
# 求每个栏目的平均价格
var map = function(){
emit(this.cat_id,this.shop_price);
}
var reduce = function(cat_id,prices){
var avgprice = Array.avg(prices);
return Math.round(avgprice,2);
}
db.goods.mapReduce(map,reduce,{out:'res'});
# 求出每组的最大价格
var map = function(){
emit(this.cat_id,this.shop_price);
}
//错误操作 ↓↓ 应该在finalize函数中做处理
var reduce = function(cat_id,prices){
var max = 0;
for(var i in prices){
if(i > max)
max = i;
}
return max;
}
var reduce = function(cat_id,prices){
return {cat_id:cat_id,prices:prices};
}
var finalize = function(cat_id, prices) {
var max = 0;
if(prices.prices !== null){
var obj = prices.prices;
for(var i in obj){
if(obj[i] > max)
max = obj[i]
}
}
return max == 0 ? prices : max;
}
db.goods.mapReduce(map,reduce,{out:'res1',finalize:finalize,query:{'shop_price':{$gt:0}}});
# 获得每组的商品集合
var map = function(){
emit(this.cat_id,this.goods_name);
}
var reduce = function(cat_id,goods_names){
return {cat_id:cat_id,goods_names:goods_names}
}
var finalize = function(key, reducedValue) {
return reducedValue == null ? 'none value' : reducedValue; //对reduce的值进行二次处理
}
db.runCommand({
mapReduce:'goods',
map:map,
reduce:reduce,
finalize:finalize,
out:'res2'
})
# 对于price大于100的才进行分组映射
## 方法1:
var map = function(){
if(this.shop_price > 100){
emit(this.cat_id,{name:this.goods_name,price:this.shop_price});
}
}
var reduce = function(cat_id,goods_names){
return {cat_id:cat_id,goods_names:goods_names}
}
db.runCommand({
mapReduce:'goods',
map:map,
reduce:reduce,
out:'res2'
})
## 方法2 首推此方法
var map = function(){
emit(this.cat_id,{name:this.goods_name,price:this.shop_price});
}
var reduce = function(cat_id,goods_names){
return {cat_id:cat_id,goods_names:goods_names}
}
db.runCommand({
mapReduce:'goods',
map:map,
reduce:reduce,
query:{'shop_price':{$gt:100}},
out:'res2'
})
官网实例
# 数据结构
{
_id: ObjectId("50a8240b927d5d8b5891743c"),
cust_id: "abc123",
ord_date: new Date("Oct 04, 2012"),
status: 'A',
price: 25,
items: [ { sku: "mmm", qty: 5, price: 2.5 },
{ sku: "nnn", qty: 5, price: 2.5 } ]
}
# 计算每个顾客的总金额
var mapFunction1 = function() {
emit(this.cust_id, this.price);
};
var reduceFunction1 = function(keyCustId, valuesPrices) {
return Array.sum(valuesPrices);
};
db.orders.mapReduce(
mapFunction1,
reduceFunction1,
{ out: "map_reduce_example" }
)
# 计算订单总量和每种 sku 订购量的平均值
var mapFunction2 = function() {
for (var idx = 0; idx < this.items.length; idx++) {
var key = this.items[idx].sku;
var value = {
count: 1,
qty: this.items[idx].qty
};
emit(key, value);
}
};
var reduceFunction2 = function(keySKU, countObjVals) {
reducedVal = { count: 0, qty: 0 };
for (var idx = 0; idx < countObjVals.length; idx++) {
reducedVal.count += countObjVals[idx].count;
reducedVal.qty += countObjVals[idx].qty;
}
return reducedVal;
};
var finalizeFunction2 = function (key, reducedVal) {
reducedVal.avg = reducedVal.qty/reducedVal.count;
return reducedVal;
};
db.orders.mapReduce(
mapFunction2,
reduceFunction2,
{
out: { merge: "map_reduce_example" },
query: { ord_date:
{ $gt: new Date('01/01/2012') }
},
finalize: finalizeFunction2
}
)
【mongoDB高级篇②】大数据聚集运算之mapReduce(映射化简)的更多相关文章
- 【mongoDB高级篇③】综合实战(1): 分析国家地震数据
数据准备 下载国家地震数据 http://data.earthquake.cn/data/ 通过navicat导入到数据库,方便和mysql语句做对比 shard分片集群配置 # step 1 mkd ...
- java学习第13天( java获取当前时间,有关大数据的运算及精确数字运算,Date类)
一 java获取当前时间 学习一个函数,得到当前时间的准确值 System.currectTimeMillis(). 可以得到以毫秒为单位的当前时间.它主要用于计算程序运行时间,long start= ...
- 我眼中的大数据(三)——MapReduce
这次来聊聊Hadoop中使用广泛的分布式计算方案--MapReduce.MapReduce是一种编程模型,还是一个分布式计算框架. MapReduce作为一种编程模型功能强大,使用简单.运算内容不 ...
- 大数据计算的基石——MapReduce
MapReduce Google File System提供了大数据存储的方案,这也为后来HDFS提供了理论依据,但是在大数据存储之上的大数据计算则不得不提到MapReduce. 虽然现在通过框架的不 ...
- 大数据【四】MapReduce(单词计数;二次排序;计数器;join;分布式缓存)
前言: 根据前面的几篇博客学习,现在可以进行MapReduce学习了.本篇博客首先阐述了MapReduce的概念及使用原理,其次直接从五个实验中实践学习(单词计数,二次排序,计数器,join,分 ...
- 大数据开发实战:MapReduce内部原理实践
下面结合具体的例子详述MapReduce的工作原理和过程. 以统计一个大文件中各个单词的出现次数为例来讲述,假设本文用到输入文件有以下两个: 文件1: big data offline data on ...
- 大数据基石——Hadoop与MapReduce
本文始发于个人公众号:TechFlow 近两年AI成了最火热领域的代名词,各大高校纷纷推出了人工智能专业.但其实,人工智能也好,还是前两年的深度学习或者是机器学习也罢,都离不开底层的数据支持.对于动辄 ...
- 【mongoDB高级篇①】聚集运算之group,aggregate
group 语法 db.collection.group({ key:{field:1},//按什么字段进行分组 initial:{count:0},//进行分组前变量初始化,该处声明的变量可以在以下 ...
- 【mongoDB高级篇①】聚集运算之group与aggregate
group 语法 db.collection.group({ key:{field:1},//按什么字段进行分组 initial:{count:0},//进行分组前变量初始化,该处声明的变量可以在 ...
随机推荐
- 加载页面遮挡耗时操作任务页面--第三方开源--AndroidProgressLayout
在Android的开发中,往往有这种需求,比如一个耗时的操作,联网获取网络图片.内容,数据库耗时读写等等,在此耗时操作过程中,开发者也许不希望用户再进行其他操作(其他操作可能会引起逻辑混乱),而此时需 ...
- COUNT(*),count(1),COUNT(ALL expression),COUNT(DISTINCT expression)
创建一个测试表 IF OBJECT_ID( 'dbo.T1' , 'U' )IS NOT NULL BEGIN DROP TABLE dbo.T1; END; GO )); GO INSERT INT ...
- hdu 2256 Problem of Precision 构造整数 + 矩阵快速幂
http://acm.hdu.edu.cn/showproblem.php?pid=2256 题意:给定 n 求解 ? 思路: , 令 , 那么 , 得: 得转移矩阵: 但是上面求出来的并 ...
- 管理口令(P):[INS-30001] ADMIN口令为空之Oracle安装
在安装oracle database11g 发行版的时候出现下面这个问题. 无论怎么输入密码都提示有问题,都输入得鬼火了!去百度了一下,果然有命名规则的 规则如下:小写字母+数字+大写字母
- Linux 批量解压gz包
[root@yoon export]# vi gunzip.sh !/bin/bashpath=/export/backup ----备份文件目录路径 for i in `ls ${path}/*`d ...
- Python之回调魔法
Python中魔法(前后又下划线)会在对象的生命周期被回调. 借助这种回调, 可以实现AOP或者拦截器的思想. 在Python语言中提供了类似于C++的运算符重在功能:一下为Python运算符重在调用 ...
- PHP正则表达式的逆向引用与子模式 php preg_replace应用
mixed preg_replace ( mixed pattern, mixed replacement, mixed subject [, int limit]) 功能 在 subject 中搜索 ...
- UML 小结(5)- 图解 Rational Rose 的详细安装过程
在学习UML的时候,会用到画图工具:Rotional Rose . 原以为这款软件直接下载下来或者跟朋友那边拷过来就可以直接用了,结果却是没有那么简单,如果读者您也是为了解决这个家伙的安装问题的话,那 ...
- 【原创】书本翻页效果booklet jquery插件系列之简介
booklet jquery插件系列之简介 本文由五月雨恋提供,转载请注明出处. 一.安装 1.添加CSS和Javascript 添加booklet CSS文件到你的页面. <link rel= ...
- C语言标准库函数strcpy与strcmp的简单实现
//C语言标准库函数strcpy的一种简单实现. //返回值:目标串的地址. //对于出现异常的情况ANSI-C99标准并未定义,故由实现者决定返回值,通常为NULL. //参数:des为目标字符串, ...